myrkur/persian-dpo
收藏Hugging Face2024-05-28 更新2024-06-15 收录
下载链接:
https://hf-mirror.com/datasets/myrkur/persian-dpo
下载链接
链接失效反馈官方服务:
资源简介:
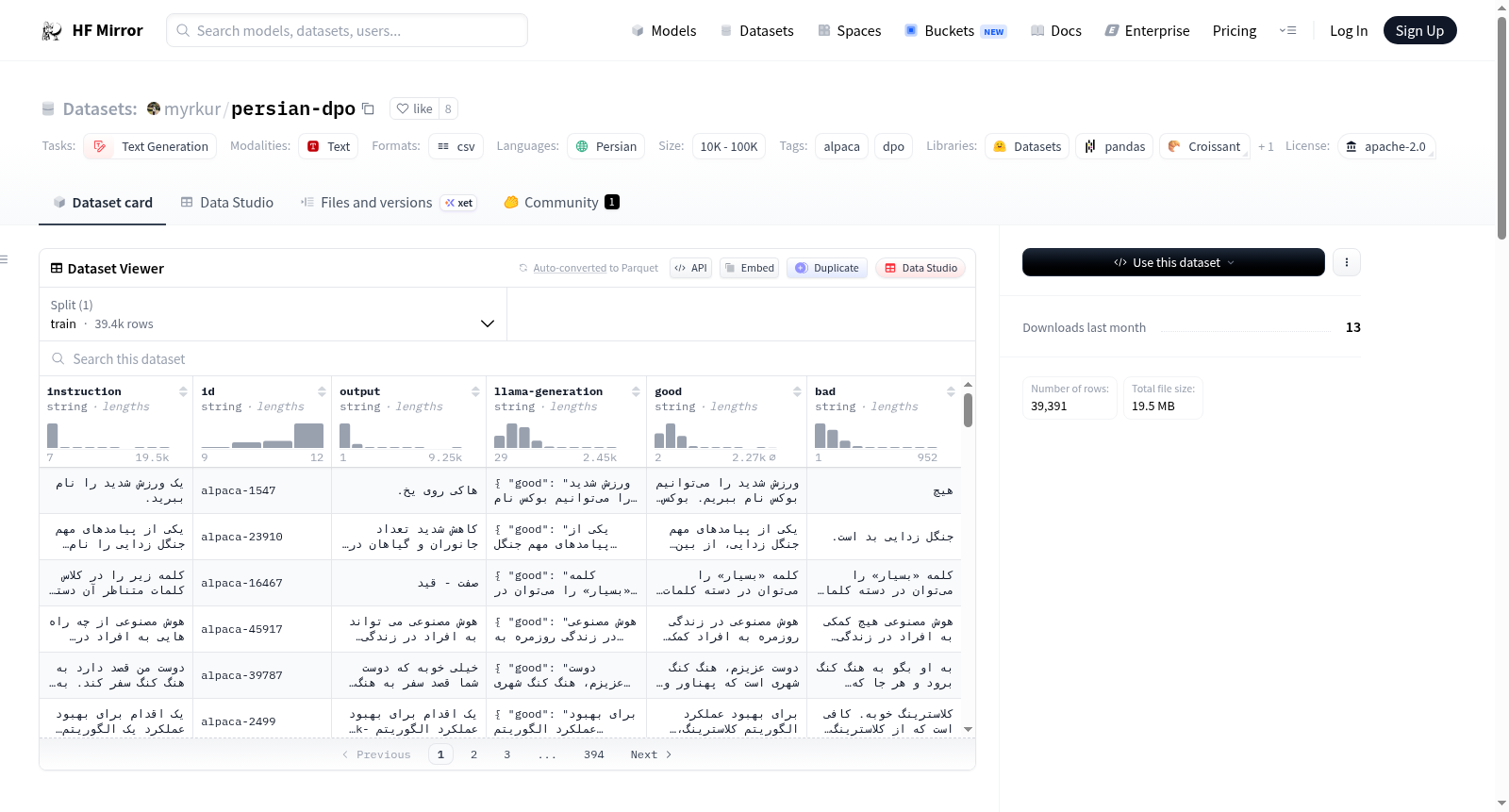
该存储库包含原始Alpaca数据集的波斯语翻译,以及使用LLama3 70B模型生成的额外偏好数据。该数据集已准备好用于使用直接偏好优化(DPO)或类似方法进行语言模型对齐。它包含大约39,000条波斯语记录。原始Alpaca数据集是用于训练和评估语言模型的文本数据集合,包含多样且全面的文本片段,适用于自然语言处理任务。原始Alpaca数据集已被精心翻译成波斯语,以支持波斯语处理任务和研究。使用LLama3 70B模型生成的偏好数据有助于语言模型对齐,帮助微调语言模型以更好地理解和生成基于用户偏好的文本。每个记录包括:`instruction`(翻译成波斯语的原始Alpaca提示)、`id`(记录的唯一标识符)、`output`(ChatGPT对提示的波斯语响应)、`llama-generation`(Llama3 70B生成的偏好数据)、`good`(Llama3 70B偏好的响应)、`bad`(Llama3 70B不偏好的响应)。
This repository contains the Persian translation of the original Alpaca dataset, along with additional preference data generated using the LLama3 70B model. This dataset is ready for language model alignment via Direct Preference Optimization (DPO) or similar methods, and includes approximately 39,000 Persian-language records.
The original Alpaca dataset is a collection of textual data used for training and evaluating language models, featuring diverse and comprehensive text snippets suitable for natural language processing (NLP) tasks. The original Alpaca dataset has been meticulously translated into Persian to support Persian-language NLP tasks and related research.
