Code-170k-dombe
收藏Hugging Face2025-10-23 更新2025-10-24 收录
下载链接:
https://huggingface.co/datasets/michsethowusu/Code-170k-dombe
下载链接
链接失效反馈官方服务:
资源简介:
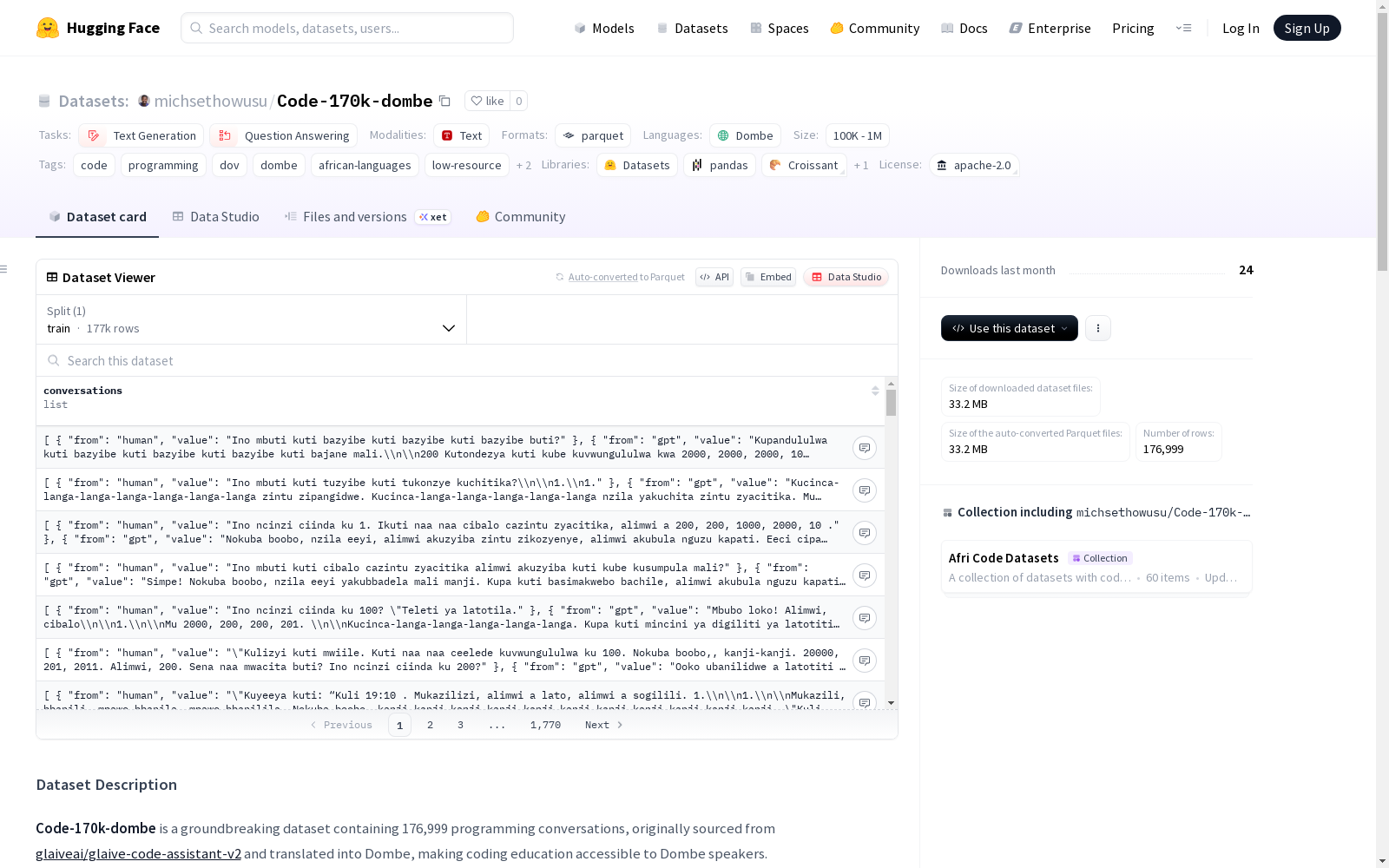
Code-170k-dombe是一个包含176,999个编程对话的数据集,这些对话被翻译成Dombe语言,使得编码教育对Dombe语使用者更加普及。它包含关于编程和编码的高质量多轮对话,覆盖了算法、数据结构、调试、最佳实践等多种主题,并且适用于大型语言模型的指令微调。
创建时间:
2025-10-20
原始信息汇总
Code-170k-dombe 数据集概述
基本信息
- 数据集名称:Code-170k-dombe
- 数据集地址:https://huggingface.co/datasets/michsethowusu/Code-170k-dombe
- 许可证:Apache 2.0
- 语言:多贝语(dov)
数据集规模
- 训练集样本数量:176,999
- 训练集大小:116,431,164字节
- 下载大小:58,215,582字节
- 规模分类:100K<n<1M
数据集描述
Code-170k-dombe是一个包含176,999个编程对话的开创性数据集,原始数据来源于glaiveai/glaive-code-assistant-v2,并翻译成多贝语,使多贝语使用者能够接触编程教育。
主要特征
- 包含176,999个高质量的编程和编码对话
- 纯多贝语内容
- 多轮对话涵盖各种编程概念
- 多样化主题:算法、数据结构、调试、最佳实践等
- 适用于大型语言模型的指令调优
数据结构
数据字段
conversations:对话轮次列表,每个轮次包含:from:发言者("human"或"gpt")value:多贝语的消息内容
数据示例
python { "conversations": [ { "from": "human", "value": "[多贝语问题]" }, { "from": "gpt", "value": "[多贝语回答]" } ] }
任务类别
- 文本生成
- 问答
标签
- 代码
- 编程
- 多贝语
- 非洲语言
- 低资源语言
- 多语言
- 指令调优
使用场景
- 训练多贝语编码助手
- 为多贝语开发者构建教育工具
- 研究多语言代码生成
- 创建多贝语编程教程
- 支持低资源语言人工智能开发
搜集汇总
数据集介绍
构建方式
在编程教育领域,Code-170k-dombe数据集通过精心设计的转化流程构建而成。原始数据源自glaiveai/glaive-code-assistant-v2的编程对话资源,经过系统性的语言转换处理,将17万条高质量编程对话完整翻译为多贝语。该构建过程特别注重保持编程术语的准确性和教学对话的连贯性,最终形成包含176,999个训练样本的标准化数据集,为低资源语言社区的编程教育奠定坚实基础。
