Dolci-RLZero-IF-7B
收藏Hugging Face2025-11-20 更新2025-11-21 收录
下载链接:
https://huggingface.co/datasets/allenai/Dolci-RLZero-IF-7B
下载链接
链接失效反馈官方服务:
资源简介:
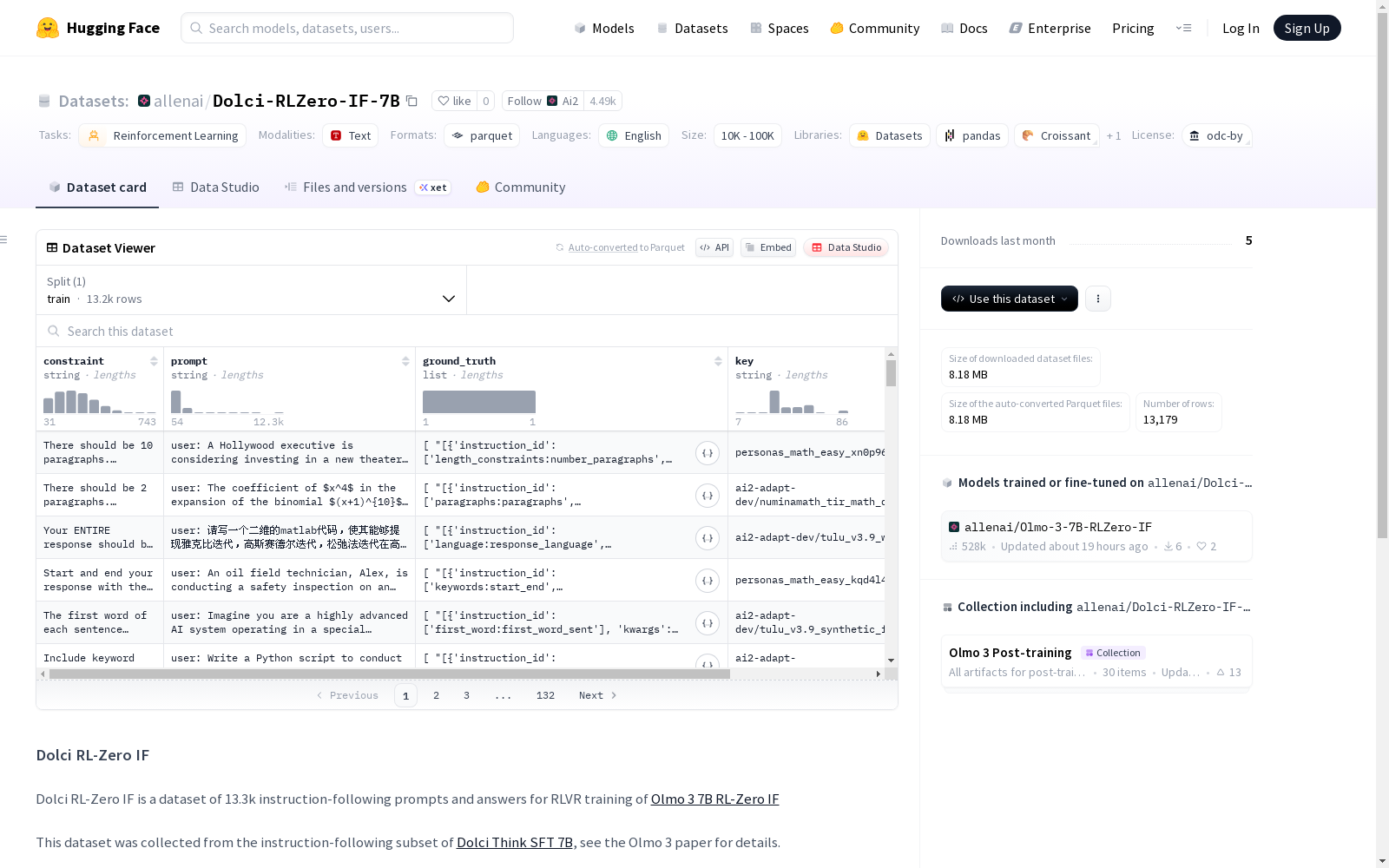
Dolci RL-Zero IF是一个包含13.3k指令跟随提示和答案的数据集,用于RLVR训练Olmo 3 7B RL-Zero IF模型。数据集包含了约束(constraint)、提示(prompt)、地面真实(ground_truth,为字符串列表)和关键字(key)四个字段。它适用于强化学习任务,并完全以英语为语言环境。
提供机构:
Allen Institute for AI
创建时间:
2025-11-18
原始信息汇总
Dolci RL-Zero IF 数据集概述
数据集基本信息
- 数据集名称: Dolci RL-Zero IF
- 创建者: AllenAI
- 许可证: ODC-BY
- 语言: 英语
数据集规模
- 训练集样本数量: 13,179
- 训练集大小: 18,909,249字节
- 下载大小: 8,183,336字节
数据特征
数据集包含以下字段:
- constraint: 字符串类型
- prompt: 字符串类型
- ground_truth: 字符串列表
- key: 字符串类型
用途说明
- 主要用途: 用于RLVR训练
- 目标模型: Olmo 3 7B RL-Zero IF
- 数据来源: 基于Dolci Think SFT 7B数据集的指令遵循子集
下载方式
可通过HuggingFace的datasets库下载: python from datasets import load_dataset dataset = load_dataset("allenai/dolci-rlzero-if-7b", split="train")
使用限制
- 使用范围: 研究和教育用途
- 使用准则: 需遵守Ai2的负责任使用指南
搜集汇总
数据集介绍
构建方式
在强化学习研究领域,数据质量直接决定模型性能的上限。Dolci-RLZero-IF-7B数据集源自Dolci Think SFT 7B中的指令遵循子集,通过精心筛选形成包含1.3万条指令-响应对的标准化语料。构建过程严格遵循Olmo 3技术文档规范,每条数据均包含约束条件、提示文本、真实答案及唯一标识符四维特征,为强化学习与价值对齐研究提供了结构化基础。
特点
