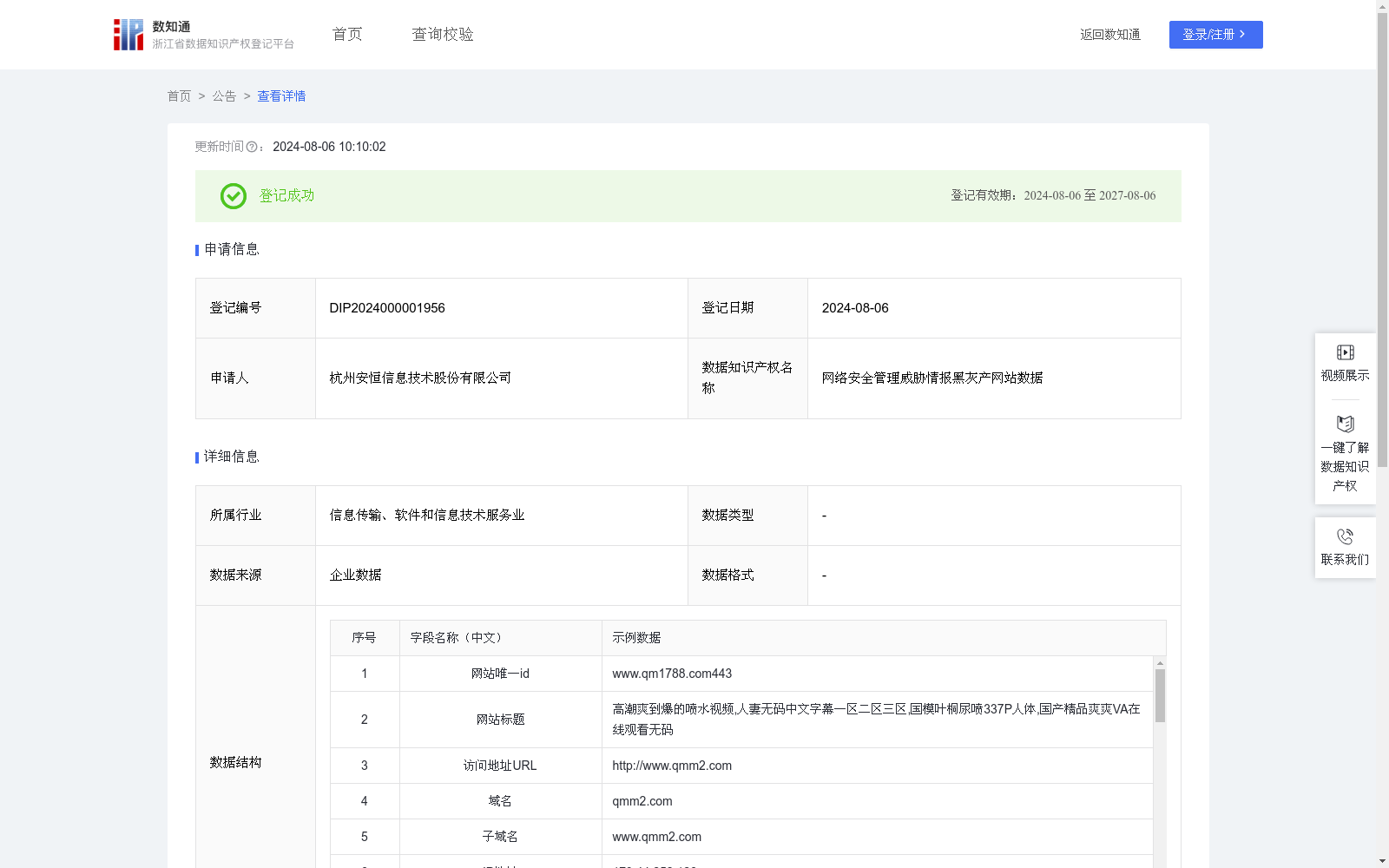
网络安全管理威胁情报黑灰产网站数据
收藏浙江省数据知识产权登记平台2024-08-06 更新2024-08-07 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/47691
下载链接
链接失效反馈官方服务:
资源简介:
1.网络安全治理:此类情报对于政府监管部门、执法机构、网络安全公司和企业安全团队来说至关重要,它们用于识别、追踪、打击网络犯罪行为,强化网络空间监管与法治建设。
政府监管部门:利用黑灰产网站情报库,政府监管部门能够迅速识别并追踪涉及网络犯罪行为的网站,对违法违规活动进行及时打击,从而维护网络空间的清朗与安全。
执法机构:执法机构在调查网络犯罪案件时,可以借助黑灰产网站情报库中的信息,获取关键线索,提高办案效率,有效打击网络犯罪行为。
2.风险管理:金融机构、电商平台、社交网络等利用此类情报预判潜在的安全威胁,降低数据泄露、欺诈交易、洗钱等风险。
电商平台:电商平台可以利用黑灰产网站情报库,对平台上的交易进行风险评估,及时发现并处置涉及欺诈、洗钱等违法违规行为的交易,保障平台交易安全。 数据采集:通过公司自研资产探测引擎获取网站相关信息,包括不限于网站url、域名、ip、端口、协议、网站源码信息等等。
数据清洗:对数据进行结构化转换、标准统一、字段清洗以及多维信息聚合,以满足后续数据研判以及分析需求。
数据加工:包含文本特征处理、TextCNN模型训练、模型预测以及分类标签输出四个阶段。
1.文本特征处理阶段,清洗文本,去除噪声和停用词。然后,使用分词技术分割文本为词汇。为了捕捉文本的深层含义,我们采用词嵌入技术Word2Vec,将每个词转换为携带语义信息的词向量。
2.TextCNN模型训练阶段,我们使用卷积神经网络架构。输入层接收处理后的词向量,随后通过多个卷积层,旨在捕捉文本中的短语结构。池化层随后提炼出关键特征,全连接层整合这些特征,最后,输出层通过Softmax函数,生成涉黄、涉赌及正常文本的概率分布。
3.模型预测环节,当有新的文本输入时,它们首先经历与训练数据相同的预处理步骤,然后通过训练好的TextCNN模型进行分类预测。模型输出每个类别的概率,为后续的决策提供依据。
4.输出分类标签阶段,基于预测的概率和预设的阈值,网站被进行分类(黄、赌等);
1. Cybersecurity Governance: Such intelligence is critical for government regulatory authorities, law enforcement agencies, cybersecurity companies and enterprise security teams, which use it to identify, track and combat cybercrime, and strengthen cyberspace supervision and the rule of law.
Government Regulatory Authorities: Leveraging the black and gray industry website intelligence database, government regulatory authorities can quickly identify and track websites involved in cybercrime, timely crack down on illegal and unauthorized activities, thereby maintaining a clean and secure cyberspace.
Law Enforcement Agencies: When investigating cybercrime cases, law enforcement agencies can obtain key clues from the information in the black and gray industry website intelligence database, improve case handling efficiency and effectively combat cybercrime.
2. Risk Management: Financial institutions, e-commerce platforms, social networks and other entities use such intelligence to anticipate potential security threats and reduce risks such as data breaches, fraudulent transactions and money laundering.
