genomic-bioimaging
收藏Hugging Face2025-10-27 更新2025-10-28 收录
下载链接:
https://huggingface.co/datasets/stefanches/genomic-bioimaging
下载链接
链接失效反馈官方服务:
资源简介:
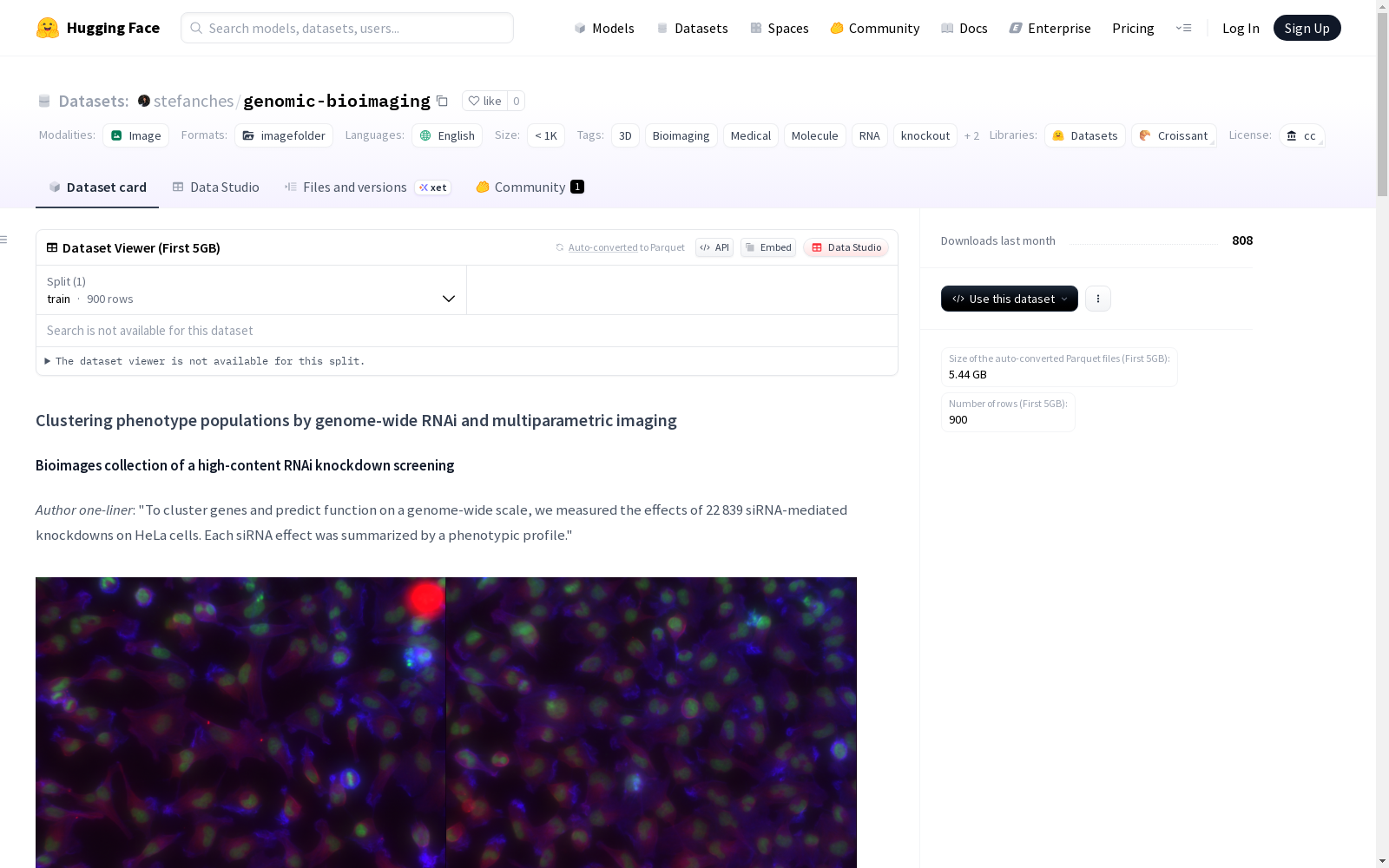
这是一个通过全基因组RNAi筛选和多重参数成像对表型群体进行聚类的研究数据集。该数据集包含了在人类细胞中进行全基因组RNAi筛选的结果,使用高吞吐量成像得到的定量描述符来生成多重参数表型轮廓。通过表型相似性,这些轮廓可以预测基因的功能。数据集由 Dundee大学整理,并由多个资助机构支持。
创建时间:
2025-10-22
原始信息汇总
数据集概述
基本信息
- 数据集名称:Clustering phenotype populations by genome-wide RNAi and multiparametric imaging
- 数据集类型:生物成像数据
- 数据格式:16位PNG图像、CSV表格、JSON-LD对象
- 数据规模:10M-100M
- 语言:英语
- 许可证:CC BY-NC-ND 4.0
研究背景
- 研究目的:通过表型相似性聚类基因并预测功能
- 实验方法:对HeLa细胞进行22,839次siRNA介导的基因敲除,通过高通量成像生成多参数表型谱
- 应用价值:发现新基因功能,探索功能关系,预测生物学过程和功能
数据来源
- 数据生产者:Florian Fuchs, Gregoire Pau, Dominique Kranz, Oleg Sklyar, Christoph Budjan, Sandra Steinbrink, Thomas Horn, Angelika Pedal, Wolfgang Huber, Michael Boutros
- 数据管理:University of Dundee
- 资金来源:BBSRC、Euro-BioImaging、Global BioImaging Project、CORBEL、Wellcome Trust
数据存储
- 主要存储库:IDR、Bioimage Archive
- 原始论文:https://doi.org/10.1038/msb.2010.25
- 实验信息:https://uk1s3.embassy.ebi.ac.uk/bia-integrator-data/pages/S-BIAD845.html
数据结构
- 组织结构:遵循OMERO的高内涵筛选结构(屏幕-板-孔)
- 图像格式:从OME-Zarr转换的16位PNG
- 元数据格式:CSV表格和JSON-LD对象
- 注释文件:https://github.com/IDR/idr0012-fuchs-cellmorph/tree/master/screenA
应用领域
- 生物成像的机器学习流程
- 药物筛选数据
注意事项
- 注意图像工具(如OpenCV)可能自动转换为8位
- 原始Zarr文件具有更好的分辨率和延迟加载能力
- 实验可能存在错误或伪影
引用信息
BibTeX: @article{fuchs2010clustering, title={Clustering phenotype populations by genome-wide RNAi and multiparametric imaging}, author={Fuchs, Florian and Pau, Gregoire and Kranz, Dominique and Sklyar, Oleg and Budjan, Christoph and Steinbrink, Sandra and Horn, Thomas and Pedal, Angelika and Huber, Wolfgang and Boutros, Michael}, journal={Molecular systems biology}, volume={6}, number={1}, pages={370}, year={2010}, publisher={John Wiley & Sons, Ltd Chichester, UK} }
APA: Fuchs, F., Pau, G., Kranz, D., Sklyar, O., Budjan, C., Steinbrink, S., ... & Boutros, M. (2010). Clustering phenotype populations by genome‐wide RNAi and multiparametric imaging. Molecular systems biology, 6(1), 370.