The preference data generated by the LLama3 70B model facilitates language model alignment, aiding in the fine-tuning of language models to better comprehend and generate text aligned with user preferences.
Each record includes the following fields:
`instruction`: The original Alpaca prompt translated into Persian
`id`: The unique identifier of the record
`output`: The Persian response from ChatGPT to the prompt
`llama-generation`: Preference data generated by the Llama3 70B model
`good`: The response preferred by Llama3 70B
`bad`: The response not preferred by Llama3 70B
提供机构:
myrkur
原始信息汇总
Persian Alpaca Preference Dataset
数据集描述
原始Alpaca数据集
Alpaca数据集是一个用于训练和评估语言模型的文本数据集合。它包含多样化和全面的文本片段,适用于自然语言处理任务。
波斯语翻译
原始的Alpaca数据集已被精心翻译成波斯语,以支持波斯语处理任务和研究。
偏好数据集
使用LLama3 70B模型生成了偏好数据,以促进语言模型对齐。这部分数据集有助于微调语言模型,使其更好地理解和根据用户偏好生成文本。
每个记录包括:
instruction: 原始Alpaca提示翻译成波斯语。id: 记录的唯一标识符。output: chatgpt对提示的波斯语响应。llama-generation: Llama3 70B生成的偏好数据。good: Llama3 70B偏好的响应。bad: Llama3 70B不偏好的响应。
使用
该数据集可用于多种自然语言处理任务,包括但不限于:
- 语言模型训练和微调
- 文本生成
- 情感分析
研究人员和开发者可以使用此数据集来提高其模型在波斯语处理能力,特别是在用户偏好起关键作用的对齐任务中。
搜集汇总
数据集介绍
构建方式
在波斯语自然语言处理领域,数据资源的丰富性对模型性能至关重要。该数据集以原始Alpaca数据集为基础,通过严谨的人工翻译流程将其内容转化为波斯语,确保了语言表达的准确性与文化适应性。随后,借助LLama3 70B大语言模型,针对每条翻译后的指令生成了多组响应,并依据模型自身的偏好判断机制,标注了“优质”与“劣质”回应,从而构建出一个适用于直接偏好优化(DPO)等对齐方法的、包含约3.9万条记录的高质量偏好数据集。
特点
