CSU-JPG/Textground4M
收藏Hugging Face2026-05-02 更新2026-05-10 收录
下载链接:
https://hf-mirror.com/datasets/CSU-JPG/Textground4M
下载链接
链接失效反馈官方服务:
资源简介:
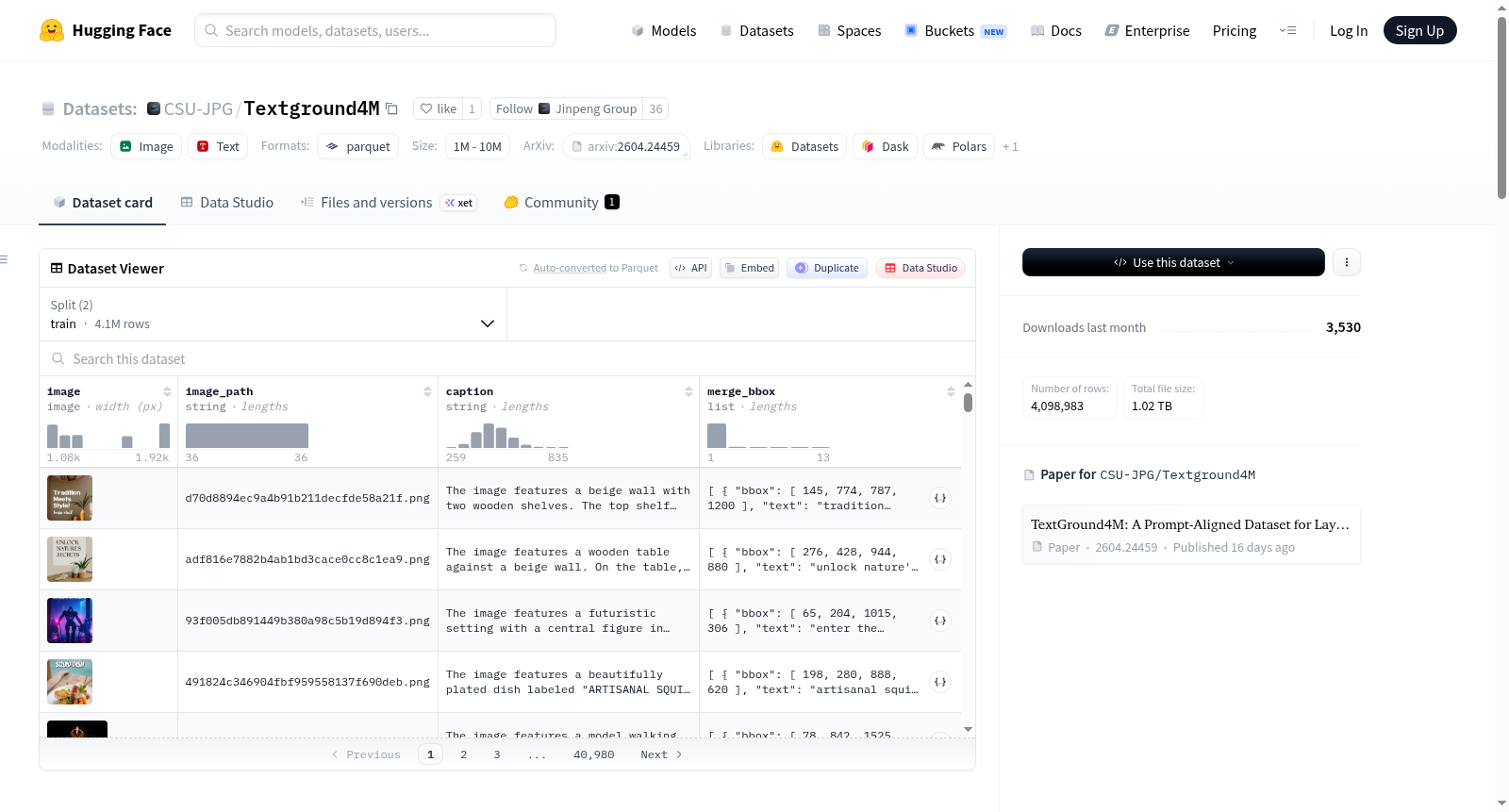
TextGround4M是一个大规模的数据集,专门用于文本到图像(T2I)生成中的提示对齐和布局感知的文本渲染。该数据集包含410万条提示-图像对,每条数据都标注有自然语言标题,其中所有渲染的文本跨度都被明确引用,并且有跨度的边界框链接到图像中的空间位置。这种细粒度的注释为T2I模型提供了布局感知和提示对齐的监督能力,这是之前的数据集如MARIO-10M和AnyWord-3M所不具备的。数据集分为训练集和测试集,训练集约有4.1M样本,测试集有1,000样本。数据字段包括图像、图像路径、标题和合并边界框等信息。
TextGround4M is a large-scale dataset for prompt-grounded, layout-aware text rendering in text-to-image (T2I) generation. It contains 4.1 million prompt-image pairs, each annotated with a natural language caption where all rendered text spans are explicitly quoted, and span-level bounding boxes linking each quoted text to its spatial location in the image. This fine-grained annotation enables layout-aware, prompt-grounded supervision for T2I models — a capability missing from prior datasets like MARIO-10M and AnyWord-3M. The dataset is split into a training set with ~4.1M samples and a test set with 1,000 samples. Data fields include image, image_path, caption, and merge_bbox.