特点
该数据集最显著的特征在于其语言资源的稀缺性与专业性并存。作为专门面向多贝语使用者的编程教育资料,它不仅覆盖算法设计、数据结构、调试技巧等核心编程概念,还采用多轮对话形式呈现专业知识。每个对话单元都严格遵循人机交互模式,通过human-gpt的角色分配构建完整的教学场景。这种设计既保留了原始数据的技术深度,又实现了编程知识在低资源语言环境中的本土化表达。
使用方法
对于研究人员和开发者而言,该数据集可直接通过Hugging Face生态系统进行调用。使用load_dataset函数加载数据集后,用户可获得包含conversations字段的训练集,其中每个对话单元由from和value两个关键属性构成。这种标准化结构特别适用于指令调优任务,能够有效支持多贝语编程助手的开发,同时为跨语言代码生成研究提供重要的实验数据支撑。
背景与挑战
背景概述
随着人工智能技术在编程教育领域的深入应用,多语言代码助手的发展成为推动计算思维普及的关键环节。Code-170k-dombe数据集于2025年由研究团队基于glaive-code-assistant-v2转化构建,专注于将17.7万组编程对话翻译为非洲Dombe语言。该数据集通过多轮对话覆盖算法设计、调试实践等核心编程概念,旨在解决低资源语言群体在技术教育中的语言壁垒,为Dombe语者构建本土化编程教学工具提供了重要基础。
当前挑战
在编程教育领域,低资源语言面临技术术语体系缺失与语料稀疏的双重挑战。数据集构建过程中需克服Dombe语言编程术语标准化不足的困难,同时确保从英文到Dombe的语义精确转换。多轮对话结构的完整性维护要求翻译过程保留技术逻辑连贯性,而低资源语言的语法特性更增加了对话自然度保持的复杂度,这些因素共同构成了高质量跨语言编程知识迁移的技术瓶颈。
常用场景
经典使用场景
在编程教育领域,Code-170k-dombe数据集通过17万条高质量的多轮对话,为Dombe语种的学习者构建了沉浸式编程教学环境。这些对话涵盖算法设计、数据结构应用及代码调试等核心主题,能够有效支撑编程助手的指令调优过程,促进低资源语言环境下技术知识的本土化传播。
解决学术问题
该数据集显著缓解了低资源语言在代码生成研究中的数据稀缺困境,为跨语言编程教育提供了实证基础。通过将英文编程知识系统转化为Dombe语料,它不仅推动了多语言大模型在技术领域的适应性研究,更为探索语言壁垒对编程认知的影响提供了关键数据支撑。
衍生相关工作
基于该数据集衍生的经典研究包括Dombe语种代码生成模型的架构优化,以及低资源语言指令调优范式的创新。这些工作进一步催生了面向非洲语言的编程教育平台,并启发了针对其他小众语种的代码语料构建计划,形成跨语言技术传播的良性生态。
以上内容由遇见数据集搜集并总结生成