E-commerce Platforms: E-commerce platforms can use the black and gray industry website intelligence database to conduct risk assessments on transactions on their platforms, timely detect and dispose of transactions involving illegal activities such as fraud and money laundering, ensuring platform transaction security.
Data Collection: Obtain website-related information through the company's self-developed asset detection engine, including but not limited to website URLs, domain names, IPs, ports, protocols, website source code information and so on.
Data Cleaning: Perform structured conversion, standard unification, field cleaning and multi-dimensional information aggregation on the data to meet the requirements of subsequent data research and analysis.
Data Processing: Includes four stages: text feature processing, TextCNN model training, model prediction and classification label output.
1. Text Feature Processing Stage: Clean the text, remove noise and stop words. Then, use word segmentation technology to split the text into individual words. To capture the deep semantic meaning of the text, we adopt the word embedding technology Word2Vec to convert each word into a word vector carrying semantic information.
2. TextCNN Model Training Stage: We adopt a convolutional neural network architecture. The input layer receives the processed word vectors, followed by multiple convolutional layers aimed at capturing phrase structures in the text. The pooling layer then extracts key features, the fully connected layer integrates these features, and finally, the output layer uses the Softmax function to generate probability distributions for pornographic, gambling and normal texts.
3. Model Prediction Stage: When new text is input, it first undergoes the same preprocessing steps as the training data, and then performs classification prediction via the trained TextCNN model. The model outputs the probability of each category, providing a basis for subsequent decision-making.
4. Classification Label Output Stage: Based on the predicted probabilities and preset thresholds, websites are classified (e.g., pornographic, gambling, etc.);
提供机构:
杭州安恒信息技术股份有限公司
创建时间:
2024-06-21
搜集汇总
数据集介绍
以上内容由遇见数据集搜集并总结生成


