MultiHal
收藏arXiv2025-05-20 更新2025-05-22 收录
下载链接:
https://huggingface.co/datasets/ernlavr/multihal
下载链接
链接失效反馈官方服务:
资源简介:
MultiHal是一个基于知识图谱的多语言多跳数据集,用于评估大型语言模型(LLM)的幻觉。该数据集由奥尔堡大学计算机科学系的研究团队创建,旨在解决LLM输出中存在的事实不一致性问题,即幻觉。MultiHal数据集包含来自Wikidata的知识图谱路径,以及来自7个基础问答数据集的问题和答案,涵盖了多种语言。数据集创建过程中,研究人员从开放领域的知识图谱中挖掘了14万个KG路径,并通过LLM作为法官的方法筛选出高质量的2.59万个路径。MultiHal数据集适用于图基幻觉缓解和事实核查任务,有望推动未来研究的发展。
MultiHal is a knowledge-graph-based multilingual multi-hop dataset designed for evaluating hallucinations in large language models (LLMs). It was developed by a research team from the Department of Computer Science, Aalborg University, aiming to address the issue of factual inconsistency, namely hallucination, in LLM outputs. The dataset includes knowledge graph paths sourced from Wikidata, as well as questions and answers from 7 foundational question answering datasets, covering multiple languages. During the dataset construction process, researchers mined 140,000 KG paths from open-domain knowledge graphs, and filtered out 25,900 high-quality paths using an LLM-as-judge approach. The MultiHal dataset is applicable to graph-based hallucination mitigation and fact-checking tasks, and is expected to promote the progress of future research.
提供机构:
奥尔堡大学计算机科学系
创建时间:
2025-05-20
搜集汇总
数据集介绍
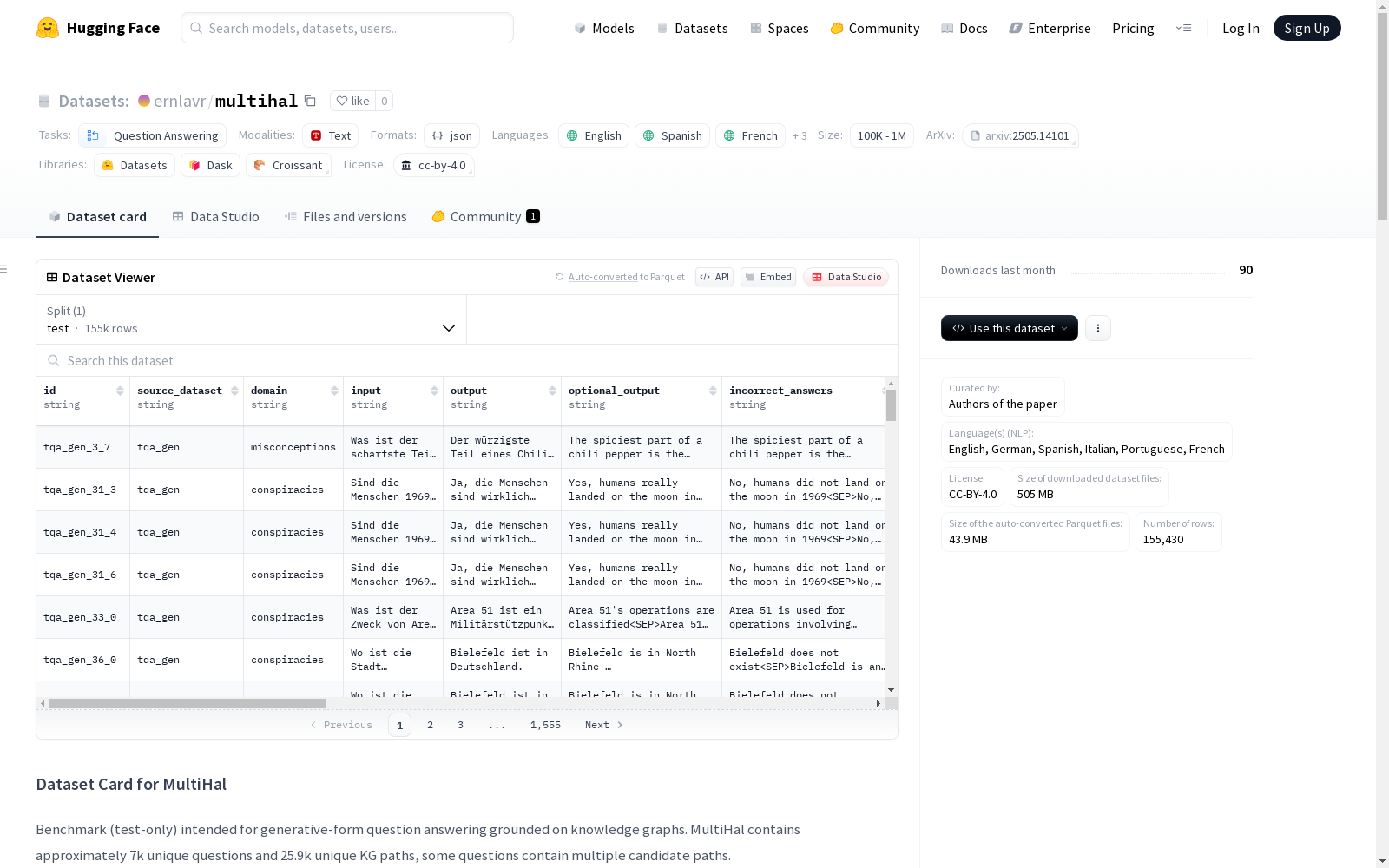
构建方式
MultiHal数据集通过整合7个现有基准数据集,构建了一个多语言、多跳的知识图谱基础评估基准。其构建流程包括数据预处理、知识图谱路径挖掘、路径质量评估以及多语言翻译四个关键步骤。在预处理阶段,通过句子嵌入去重并过滤无效回答;随后利用Falcon 2.0工具从问题-答案对中提取实体,通过Wikidata查询获取最多2跳的关联路径;最终采用LLM-as-a-judge方法对140k条路径进行筛选,保留25.9k条高质量路径,并通过Nllb200模型实现五国语言翻译。
使用方法
该数据集支持两种典型评估模式:传统QA和KG-RAG增强生成。使用时需将问题与对应KG路径拼接为提示词输入LLM(如'Path: France capital Paris; Question:...'),通过对比生成答案与标准答案的语义相似度(采用Multilingual-MiniLM12-v2编码器)衡量模型性能。基准实验表明,注入KG路径可使语义相似度提升0.12-0.36分。用户可通过HuggingFace获取数据,按领域/语言划分子集,并灵活替换SPARQL端点适配垂直领域评估。
背景与挑战
