LongViTU
收藏arXiv2025-01-09 更新2025-01-14 收录
下载链接:
https://rujiewu.github.io/LongViTU.github.io/
下载链接
链接失效反馈官方服务:
资源简介:
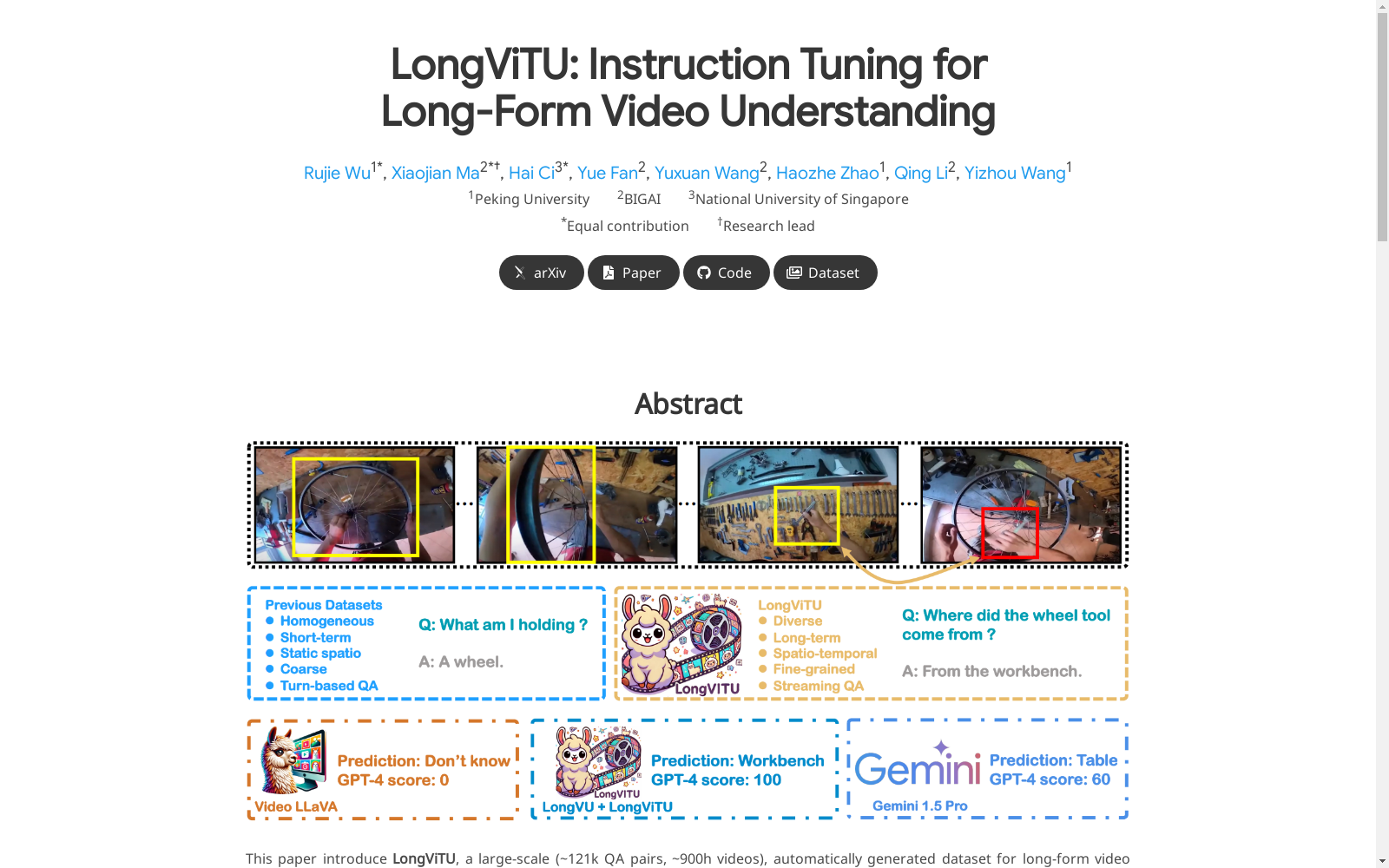
LongViTU是一个用于长视频理解的大规模数据集,由北京大学、BIGAI和新加坡国立大学的研究团队共同创建。该数据集包含约121k个高质量的问答对,覆盖约900小时的视频内容,平均每个视频的问答对时长为4.6分钟。数据集通过自动生成的层次化树结构构建,确保了问答对的高质量和时间戳的精确标注。数据集的内容涵盖了多样化的真实世界场景,适用于长视频和流媒体视频的理解任务,旨在解决现有数据集在时间标注、场景多样性和问答精确性方面的不足。LongViTU的应用领域包括视频问答、长视频理解以及流媒体视频分析等。
LongViTU is a large-scale dataset for long-form video understanding, jointly created by research teams from Peking University, BIGAI, and the National University of Singapore. This dataset contains approximately 121,000 high-quality question-answer pairs, covering around 900 hours of video content, with the average duration of the question-answer pairs per video being 4.6 minutes. The dataset is constructed using automatically generated hierarchical tree structures, which ensures the high quality of the question-answer pairs and the precision of timestamp annotations. Its content covers diverse real-world scenarios, and is applicable to long-form video and streaming video understanding tasks, aiming to address the limitations of existing datasets in terms of temporal annotation, scene diversity, and the accuracy of question-answer pairs. The application fields of LongViTU include video question answering, long-form video understanding, streaming video analysis, and other related fields.