提供机构:
CSU-JPG
搜集汇总
数据集介绍
构建方式
TextGround4M数据集由来自CSU-JPG团队的研究者构建,旨在解决文本到图像生成模型中布局感知文本渲染的监督缺失问题。该数据集整合了多个现有来源的图像与文本数据,并通过自动化管道与人工校验相结合的方式,为每张图像生成了精细的空间标注。具体而言,每对图文数据均包含一段自然语言描述,其中所有出现在图像中的文本片段均以显式引号标注,同时为每个引号内的文本提供了对应的边界框坐标,精确指示其在图像中的空间位置。经过这一流程,数据集最终汇集了约410万条训练样本与1000条测试样本,为布局可控的文本渲染任务提供了大规模、高质量的监督信号。
特点
该数据集最显著的特点在于其细粒度且对齐性强的标注结构。不同于以往数据集仅提供粗糙的文本位置或全局描述,TextGround4M实现了提示词中每个文本跨度的空间定位与其语义内容的精确对应,即‘引用式’标注。这种设计使得模型能够学习到文本内容、空间位置与视觉上下文之间的三重关联,从而支持布局感知、提示词驱动的文本生成。此外,测试集进一步依据渲染难度划分为简单、中等、困难三个层次,为评估模型在不同挑战级别下的性能提供了标准化基准。数据以HuggingFace datasets格式发布,包含图像、标题、边界框等字段,便于研究者直接加载与使用。
使用方法
研究者可通过HuggingFace的`datasets`库便捷地加载完整数据集或其指定子集,例如使用`load_dataset("CSU-JPG/Textground4M", split="train")`调用训练部分,或通过`split="test"`获取包含1000个样本的测试基准。每个样本的`merge_bbox`字段以列表形式存储了多个文本边界框及其对应文本内容,而`caption`字段则提供了带引号标记的自然语言提示。对于测试集,额外的`test/metadata.jsonl`文件还记录了每个样本的难度等级(`data_type`字段),便于进行分层评估。用户可根据自身模型需求,利用这些结构化标注直接训练或精调布局敏感的文本渲染模型,或将其作为评估工具,衡量已有T2I系统的空间文本生成能力。
背景与挑战
背景概述
TextGround4M是由Mao、Wang、Li、Yang和Wang等研究者在AAAI 2026会议上提出的大规模数据集,旨在解决文本到图像生成中布局感知文本渲染的精准对齐问题。该数据集包含约410万张图像,每张图像均配有人工标注的自然语言描述,其中所有渲染的文本片段被明确引用,并附有边界框以指示其空间位置。TextGround4M的发布填补了此前MARIO-10M和AnyWord-3M等数据集在提示引导、布局感知监督能力方面的空白,为提升生成图像中文本的准确性和美观性提供了关键资源,在文本图像生成领域具有重要影响力。
当前挑战
TextGround4M所解决的领域核心挑战是文本到图像生成模型中文本渲染的布局对齐问题,现有模型常因缺乏精细的空间文本监督而产生模糊或位置错误的文字。数据集构建过程中面临多重技术挑战:首先,需从海量互联网图像中自动筛选出包含可读文本的样本,并保证文本与提示描述的语义一致性;其次,标注工作需精确为每个文本片段定位边界框,同时保持自然语言描述的自然流畅性;最后,处理不同字体、方向及背景干扰下的文本检测与识别,确保数据质量,这些挑战推动了数据集设计的高度自动化与精细化。
常用场景
经典使用场景
TextGround4M 是一个专为文本到图像生成任务设计的大规模数据集,其核心应用在于实现布局感知的文字渲染。该数据集包含约410万对提示-图像对,每对数据均配有自然语言描述,其中所有渲染文本片段均被明确引用,并附有跨度级别的边界框,将每个引文与图像中的空间位置精准关联。这种细粒度的标注方式,使得研究者能够训练模型在生成图像时,不仅理解文本的语义内容,还能精确控制文本在图像中的摆放位置、大小和角度,从而生成更加自然、协调且符合提示要求的视觉文字。经典使用场景包括:在广告海报生成、信息图表制作以及品牌标识设计中,确保生成的文字与背景图像完美融合,避免出现文字模糊、错位或风格不匹配等问题。
解决学术问题
TextGround4M 数据集精准解决了文本到图像生成领域中一个长期存在的学术难题:如何让生成的图像忠实呈现提示中的文字内容,并将其准确地放置在指定位置。此前,诸如 Stable Diffusion 等主流模型在生成含有文字的图像时,常常出现文字拼写错误、字形扭曲、位置杂乱无章等现象,严重制约了生成图像的实际可用性。该数据集通过提供大规模的、带有精准空间标注的图文对,为模型提供了明确的布局感知监督信号,驱动了从“看图写话”到“依文绘图”的重大范式转变。其意义在于,它首次将文本渲染问题系统地纳入布局生成框架,使得模型能够学习到文字在图像中的几何与语义一致性,从而显著提升了生成内容的可读性与美学价值。这一成果对多模态理解与生成、视觉语言导航等前沿领域产生了深远的推动影响。
衍生相关工作
TextGround4M 数据集的出现催生了一系列具有影响力的衍生研究工作。在其基础上,研究者们开发了专门用于布局感知文字生成的扩散模型架构,如将空间边界框信息作为条件输入到 UNet 或 Transformer 骨干网络中,显著提升了文字位置控制的精确度。同时,针对该数据集标注结构,衍生出多种提示-布局联合建模方法,例如利用注意力机制动态调整文字区域的生成权重,实现了复杂背景下的高保真度文字渲染。此外,该数据集还被用作基准测试平台,催生了一批旨在量化评估图文一致性的新指标,如空间对齐评分和字符级准确率。学术界也出现了将其与大型语言模型(LLM)结合的探索,通过利用 LLM 的语义理解能力,自动优化文本提示并生成符合布局约束的渲染指令,进一步拓展了 controllable generation 的技术边界。这些工作共同促进了文本到图像生成领域从“低资源、弱控制”向“高资源、强布局”阶段的跨越。
以上内容由遇见数据集搜集并总结生成