该数据集最显著的特征在于其多维数据结构设计,每个样本均包含约束描述、任务提示、标准答案集合和唯一键值。这种架构特别适合训练具有价值对齐能力的语言模型,13.3k条高质量样本覆盖了丰富的指令遵循场景。数据采用纯英文编写且经过严格校验,确保语义一致性与逻辑完整性,为RLVR训练提供了可靠的基础设施。
使用方法
研究人员可通过HuggingFace生态系统快速部署该数据集,使用datasets库的load_dataset函数即可加载完整训练集。加载后的数据可直接接入Olmo-3-7B-RLZero-IF等模型进行强化学习训练,其标准化的字段结构便于实现约束条件解析与多轮对话建模。根据ODC-BY许可协议,该数据集限研究教育用途,使用者应遵循Ai2责任使用准则开展实验。
背景与挑战
背景概述
随着强化学习与自然语言处理领域的深度融合,指令跟随任务成为评估模型交互能力的重要基准。Dolci-RLZero-IF-7B数据集由艾伦人工智能研究所于2024年构建,旨在为Olmo-3-7B-RLZero-IF模型提供强化学习价值回归训练支持。该数据集基于Dolci-Think-SFT-7B的指令跟随子集精炼而成,包含1.3万条结构化提示与答案对,通过约束条件、真实反馈等多维度特征,推动语言模型在复杂指令理解与执行方面的研究进程。
当前挑战
在强化学习驱动的指令跟随领域,模型需克服多轮对话中的长期依赖与动态策略优化难题。Dolci-RLZero-IF-7B构建过程中面临数据质量控制的挑战,包括从原始SFT数据筛选指令跟随样本时的语义一致性校验,以及确保约束条件与真实答案的逻辑对齐。此外,需平衡提示的多样性与训练稳定性,避免强化学习训练中的奖励稀疏问题,同时维持生成内容与人类价值观的契合度。
常用场景
经典使用场景
在强化学习与自然语言处理交叉领域,Dolci-RLZero-IF-7B数据集通过13.3千条指令遵循样本,为语言模型的强化学习价值回归训练提供了标准化实验环境。其结构化提示与真实答案对,能够系统评估模型在复杂指令理解与执行任务中的泛化能力,成为验证指令跟随算法性能的核心基准。
实际应用
在实际部署场景中,该数据集支撑的模型可应用于智能客服系统与自动化文档处理流程。经过强化学习调优的模型能够准确解析用户复杂指令,在医疗咨询、法律文书生成等高风险领域实现安全可靠的交互,大幅降低人工干预成本并提升服务效率。
衍生相关工作
基于该数据集衍生的Olmo-3-7B-RLZero-IF模型开创了指令遵循的新范式,后续研究在此基础上发展了多模态指令理解框架。相关成果推动了宪法人工智能、安全对齐技术等方向的发展,为构建负责任的人工智能系统提供了重要技术支撑。
以上内容由遇见数据集搜集并总结生成