联系方式
- 数据集联系人:Stefan Dvoretskii
- 联系人网站:https://steved.netlify.app/
搜集汇总
数据集介绍
构建方式
在基因组学与生物成像交叉领域,该数据集通过大规模RNA干扰技术系统构建。研究团队采用高通量成像平台,对22,839种siRNA介导的基因敲除在HeLa细胞中产生的表型效应进行量化采集,每个基因扰动均通过多参数图像特征提取生成标准化表型轮廓。数据遵循OMERO框架的高内涵筛选结构组织,原始图像经OME-Zarr格式转换后存储为16位PNG文件,配套的元数据以CSV表格和JSON-LD语义标注形式提供完整实验描述。
特点
作为整合遗传学与计算生物学的多维资源,该数据集突出表现为三个核心特征:其包含的全基因组尺度表型轮廓可实现基因功能的无监督聚类分析;多参数成像数据涵盖细胞形态、纹理及空间分布等量化指标,支持深层表型关联挖掘;数据层级遵循国际生物影像数据库标准,同时提供原始高分辨率Zarr格式与轻量化PNG版本,兼顾计算效率与信息完整性。这种结构设计为系统性探索基因功能网络提供了前所未有的实验基础。
使用方法
该数据集适用于构建生物医学影像分析的计算流程,研究者可通过解析标准化元数据关联图像与基因扰动信息。典型应用场景包括:利用表型轮廓相似性开发基因功能预测模型,基于多参数特征训练细胞状态分类器,或通过对比野生型与基因敲除样本揭示新型生物通路。使用中需特别注意图像处理工具可能导致的8位深度自动转换问题,建议优先采用保留原始动态范围的Zarr格式进行深度学习任务,同时可结合IDR平台提供的注释文件验证分析结果。
背景与挑战
背景概述
基因组生物成像领域在2010年迎来重要突破,由德国癌症研究中心主导的国际团队通过大规模RNA干扰技术,系统性地敲除HeLa细胞中22,839个基因并采集多维表型数据。这项发表于《分子系统生物学》的研究创新性地将高通量成像与计算分析方法相结合,旨在构建基因功能预测的新型范式。该数据集通过定量描述符捕捉细胞形态特征,为揭示基因功能网络关系提供了前所未有的可视化表型图谱,显著推进了功能基因组学与计算生物学的交叉融合。
当前挑战
该数据集面临的核心科学挑战在于如何从高维成像数据中准确提取具有生物学意义的表型特征,并建立其与基因功能的映射关系。在技术实现层面,需克服海量图像数据的标准化处理难题,包括16位深度图像与通用图像工具的兼容性问题。数据构建过程中还涉及多模态数据整合的复杂性,需协调OMERO平台的结构化存储与机器学习管道的需求,同时确保跨实验批次的数据可比性与注释一致性。
常用场景
经典使用场景
在基因组学与生物成像交叉领域,该数据集通过高通量RNA干扰筛选与多参数成像技术,系统记录了22,839种siRNA对HeLa细胞形态的影响。其经典应用场景聚焦于无监督聚类分析,借助定量表型轮廓对基因功能进行系统性归类,为揭示基因间功能关联提供可视化证据。
衍生相关工作
该数据集催生了多项生物信息学方法创新,例如基于深度学习的表型特征提取算法开发。以DONSON基因功能发现为代表的研究成果,启发了后续关于中心体蛋白与基因组稳定性关联的系列探索,相关分析方法已被拓展至癌症生物学与精准医疗等新兴研究领域。
数据集最近研究
最新研究方向
在基因组生物成像领域,该数据集正推动基于深度学习的多参数表型分析成为前沿热点。研究者通过整合高通量RNA干扰筛选与三维细胞成像数据,构建表型图谱以预测基因功能,尤其聚焦于DNA损伤应答等关键生物学过程。这类工作显著加速了功能基因组学发现,例如通过表型相似性成功识别出DONSON等新型中心体蛋白。当前研究正探索跨模态表征学习技术,将成像特征与分子遗传数据关联,为药物筛选和疾病机制解析提供新范式,其方法论已延伸至癌症精准医疗与细胞动力学建模等交叉领域。
以上内容由遇见数据集搜集并总结生成


