txchmechanicus/hermes-agent-reasoning-traces
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/txchmechanicus/hermes-agent-reasoning-traces
下载链接
链接失效反馈官方服务:
资源简介:
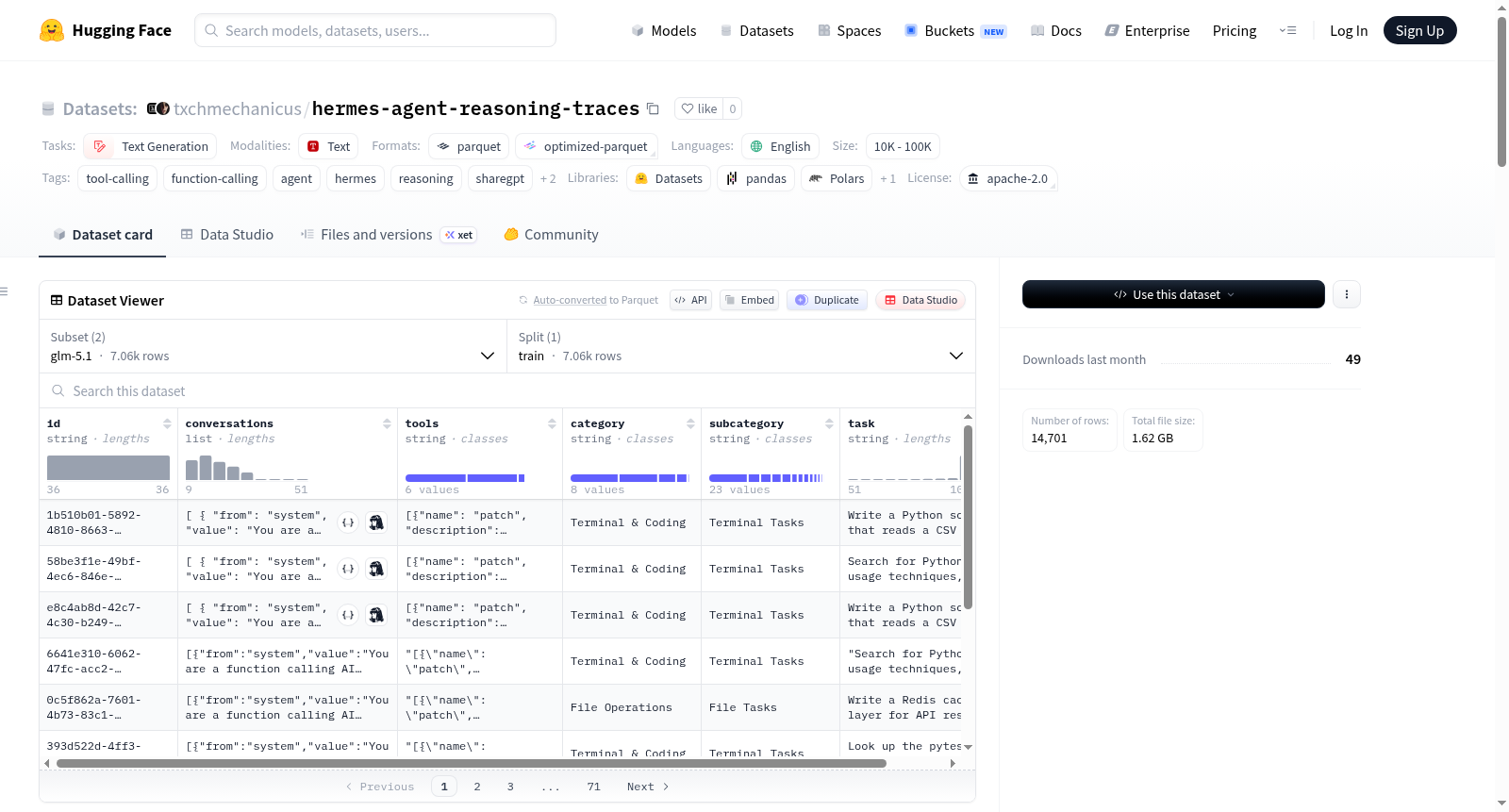
Hermes Agent Reasoning Traces数据集是一个用于训练AI代理的多轮工具调用轨迹数据集。每个样本都是真实的代理对话,包含逐步推理(`<think>`块)和实际工具执行结果。数据集有两个配置,分别对应不同的源模型:kimi(Moonshot AI Kimi-K2.5)和glm-5.1(ZhipuAI GLM-5.1-FP8)。数据集包含多轮对话、工具定义、任务类别和子类别等信息,对话消息使用ShareGPT格式。数据集涵盖了终端与编码、代理工具、仓库任务、浏览器自动化等多个类别,并提供了详细的统计信息和生成细节。
The Hermes Agent Reasoning Traces dataset is a collection of multi-turn tool-calling trajectories for training AI agents. Each sample is a real agent conversation with step-by-step reasoning (`<think>` blocks) and actual tool execution results. The dataset has two configs, one per source model: kimi (Moonshot AI Kimi-K2.5) and glm-5.1 (ZhipuAI GLM-5.1-FP8). It includes multi-turn dialogues, tool definitions, task categories, and subcategories, with conversation messages in ShareGPT format. The dataset covers various categories such as Terminal & Coding, Agent Tools, Repository Tasks, and Browser Automation, and provides detailed statistics and generation details.
