IndianBailJudgments-1200
收藏arXiv2025-07-03 更新2025-08-15 收录
下载链接:
https://huggingface.co/datasets/SnehaDeshmukh/IndianBailJudgments-1200
下载链接
链接失效反馈官方服务:
资源简介:
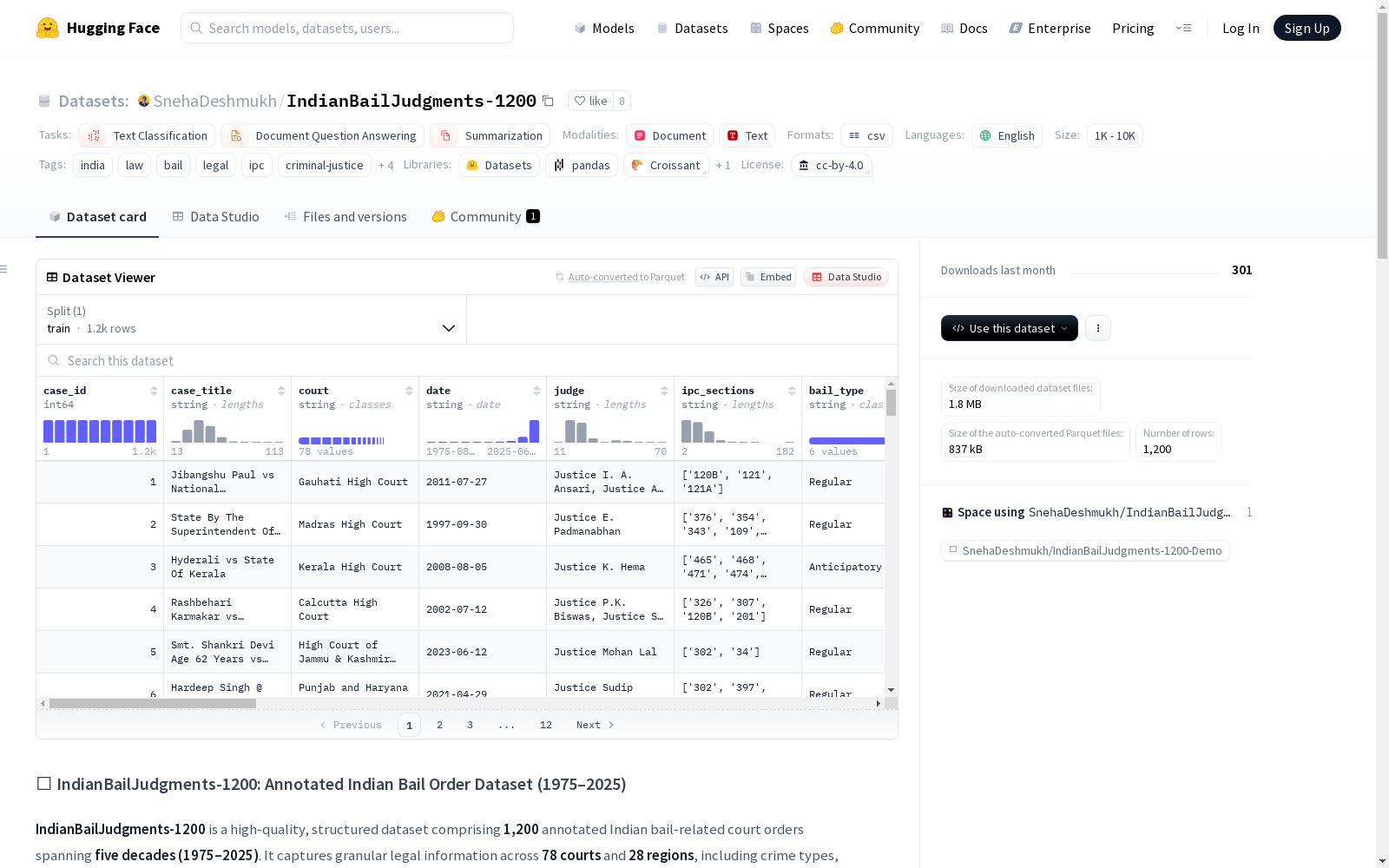
IndianBailJudgments-1200是一个包含1200个印度法院关于保释决定的判决数据集,每个案件都被标注了超过20个结构化的属性,包括保释结果、IPC条款、犯罪类型、法院名称和法律推理等。这些标注是使用GPT-4o模型生成的,并经过人工验证,以确保上下文的可靠性。该数据集支持多种NLP任务,包括案件结果分类、信息提取、法律摘要和公平性分析。它是第一个专门关注印度保释法的公开数据集,旨在将现实世界的法律文本与人工智能驱动的分析联系起来,为法律NLP研究提供开放资源。
IndianBailJudgments-1200 is a dataset containing 1,200 judgments from Indian courts concerning bail decisions. Each case is annotated with over 20 structured attributes, including bail outcome, IPC provisions, crime type, court name, legal reasoning, and more. These annotations were generated using the GPT-4o model and verified by human annotators to ensure contextual reliability. This dataset supports a range of NLP tasks, such as case outcome classification, information extraction, legal summarization, and fairness analysis. It is the first public dataset specifically focused on Indian bail law, designed to connect real-world legal texts with AI-driven analysis and offer an open resource for legal NLP research.
