ChineseIsEasy
收藏Hugging Face2026-01-26 更新2026-01-27 收录
下载链接:
https://huggingface.co/datasets/AxelDlv00/ChineseIsEasy
下载链接
链接失效反馈官方服务:
资源简介:
ChineseIsEasy多模态词汇数据集是一个大规模的中法双语语言资源,专为机器学习、自然语言处理研究和高级Anki卡片生成设计。数据集包含28,354个独特的中文词条(单词和短语),按频率排序。核心数据包括简体/繁体汉字、拼音(带声调)和法语释义(经过LLM优化)。统计数据来自SUBTLEX-CH语料库,包括Zipf频率、词频计数和对数转换指标。每个词条都配有例句及对应的法语翻译和拼音。多模态部分包括高质量的自然语音(单词和句子)和语义插图(用于触发主动回忆)。数据集结构清晰,包含元数据、训练数据、音频文件和图像文件,每种媒体类型都有特定的格式和用途。音频采用分层策略,优先使用高质量人类录音,并辅以AI生成的多样化声音。图像设计为“语义锚点”,原始图像保存为PNG格式以保留细节,优化后的图像为JPG格式,适合闪卡应用。数据集采用CC BY 4.0许可,词汇基础来自CC-CEDICT,频率统计基于SUBTLEX-CH。
创建时间:
2026-01-25
原始信息汇总
ChineseIsEasy 多模态词汇数据集概述
数据集基本信息
- 名称: ChineseIsEasy Multimodal Lexical Dataset
- 语言: 中文 (zh)、法语 (fr)
- 许可证: CC BY 4.0
- 数据规模: 10n<100n
- 任务类别: 文本到语音、文本到图像、翻译
- 数据集大小: 23,307,116,600 字节
- 下载大小: 8,009,316,175 字节
- 条目数量: 28,354 个唯一中文词条
- 数据格式: Parquet
- 数据分割: 训练集 (train)
核心内容与特征
- 核心数据: 包含简体/繁体汉字、拼音(带声调)及法语释义。
- 频率统计: 提供基于 SUBTLEX-CH 语料库的 Zipf 频率、词频计数及对数转换指标。
- 上下文信息: 每个词条均配有例句及对应的法语翻译和拼音。
- 多模态数据:
- 自然音频: 为单词和句子提供高保真语音。
- 视觉图像: 生成用于触发主动回忆的语义插图。
数据结构字段
数据集包含以下主要字段:
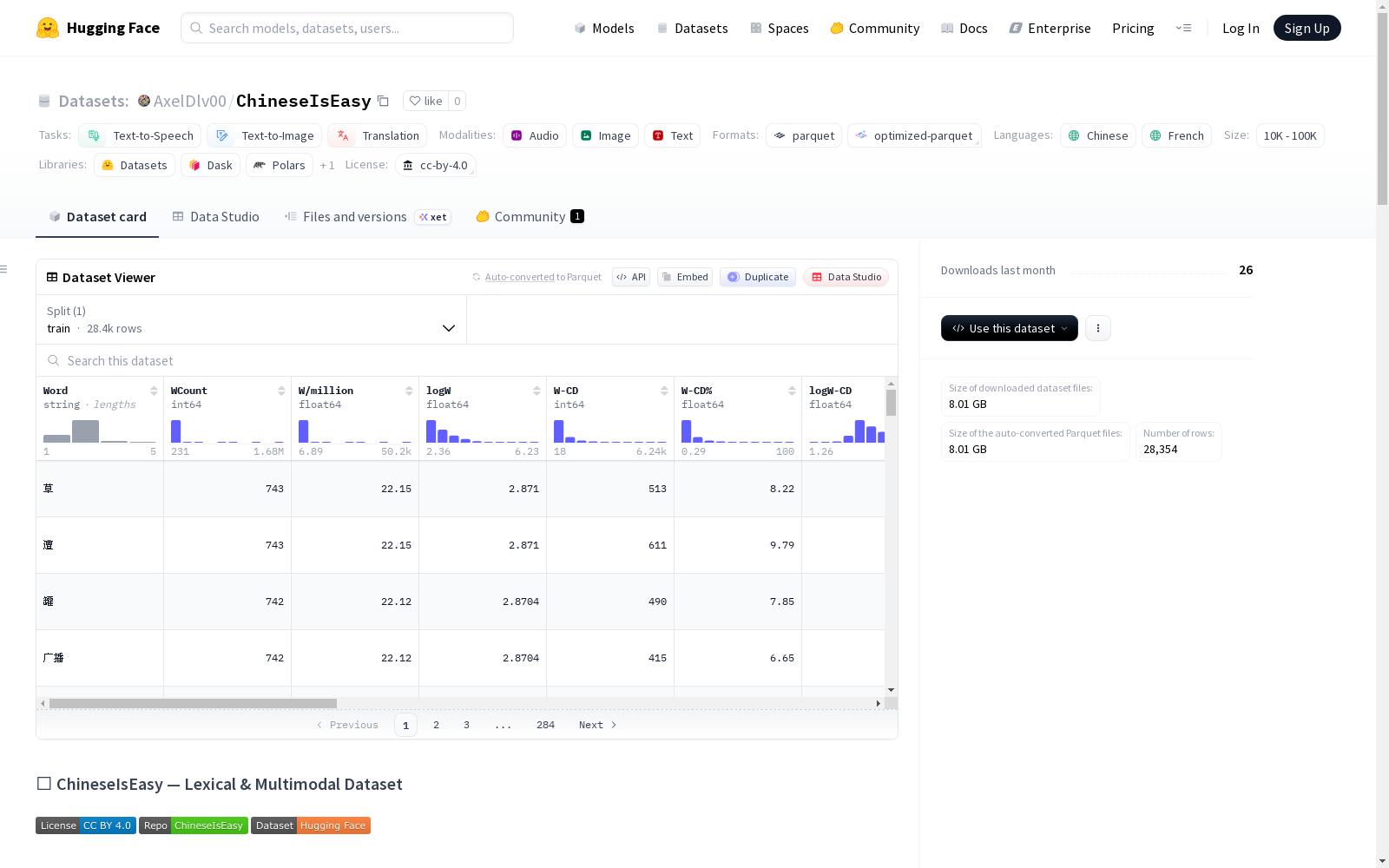
Word: 单词 (字符串)WCount: 词频计数 (整数)W/million: 每百万词频 (浮点数)logW: 词频对数 (浮点数)W-CD: 词频-字幕分布 (整数)W-CD%: 词频-字幕分布百分比 (浮点数)logW-CD: 词频-字幕分布对数 (浮点数)infos: 结构体,包含拼音列表、词义列表、简体、繁体字段。Traditionnel: 繁体字 (字符串)Pinyin: 拼音 (字符串)Signification: 释义 (字符串)Catégorie: 词类 (字符串)Exemples: 例句 (字符串)Explication: 解释 (字符串)hf_img_orig: 原始图像hf_img_optim: 优化图像hf_audio_word: 单词音频,采样率 16000 Hzhf_examples_json: 示例 JSON (字符串)
文件与目录结构
数据集遵循清晰、解耦的架构。主要文件及目录如下:
