多粒度视频-文本预训练数据集
收藏arXiv2024-12-11 更新2024-12-12 收录
下载链接:
http://arxiv.org/abs/2412.07704v1
下载链接
链接失效反馈官方服务:
资源简介:
该数据集是通过Granularity EXpansion (GEX)方法从单粒度视频-文本数据集扩展而来的多粒度数据集,旨在解决视频-文本学习任务中的跨模态对齐问题。数据集通过视频和文本的集成与压缩操作生成,能够反映真实世界中视频和文本的多粒度特性。创建过程简单且可扩展,无需额外的人工标注。该数据集主要应用于视频-文本对齐、视频分类和视频问答等任务,旨在提升模型在长视频理解任务中的表现。
This dataset is a multi-granularity dataset expanded from single-granularity video-text datasets via the Granularity EXpansion (GEX) method, aiming to address the cross-modal alignment problem in video-text learning tasks. It is generated through integration and compression operations on videos and texts, and can reflect the multi-granularity characteristics of videos and texts in real-world scenarios. Its construction process is simple and scalable, with no need for additional manual annotations. This dataset is mainly applied to tasks such as video-text alignment, video classification, and video question answering, aiming to improve the performance of models in long video understanding tasks.
提供机构:
德克萨斯A&M大学,亚马逊
创建时间:
2024-12-11
搜集汇总
数据集介绍
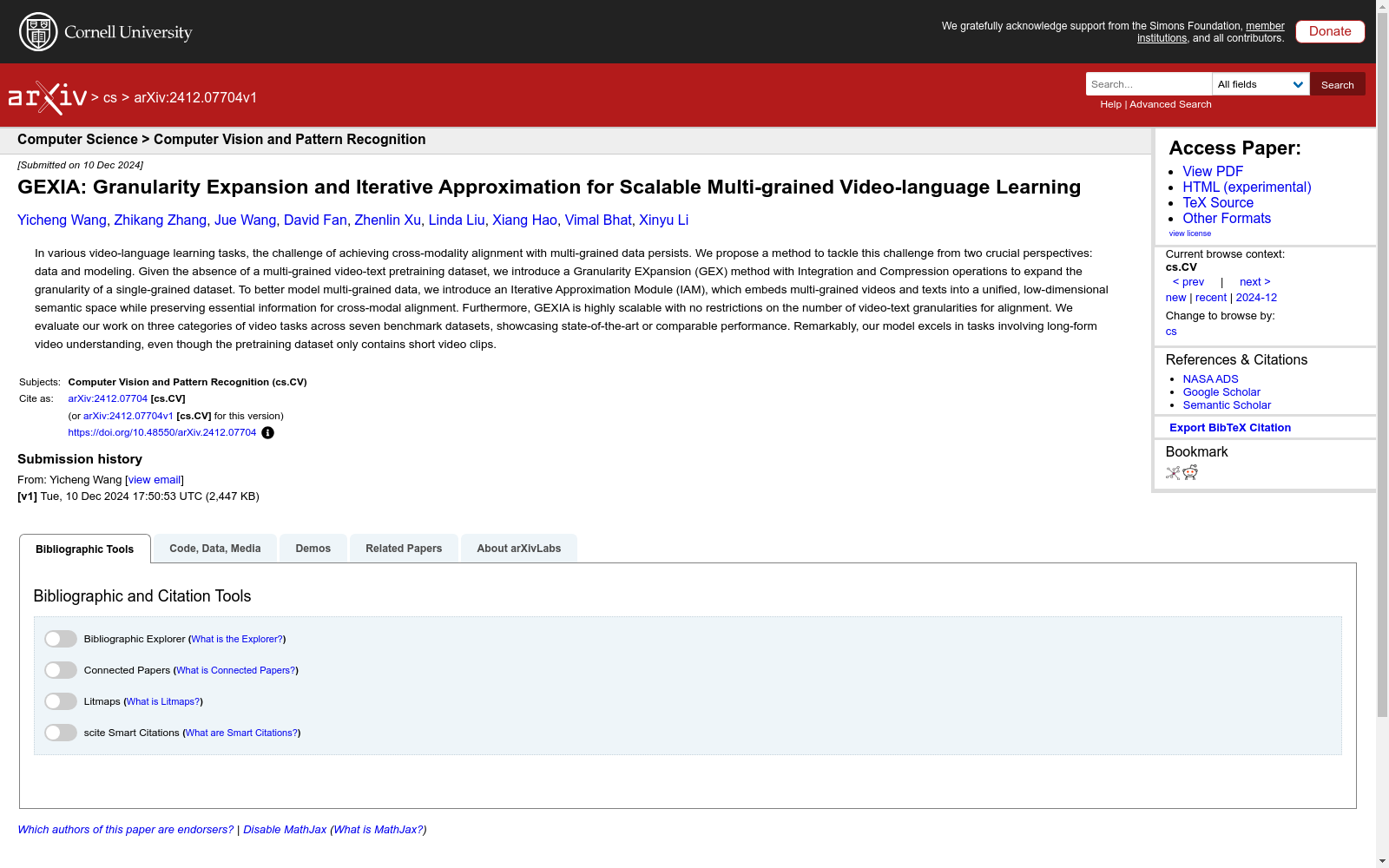
构建方式
多粒度视频-文本预训练数据集通过Granularity EXpansion (GEX)方法构建,该方法通过集成和压缩操作将单一粒度的视频-文本数据集扩展为多粒度数据集。具体而言,视频和文本分别通过集成操作(⊕v和⊕t)进行拼接,生成更长的视频-文本对,并通过文本压缩操作(Θt)使用大型语言模型对长文本进行摘要,从而生成新的粒度。这些操作可以递归应用,以生成所需数量的粒度,从而实现数据集的多粒度扩展。
特点