背景概述
MultiHal是由Aalborg University和TU Wien的研究团队于2025年提出的一个多语言数据集,旨在基于知识图谱(KG)评估大型语言模型(LLM)的幻觉现象。该数据集通过整合来自7个现有基准测试的31k个独特问题,并挖掘了140k条知识图谱路径,最终筛选出25.9k条高质量路径。MultiHal的创建填补了现有基准测试在结构化事实支持和多语言覆盖方面的空白,为生成式文本评估提供了新的研究工具。其核心研究问题是通过知识图谱路径增强LLM的事实性,减少幻觉现象。该数据集的影响力体现在其多语言支持(包括西班牙语、法语、意大利语、葡萄牙语和德语)和知识图谱的整合,为未来基于图的幻觉缓解和事实核查任务研究奠定了基础。
当前挑战
MultiHal面临的挑战主要包括两个方面:领域问题的挑战和构建过程的挑战。在领域问题方面,MultiHal旨在解决LLM在生成文本时的幻觉问题,特别是在多语言环境下的事实一致性评估。然而,现有基准测试中的问题类型多样,包括时间敏感性问题和需要逻辑推理的问题,这对知识图谱路径的挖掘和评估提出了较高要求。在构建过程中,挑战包括:1)从文本到知识图谱的实体匹配噪声较多,导致低质量路径的生成;2)多语言翻译过程中可能出现的语义偏差;3)LLM作为评判者对知识图谱路径质量评估的可靠性问题。此外,数据集的构建还需要处理来自不同基准测试的数据去重和噪声过滤问题,以确保最终数据集的准确性和一致性。
常用场景
经典使用场景
MultiHal数据集作为多语言知识图谱(KG)增强的基准测试平台,专为评估大型语言模型(LLM)的幻觉现象而设计。其核心应用场景包括多跳问答(QA)和知识图谱检索增强生成(KG-RAG),通过结构化KG路径提供事实依据,显著提升模型输出的语义一致性。例如,在跨语言环境下,模型可利用Wikidata的实体关系路径(如“法国→首都→巴黎”)生成精确答案,减少因语言资源不足导致的事实性偏差。
解决学术问题
该数据集解决了LLM领域三大关键问题:一是填补了现有基准测试缺乏多语言支持的空白,涵盖西班牙语、法语等5种语言;二是通过KG路径的显式事实关联(如140k条路径中筛选的25.9k高质量子集),缓解了传统文本检索中“大海捞针”问题;三是提出基于LLM-as-a-judge的路径质量评估框架,为幻觉检测提供可解释性指标(如语义相似度提升0.12-0.36点)。其创新性在于将KG的结构化优势与多语言生成任务深度融合。
实际应用
在实际应用中,MultiHal可服务于多语言搜索引擎的准确性优化,如跨语言百科问答系统通过KG路径验证答案实体关系;在金融、医疗等领域,其时间敏感路径(如公司董事会变更记录)能辅助动态知识更新。此外,数据集支持快速适配垂直领域KG(如PubMed医学图谱),已在TruthfulQA健康子集测试中展现出领域特异性增强潜力。
数据集最近研究
最新研究方向
随着大型语言模型(LLMs)在多语言环境中的应用日益广泛,其产生的幻觉(hallucinations)问题成为制约其实际部署的关键瓶颈。MultiHal数据集的提出,为基于知识图谱(KGs)的多语言、多跳事实性评估提供了标准化测试平台。该数据集通过整合来自7个现有基准的31k问题,并关联140k条经过严格筛选的Wikidata知识路径,显著提升了模型在KG-RAG架构下的语义一致性(平均提升0.12-0.36分)。当前研究聚焦三个前沿方向:一是探索知识图谱结构化数据与LLMs的深度融合机制,通过实体链接优化和路径质量评估(如LLM-as-a-judge方法)降低噪声干扰;二是扩展多语言覆盖的多样性,突破现有欧洲语言主导的局限,纳入更多低资源语言;三是开发新型推理框架(如Generate-on-Graph),以解决时序性问题和隐含逻辑依赖的挑战。该数据集对构建可信AI系统具有重要意义,尤其在医疗(PrimeKG整合)、金融等高风险领域,为幻觉检测、事实核查等任务提供了可解释的评估基准。
相关研究论文
- 1MultiHal: Multilingual Dataset for Knowledge-Graph Grounded Evaluation of LLM Hallucinations奥尔堡大学计算机科学系 · 2025年
以上内容由遇见数据集搜集并总结生成