metadata.parquet train.parquet audio/ words/ examples/ original_wav/ optimized_mp3/ images/ original_png/ optimized_jpg/
每个媒体文件夹包含一个 mapping.csv 文件,用于将短 SHA-1 哈希值映射回原始文本。
生成流程
数据通过混合流程生成:
- 语言丰富化: 通过 GPT-4o-mini 进行批处理,生成教学类别、自然例句和深度语法解释。
- 视觉语义生成:
- GPT-4o-mini 作为“提示工程师”描述单词含义。
- Juggernaut XL v9 (SDXL) 在本地生成图像。
- 释义精炼: 使用专门的 LLM 提示,将原始英语词典 (CC-CEDICT) 内容翻译并重新格式化为清晰的法语教学内容。
音频策略
采用分层音频方法以确保学习效率:
- 单词: 优先使用高质量男性人声录音 (CC-CEDICT-TTS),按拼音命名以处理同形异义词。备用方案为通过压缩的 gTTS (Google Cloud) 生成,比特率为 24kbps。
- 句子: 使用 VoxCPM-0.5B (OpenBMB) 生成。为避免机器人般的单调,使用来自
ST-CMDS语料库的 16 种不同的高质量参考声音进行多样化克隆。 - 格式: 同时提供
WAV(用于存档/机器学习) 和MP3(用于 Anki/移动设备) 格式。
图像架构
每张图像均设计为“语义锚点”。
- 原始图像: 存储为
PNG(768x768),以保留 Juggernaut XL 模型的生成细节。 - 优化图像: 存储为
JPG(256x256),使用 Lanczos 重采样。这些图像已为抽认卡应用做好准备,在视觉清晰度和同步速度之间取得平衡。
使用方式
通过 Hugging Face Datasets 加载
python from datasets import load_dataset ds = load_dataset("AxelDlv00/ChineseIsEasy") entry = ds[train][0] print(f"Hanzi: {entry[Word]} | Freq: {entry[WCount]}") print(f"Audio Path: {entry[hf_audio_word]}")
直接下载
可通过克隆仓库访问原始文件: bash git lfs install git clone https://huggingface.co/datasets/AxelDlv00/ChineseIsEasy
许可证与来源
- 数据集内容: 基于 CC BY 4.0 许可发布。
- 词汇基础: 衍生自 CC-CEDICT (知识共享 署名-相同方式共享 3.0 许可)。
- 频率统计: 基于 SUBTLEX-CH。
作者
Axel Delaval (陈安思)
搜集汇总
数据集介绍
构建方式
在汉语作为第二语言教学领域,构建高质量的多模态学习资源至关重要。ChineseIsEasy数据集通过一套精密的混合生成流程得以构建:其核心词汇条目源自权威的CC-CEDICT词典和SUBTLEX-CH词频语料库,并在此基础上进行了深度的语言学增强。利用GPT-4o-mini模型对每个词条进行批处理,生成了教学分类、自然例句和语法解释。视觉内容则由Juggernaut XL v9模型根据精心设计的语义提示生成图像,而音频部分则融合了高质量的人类录音与VoxCPM-0.5B合成的多样化语音,最终整合为一个结构清晰、包含文本、图像与音频的统一资源。