提供机构:
达塔·梅赫工程学院计算机工程系
创建时间:
2025-07-03
搜集汇总
数据集介绍
构建方式
IndianBailJudgments-1200数据集的构建采用了多阶段流程,首先从Indian Kanoon等公开法律资源库中收集了1200份印度高等法院的保释相关判决书。为确保样本多样性,研究团队精心筛选了涵盖不同犯罪类型、地域分布和时间跨度的案例,并采用OCR技术对原始PDF/HTML文档进行文本提取和清洗。核心标注工作通过精心设计的GPT-4o提示工程实现,该模型根据法律专家制定的20余项结构化模式(包括保释结果、IPC条款、犯罪类型等)自动生成标注,最后由法律专业人员对12.5%的案例进行人工验证,确保标注质量符合司法语境要求。
特点
该数据集作为印度首个专注于保释司法的公开NLP资源,具有三个显著特征:其多维度标注体系不仅包含保释结果等基础字段,更涵盖司法推理过程、共同被告平等原则适用等深层法律特征;地域分布上覆盖孟买、阿拉哈巴德等主要高等法院的判例,犯罪类型横跨谋杀、毒品犯罪等12个类别;独特的双案例类型设计(常规保释申请与里程碑判例)为研究提供了更丰富的分析视角。数据集还特别标注了潜在偏见标志和性别信息,使其成为研究司法公平性的理想样本。
使用方法
研究人员可通过Hugging Face或GitHub平台获取该JSON格式数据集,其结构化设计支持开箱即用的多任务处理。在保释结果预测任务中,可利用bail_outcome字段作为监督信号,结合IPC条款等特征训练分类模型;法律摘要生成任务则可基于judgment_reason和summary字段进行序列到序列建模。对于公平性分析,建议交叉分析accused_gender与bail_outcome的关联模式。使用前需注意数据局限,建议配合附录中的标注提示模板进行结果验证,并遵循论文所述的伦理准则。
背景与挑战
背景概述
IndianBailJudgments-1200是由Sneha Deshmukh和Prathmesh Kamble于2025年创建的印度保释判决数据集,旨在填补印度法律自然语言处理(NLP)领域的数据空白。该数据集包含1200个印度法院的保释判决,每个案例标注了超过20个结构化属性,如保释结果、IPC条款、犯罪类型、法院名称和法律推理等。其核心研究问题是通过结构化数据支持保释判决的预测、信息提取、法律摘要和公平性分析等任务,为印度法律NLP研究提供了首个专注于保释法学的公开数据集。该数据集的发布显著推动了印度法律AI的发展,并为司法透明度和公平性研究提供了重要资源。
当前挑战
IndianBailJudgments-1200面临的挑战主要包括两方面:领域问题挑战和构建过程挑战。在领域问题方面,印度保释判决涉及复杂的法律推理和多因素权衡(如犯罪严重性、前科记录和社会背景),且缺乏大规模结构化数据支持相关研究。构建过程中的挑战包括:1) 数据来源多为非结构化的PDF或HTML文档,缺乏标准化格式;2) 法律文件常混合英语与地区语言表达,风格不一致;3) 印度法律文本普遍缺乏标注结果和结构化司法理由;4) 需通过提示工程优化的GPT-4o生成标注,并经过人工验证以确保准确性。这些挑战使得数据集的构建需要结合法律专业知识与先进的NLP技术。
常用场景
经典使用场景
在印度法律自然语言处理(NLP)领域,IndianBailJudgments-1200数据集为研究者提供了一个多属性标注的法律文本资源,特别聚焦于保释判决的深入分析。数据集包含1200个印度法院的保释相关判决,每个案例标注了超过20个结构化属性,如保释结果、IPC条款、犯罪类型、法院名称和法律推理。这些标注通过精心设计的GPT-4o提示生成,并经过法律专家手动验证,确保了数据的准确性和可靠性。数据集支持多种NLP任务,包括案件结果分类、信息提取、法律摘要和公平性分析,填补了印度保释法学研究的数据空白。
解决学术问题
IndianBailJudgments-1200数据集解决了印度法律NLP研究中数据稀缺和标注不足的问题。通过提供结构化且多样化的保释判决数据,该数据集使研究者能够深入探讨保释决策的模式和影响因素。例如,研究者可以分析犯罪类型、被告性别、法院地域等因素对保释结果的影响,从而揭示潜在的司法偏见或系统性不公平。此外,数据集支持法律推理和信息提取任务,为开发更智能的法律辅助工具奠定了基础。
衍生相关工作
IndianBailJudgments-1200数据集的发布催生了一系列相关研究和技术开发。例如,基于该数据集的研究可能开发出针对印度法律文本的预训练语言模型(如IndianLegal-BERT的扩展版本),或设计专门的公平性检测算法以评估司法决策中的偏见。此外,数据集还可能激发跨学科合作,如法学与计算机科学的联合研究项目,进一步推动法律AI技术的发展。
以上内容由遇见数据集搜集并总结生成