提供机构:
北京大学, BIGAI, 新加坡国立大学
创建时间:
2025-01-09
搜集汇总
数据集介绍
构建方式
LongViTU数据集的构建采用了分层次的视频树结构,结合了自修正机制以确保高质量的问题-答案对生成。首先,从Ego4D数据集中提取视频帧,并通过InternLM-XComposer2模型进行密集标注,生成帧级别的描述和时间戳。接着,利用GPT-4对帧级别的描述进行提炼,生成事件级别的描述,并将相关事件合并为段级别的描述,最终形成层次化的视频树结构。通过滑动窗口操作,从视频子树中生成问题-答案对,并利用GPT-4进行自修正,确保问题与视频内容的一致性。
特点
LongViTU数据集具有长时上下文、丰富的知识推理和显式时间戳标注等特点。其平均证书长度达到276.8秒(约4.6分钟),涵盖了常识、因果关系、规划等多种推理类型。数据集还提供了精细的时空分类,问题类型包括对象、属性、位置、动作等,并支持开放式的精确问答。此外,LongViTU是首个公开的长视频问答数据集,具备显式的时间戳标注,能够有效支持长视频和流媒体视频的理解任务。
使用方法
LongViTU数据集可用于长视频理解和指令调优任务。用户可以通过该数据集对开源和商业视觉语言模型进行监督微调,提升其在长视频问答任务中的表现。数据集提供了训练、验证和测试集,分别包含101k、14k和6k个问题-答案对。用户可以利用数据集中的显式时间戳标注,精确识别视频中的关键时刻,并通过自修正机制生成高质量的问题-答案对。此外,LongViTU还可作为基准数据集,用于评估模型在长视频理解任务中的表现。
背景与挑战
背景概述
LongViTU 是一个专注于长视频理解的大规模数据集,由北京大学、BIGAI 和新加坡国立大学的研究团队于2025年提出。该数据集包含约121,000个问答对,覆盖约900小时的视频内容,旨在解决长视频理解中的复杂问题,如时空推理、常识推理和事件规划等。LongViTU 的独特之处在于其采用了层次化的视频树结构,并引入了自修正机制,确保问答对的高质量生成。该数据集不仅为长视频理解提供了基准,还推动了开源和商业模型在该领域的性能提升。
当前挑战
LongViTU 面临的挑战主要体现在两个方面。首先,长视频理解本身具有复杂性,模型需要处理长时间跨度的时空信息,捕捉关键事件并生成准确的问答对。其次,数据集的构建过程中,研究人员需要克服视频内容冗余、时间标注不精确等问题。尽管采用了层次化结构和自修正机制,生成高质量问答对仍然需要大量的计算资源和时间。此外,现有的模型在处理长视频时,往往面临输入长度限制和视觉信息压缩的挑战,导致性能下降。这些挑战使得长视频理解成为一个极具研究价值的领域。
常用场景
经典使用场景
LongViTU数据集在长视频理解领域具有广泛的应用,尤其是在视频问答(VQA)任务中。通过其层次化的视频树结构和显式的时间戳标注,LongViTU能够支持对长视频内容的细粒度时空分析。经典的使用场景包括对视频中的物体、属性、位置、动作等进行问答,帮助模型理解视频中的复杂事件序列。例如,模型可以通过LongViTU回答诸如“视频中的人物在厨房里做了什么?”或“视频中某个物体的颜色是什么?”等问题。
解决学术问题
LongViTU解决了长视频理解中的多个关键学术问题。首先,它通过显式的时间戳标注,解决了传统数据集中缺乏精确时间标注的问题,使得模型能够更准确地定位视频中的关键事件。其次,LongViTU的长证书长度(平均4.6分钟)使得模型能够处理更长的视频片段,克服了短数据集在处理长视频时的局限性。此外,其细粒度的分类和开放式的精确问答机制,使得模型能够更好地理解视频中的复杂时空关系,推动了长视频理解领域的研究进展。
衍生相关工作
LongViTU的推出催生了一系列相关研究工作,尤其是在长视频理解和多模态学习领域。基于LongViTU,研究人员开发了多个先进的视频理解模型,如LongVU和Video-LLaVA,这些模型在长视频问答任务中表现出色。此外,LongViTU还推动了长上下文语言模型的发展,如GPT-4-turbo和ChatGLM,这些模型在处理长视频内容时表现出更强的能力。LongViTU的成功也激发了更多关于视频记忆机制和流式视频处理的研究,为未来的长视频理解技术奠定了基础。
以上内容由遇见数据集搜集并总结生成