本数据集的核心特征在于其专为波斯语模型对齐任务而设计的多维结构。每条数据记录不仅包含翻译自Alpaca的波斯语指令及其对应响应,还额外提供了由LLama3 70B模型生成的对比选项,明确区分了被偏好与不被偏好的回答。这种结构使得数据集超越了传统的指令-响应对,直接嵌入了人类或模型的价值判断,为训练模型理解并遵循复杂偏好提供了直接支持。其规模适中,覆盖多样化的文本生成场景,是波斯语NLP研究中稀缺的、可直接用于偏好学习的资源。
使用方法
研究人员与开发者可将此数据集直接应用于波斯语大语言模型的微调与对齐任务。具体而言,在直接偏好优化(DPO)等训练框架下,利用数据中的指令、优质回应与劣质回应对,可以有效地引导模型学习生成更符合特定偏好的文本。此外,数据集也可用于常规的波斯语文本生成模型训练、指令遵循能力评估,乃至作为情感分析等下游任务的补充语料。通过Hugging Face平台加载该数据集后,用户可便捷地提取所需字段,集成到现有的模型训练流程之中。
背景与挑战
背景概述
在自然语言处理领域,针对低资源语言的模型对齐研究日益受到重视。波斯语作为全球重要的语言之一,其数字资源相对匮乏,制约了相关人工智能技术的发展。在此背景下,myrkur/persian-dpo数据集应运而生,由研究人员Amir Masoud Ahmadi和Sahar Mirzapour等人于近期创建。该数据集基于著名的Alpaca数据集进行波斯语翻译,并利用LLama3 70B模型生成了偏好数据,专门用于支持基于直接偏好优化等方法的语言模型对齐研究。其核心研究问题聚焦于提升波斯语语言模型在理解与生成任务中遵循人类偏好的能力,为波斯语自然语言处理社区提供了宝贵的资源,推动了多语言人工智能技术的均衡发展。
当前挑战
该数据集旨在解决波斯语语言模型对齐这一领域核心问题,其挑战主要体现在两个方面。在领域问题层面,波斯语作为形态丰富、语序灵活的语言,构建能够准确捕捉人类偏好的高质量对齐数据面临巨大困难,模型需克服文化语境差异与语言结构复杂性带来的理解偏差。在构建过程层面,数据集的创建涉及从原始Alpaca数据集的精准翻译到利用大模型生成可靠偏好对的多个环节,确保翻译的语义保真度与偏好标注的一致性成为关键挑战,同时还需应对大规模数据清洗与验证所带来的资源消耗问题。
常用场景
经典使用场景
在波斯语自然语言处理领域,myrkur/persian-dpo数据集为语言模型的对齐与优化提供了关键资源。该数据集最经典的使用场景在于支持基于直接偏好优化(DPO)方法的模型微调,通过包含约3.9万条波斯语指令-响应对及偏好标注,使研究者能够训练模型区分高质量与低质量生成内容,从而提升模型在遵循人类偏好方面的性能。
解决学术问题
该数据集有效解决了波斯语大语言模型对齐研究中数据稀缺的核心问题。通过提供大规模、结构化的偏好数据,它支持对模型输出进行细粒度评估与优化,促进了跨语言对齐技术的迁移与应用。其意义在于为波斯语社区建立了首个系统性的偏好基准,推动了低资源语言在人工智能伦理与可控生成方面的学术探索。
衍生相关工作
围绕该数据集,已衍生出多项经典工作,如基于同一团队开发的Shotor与Paya等指令微调模型。这些工作进一步扩展了波斯语模型的能力边界,并在文本生成、情感分析等任务中验证了偏好数据的有效性。相关研究亦促进了跨语言对齐框架的改进,为多语言AI治理提供了实践案例。
以上内容由遇见数据集搜集并总结生成