特点
该数据集作为面向机器学习和语言教学的资源,展现出鲜明的多模态与教学导向特征。它收录了28,354个按词频排序的独特汉语词条,每个条目均整合了简体与繁体汉字、拼音、法语释义及丰富的上下文例句。其核心特点在于超越了传统的文本数据,为每个词条配备了旨在触发主动回忆的语义插画,以及包含单词和例句的高保真自然语音。数据集结构经过精心设计,将原始媒体文件与优化后的版本分离存储,并提供了从词频统计到对数转换指标在内的详细语言学元数据,确保了其在研究与应用中的高度可用性。
使用方法
对于自然语言处理与教育技术的研究者而言,该数据集提供了便捷的访问途径。用户可通过Hugging Face的`datasets`库直接加载数据集,轻松访问词条及其关联的多模态文件路径,例如音频和图像。对于需要原始文件的应用场景,如构建个性化学习系统或移动端应用,数据集支持通过Git LFS进行完整克隆,从而获取结构化的媒体文件夹。数据集中包含的优化后JPG格式图像与MP3格式音频已为闪卡类应用做好了准备,而PNG与WAV格式则保留了原始细节,适用于进一步的机器学习模型训练或分析。
背景与挑战
背景概述
ChineseIsEasy数据集作为一项多模态汉语学习资源,由Axel Delaval(陈安思)于近年构建并发布,依托HuggingFace平台进行开源共享。该数据集整合了SUBTLEX-CH语料库的词频统计、CC-CEDICT词典的词汇释义,以及通过先进生成式人工智能技术合成的视觉图像与语音音频,旨在为机器学习和自然语言处理研究提供丰富的汉语-法语双语对照素材。其核心研究问题聚焦于如何通过多模态数据融合提升汉语作为第二语言的学习效率,尤其在词汇记忆与语义理解方面,为教育技术、跨语言信息检索及智能辅导系统等领域提供了重要的数据基础。
当前挑战
在解决汉语作为外语学习的领域问题中,该数据集面临词汇语义多义性处理、跨语言对齐准确性以及多模态数据协同表征等挑战。构建过程中,需克服大规模高质量语音合成中自然度与多样性的平衡,例如利用VoxCPM-0.5B模型结合多参考音色以规避机械单调;同时,图像生成需确保语义锚定效果,通过Juggernaut XL v9模型实现视觉提示与词汇含义的精确匹配。此外,数据整合涉及复杂管道设计,包括LLM驱动的释义优化、频率指标对数转换以及媒体文件哈希映射,这些环节均对计算资源与算法鲁棒性提出较高要求。
常用场景
经典使用场景
在自然语言处理与计算语言学领域,ChineseIsEasy数据集为汉语词汇的多模态表征研究提供了重要支撑。该数据集整合了频率统计、语义图像与高保真音频,常被用于构建跨语言词汇学习模型,特别是在机器翻译与文本到语音合成任务中,研究者利用其丰富的标注信息训练深度神经网络,以提升模型对汉语词汇的语义理解与生成能力。
实际应用
在实际应用中,ChineseIsEasy数据集被广泛集成于智能教育工具与语言学习平台,例如基于Anki的自适应闪卡系统。通过结合视觉语义锚点与自然发音音频,该数据集能够增强学习者的词汇记忆效率,并为个性化教学内容的生成提供数据基础,从而在汉语作为第二语言的教学实践中发挥关键作用。
衍生相关工作
围绕该数据集衍生的经典工作包括多模态词汇嵌入模型的开发,如融合图像与音频特征的跨语言词向量表示方法。此外,基于其频率统计与例句语料,研究者构建了面向汉语习得的序列到序列生成模型,这些工作进一步拓展了数据驱动语言教学与自适应学习系统的研究边界。
以上内容由遇见数据集搜集并总结生成