提供机构:
txchmechanicus
搜集汇总
数据集介绍
构建方式
本数据集源自Hermes Agent框架,通过集成真实工具执行环境,采集多轮智能体对话轨迹。构建过程中,分别以Moonshot AI的Kimi-K2.5与ZhipuAI的GLM-5.1-FP8作为核心推理模型,借助vLLM推理引擎与专用工具调用解析器,在沙盒中执行终端命令、文件操作、浏览器自动化等任务。每条样本均包含完整的思考链(<think>块)、工具调用记录及其真实执行结果,而非合成数据。数据集提供kimi与glm-5.1两种配置,分别包含7,646条与7,055条高质量轨迹。
特点
数据集最显著的特征在于其深度与真实性:平均每样本对话轮次高达24.3(kimi配置)与19.1(glm-5.1配置),平均工具调用次数分别为13.9与9.7次,远超同类数据集。思考链详尽,kimi配置平均思考深度达414词,为复杂推理提供丰富语义锚点。覆盖9大任务类别,涵盖终端编码、智能体工具、浏览器自动化、仓库任务、多工具协同等真实应用场景,确保数据多样性与实用性。
使用方法
用户可通过HuggingFace Datasets库便捷加载,示例代码如下:
from datasets import load_dataset
ds = load_dataset("lambda/hermes-agent-reasoning-traces", "kimi", split="train")
每条样本采用ShareGPT格式存储,字段包括id、conversations(多轮对话)、tools(工具定义JSON)、category、subcategory及task描述,便于微调时直接解析。数据适用于训练具备工具调用与逐步推理能力的AI智能体,建议结合Hermes Agent框架进行模型微调与评估。
背景与挑战
背景概述
在人工智能代理(AI Agent)的研究领域,工具调用(tool-calling)与多轮交互推理能力是实现自主智能代理的核心挑战。尽管大语言模型在文本生成上取得了突破性进展,但在真实环境中执行复杂任务(如终端操作、浏览器自动化、代码仓库管理)时,仍面临推理步长与工具调用效率的鸿沟。2025年,Nous Research与Lambda合作推出了Hermes Agent Reasoning Traces数据集,旨在捕捉AI代理在真实工具执行环境中的完整交互轨迹。该数据集包含来自Kimi-K2.5和GLM-5.1两种模型的14701条样本,总计超过32万轮对话与17万次工具调用,覆盖终端编程、代理工具、浏览器自动化等九大任务类别。其独特价值在于保留了显性的逐步推理过程(<think>模块)与实际工具执行结果,为训练具有深度推理能力的自主代理提供了高质量的监督微调(SFT)数据,推动了代理模型从模拟响应到真实执行的跨越。
当前挑战
该数据集直面的领域挑战在于解决AI代理在真实环境中执行多步工具调用时的推理可靠性与效率瓶颈。传统基于模拟响应的训练数据缺乏真实环境反馈,导致模型在终端命令、文件操作、浏览器导航等场景中易产生错误调用或死循环。Hermes Agent Reasoning Traces通过记录真实工具执行结果(如命令输出、页面截图、仓库变更),迫使模型学习因果推理——即每次工具调用后的环境状态变化必须与下一推理步骤逻辑自洽。构建过程中,挑战源自异构模型的推理差异:Kimi-K2.5的深层推理(平均414词/思考块)与GLM-5.1的高效执行(仅70词/思考块)对数据格式的兼容性提出要求,同时平衡9类任务的样本分布(如浏览器自动化与计划组织类样本悬殊)。此外,大规模真实工具执行涉及计算开销(GLM-5.1需3节点8×H100集群)与安全风险(如执行未知代码),需设计严格的任务沙箱与失败回滚机制,确保数据采集的鲁棒性。
常用场景
经典使用场景
在智能体与工具调用领域,Hermes-Agent-Reasoning-Traces数据集为训练具备多轮工具调用能力的语言模型提供了高质量的轨迹数据。每个样本均记录了真实的智能体对话,包含逐步推理的思考过程(<think>块)以及实际工具执行的交互结果。该数据集尤其适用于监督微调场景中,通过模仿专家智能体的行为轨迹,使模型学会在复杂任务中合理调用工具、解析工具响应并调整推理策略,从而提升自主决策与任务完成效率。
实际应用
在实际应用中,该数据集训练出的模型可部署于各类自动化工作流,包括但不限于自动编写与调试脚本、基于Playwright的网页导航与数据抓取、文件系统操作及定时任务管理。企业级场景中,智能体可依据数据集中的轨迹模式,高效执行代码审查、仓库重构、测试生成等开发运维任务。此外,通过记忆持久化与任务委派机制,该数据集促进的模型能构建更稳健的个人助理系统,实现多步骤复杂方案的制定与执行。
衍生相关工作
该数据集衍生出的经典工作主要体现在Hermes Agent框架的迭代优化以及多模型推理范式研究上。基于Kimi-K2.5和GLM-5.1生成的轨迹,研究者提出了混合专家推理策略,并探索了长上下文窗口下工具调用的稀疏化方法。此外,该数据集催生了针对工具调用与思考链融合的专用损失函数设计,以及基于计划-执行-反思循环的强化学习方法。部分工作还将其作为基准,对比开源模型与闭源智能体在真实环境中的交互能力差异。
以上内容由遇见数据集搜集并总结生成