该数据集的核心特点在于其多粒度性,能够反映真实世界中视频和文本的自然多样性。通过GEX方法,数据集不仅包含短视频和短文本,还涵盖了长视频与长文本、长视频与短文本等多种组合,从而为模型提供了丰富的训练样本。此外,数据集的构建过程高度可扩展,无需额外的人工标注,能够适应不同粒度的视频-文本对,为跨模态学习提供了强大的数据支持。
使用方法
多粒度视频-文本预训练数据集可用于多种视频-语言任务的预训练和微调。首先,模型可以在该数据集上进行预训练,学习多粒度的视频-文本表示。随后,预训练模型可以针对特定的下游任务(如视频分类、视频问答、跨模态检索等)进行微调。在使用过程中,模型通过迭代近似模块(IAM)将不同粒度的视频和文本嵌入到统一的低维语义空间中,并通过对比学习实现跨模态对齐。
背景与挑战
背景概述
多粒度视频-文本预训练数据集(Granularity Expansion and Iterative Approximation for Scalable Multi-grained Video-language Learning, GEXIA)由德克萨斯A&M大学和亚马逊的研究团队于2024年提出。该数据集的核心研究问题是如何在视频-语言学习任务中实现多粒度数据的跨模态对齐。由于现有的视频-文本预训练数据集多为单粒度,无法反映现实世界中视频和文本的多粒度特性,GEXIA通过引入Granularity Expansion (GEX)方法,将单粒度数据集扩展为多粒度数据集,从而解决了这一瓶颈问题。该数据集的提出对视频-语言学习领域具有重要意义,尤其是在长视频理解和跨模态检索等任务中表现出色。
当前挑战
多粒度视频-文本预训练数据集面临的挑战主要来自两个方面:一是数据构建过程中的挑战,即如何从现有的单粒度数据集中生成多粒度数据,这需要设计有效的数据扩展方法,如视频和文本的整合与压缩操作;二是模型建模中的挑战,即如何处理不同粒度的视频和文本数据,确保其在统一的低维语义空间中进行有效对齐。此外,多粒度数据的处理还面临着计算复杂性和可扩展性的问题,如何在保证模型性能的同时提高计算效率也是一个重要的挑战。
常用场景
经典使用场景
多粒度视频-文本预训练数据集最经典的使用场景在于跨模态检索、视频分类和视频问答任务。通过引入多粒度数据扩展方法(GEX)和迭代近似模块(IAM),该数据集能够有效处理视频和文本在不同粒度上的对齐问题,尤其在长视频理解和复杂文本场景中表现出色。
解决学术问题
该数据集解决了视频-语言学习中多粒度数据对齐的常见学术问题。传统的单粒度方法无法充分捕捉视频和文本在不同时间尺度上的复杂关系,而多粒度视频-文本预训练数据集通过扩展数据粒度和引入迭代近似模块,显著提升了模型在跨模态对齐任务中的表现,尤其是在长视频理解和复杂文本场景中。
衍生相关工作
多粒度视频-文本预训练数据集的提出催生了一系列相关工作,包括基于多粒度对齐的跨模态检索模型(如X-CLIP)、长视频理解模型(如LF-VILA)以及视频问答系统(如Hero和Lavender)。这些工作进一步扩展了多粒度视频-文本对齐的应用场景,推动了视频-语言学习领域的技术进步。
以上内容由遇见数据集搜集并总结生成


