有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
default)
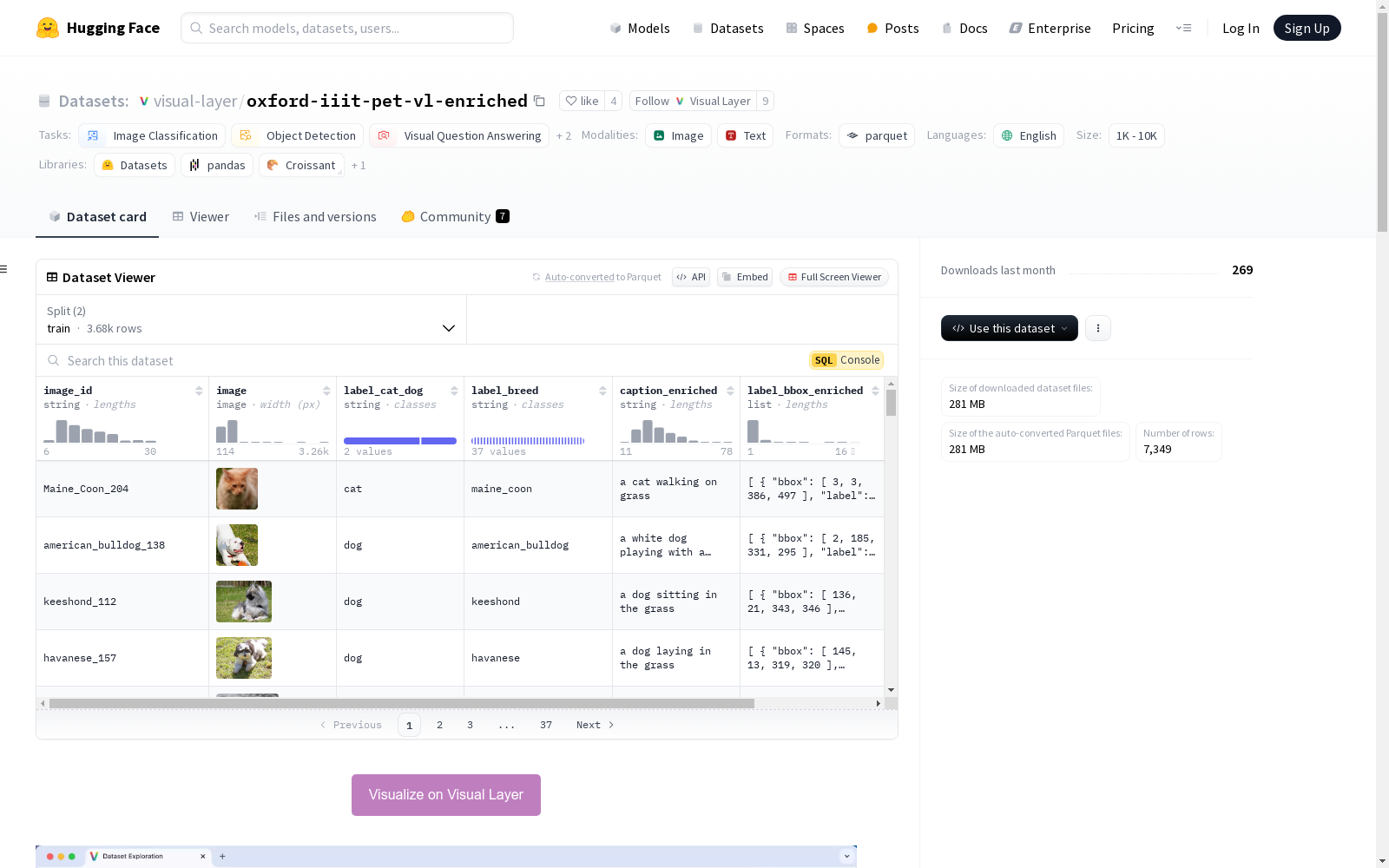
train): data/train-*test): data/test-*image_id: 图像的唯一标识符,类型为字符串。image: 图像数据,类型为图像。label_cat_dog: 图像标签,表示是猫还是狗,类型为字符串。label_breed: 图像标签,表示猫或狗的品种,包含37种猫和狗的品种,类型为字符串。caption_enriched: 图像的丰富描述,类型为字符串。label_bbox_enriched: 图像的丰富标签,包含边界框坐标、置信度和标签,类型为列表。
bbox: 边界框坐标,类型为整数序列。label: 边界框标签,类型为字符串。issues: 图像质量问题,类型为列表。
confidence: 置信度,类型为浮点数。description: 描述,类型为空。issue_type: 问题类型,类型为字符串。train)
test)
中国气象数据
本数据集包含了中国2023年1月至11月的气象数据,包括日照时间、降雨量、温度、风速等关键数据。通过这些数据,可以深入了解气象现象对不同地区的影响,并通过可视化工具揭示中国的气温分布、降水情况、风速趋势等。
github 收录
中国农村教育发展报告
该数据集包含了中国农村教育发展的相关数据,涵盖了教育资源分布、教育质量、学生表现等多个方面的信息。
www.moe.gov.cn 收录
UCI Wine
UCI Wine数据集包含了178个样本,每个样本有13个特征,用于分类任务。这些特征包括葡萄酒的化学成分,如酒精含量、苹果酸、灰分等。数据集的目标是将葡萄酒分类为三个不同的品种。
archive.ics.uci.edu 收录
Pet Disease images
Comprehensive Image Dataset for Detecting Pet Diseases Across Multiple Species
kaggle 收录
MedDialog
MedDialog数据集(中文)包含了医生和患者之间的对话(中文)。它有110万个对话和400万个话语。数据还在不断增长,会有更多的对话加入。原始对话来自好大夫网。
github 收录