Grape multimodal object detection and semantic segmentation dataset
收藏Mendeley Data2023-08-29 更新2024-06-27 收录
下载链接:
https://www.doi.org/10.57760/sciencedb.j00001.00883
下载链接
链接失效反馈官方服务:
资源简介:
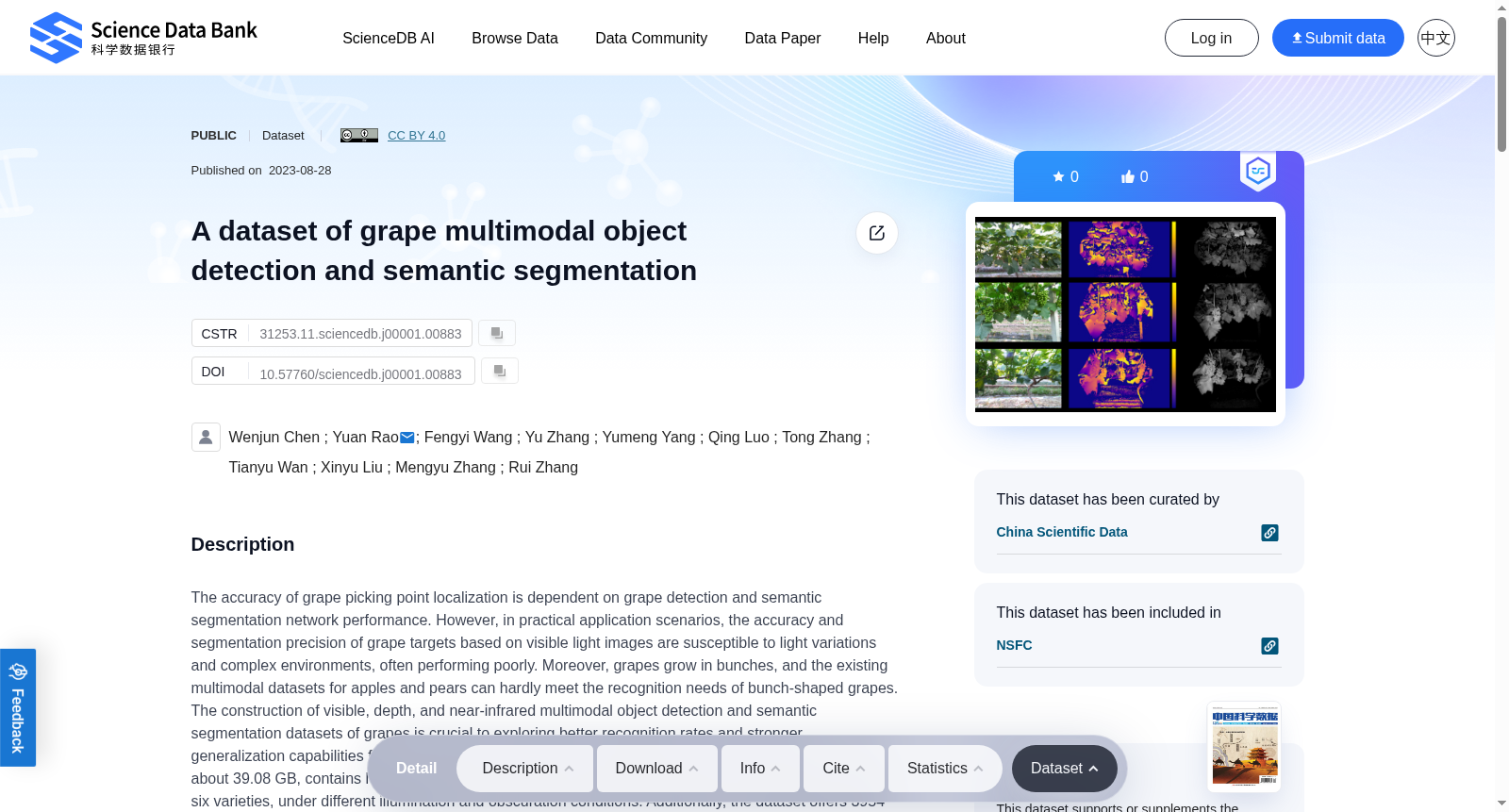
The accuracy of grape picking point localization is dependent on grape detection and semantic segmentation network performance. However, in practical application scenarios, the accuracy and segmentation precision of grape targets based on visible light images are susceptible to light variations and complex environments, often performing poorly. Moreover, grapes grow in bunches, and the existing multimodal datasets for apples and pears can hardly meet the recognition needs of bunch-shaped grapes. The construction of visible, depth, and near-infrared multimodal object detection and semantic segmentation datasets of grapes is crucial to exploring better recognition rates and stronger generalization capabilities for grape detection and semantic segmentation models. This dataset, totaling about 39.08 GB, contains high-quality multimodal video stream data of green and purple grapes, including six varieties, under different illumination and obscuration conditions. Additionally, the dataset offers 3954 labeled image samples extracted from the aforementioned multimodal video. By means of rotation, deflation, mis-slicing, panning, and Gaussian blur, the dataset can be augmented for the training implementation of mainstream deep learning models. The dataset can provide valuable basic data resources for multimodal fusion, grape semantic segmentation, and object detection, which have important practical application value for promoting research in the field of agricultural machinery and equipment intelligence.
葡萄采摘点定位的精度,取决于葡萄检测与语义分割(semantic segmentation)网络的性能表现。然而在实际应用场景中,基于可见光图像的葡萄目标检测精度与分割精度易受光照变化与复杂环境干扰,往往表现欠佳。此外,葡萄呈串状生长,现有针对苹果、梨的多模态数据集(multimodal datasets)难以满足串状葡萄的识别需求。构建涵盖可见光、深度与近红外(near-infrared)模态的葡萄多模态目标检测与语义分割数据集,对于研发具备更优识别率与更强泛化能力的葡萄检测及语义分割模型具有关键意义。本数据集总容量约39.08 GB,包含不同光照与遮挡条件下6个品种的绿葡萄与紫葡萄的高质量多模态视频流数据。此外,该数据集还提供了从上述多模态视频中提取的3954张标注图像样本。可通过旋转、缩放、错切、平移与高斯模糊(Gaussian blur)等方式对该数据集进行数据增强,以支撑主流深度学习模型的训练实施。本数据集可为多模态融合、葡萄语义分割与目标检测任务提供宝贵的基础数据资源,对推动农业机械装备智能化领域的研究具备重要实际应用价值。
创建时间:
2023-08-29
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是一个用于葡萄多模态目标检测和语义分割的高质量数据集,包含约39.08 GB的视频流数据和3954个标注图像样本,涵盖六种不同品种的葡萄在不同光照和遮挡条件下的图像。数据集可用于深度学习模型的训练和增强,具有重要的农业机械和设备智能化研究价值。
以上内容由遇见数据集搜集并总结生成


