RAG 检索质量评估数据集
收藏DataCite Commons2025-09-06 更新2025-09-08 收录
下载链接:
https://figshare.com/articles/dataset/RAG__/30067627/1
下载链接
链接失效反馈官方服务:
资源简介:
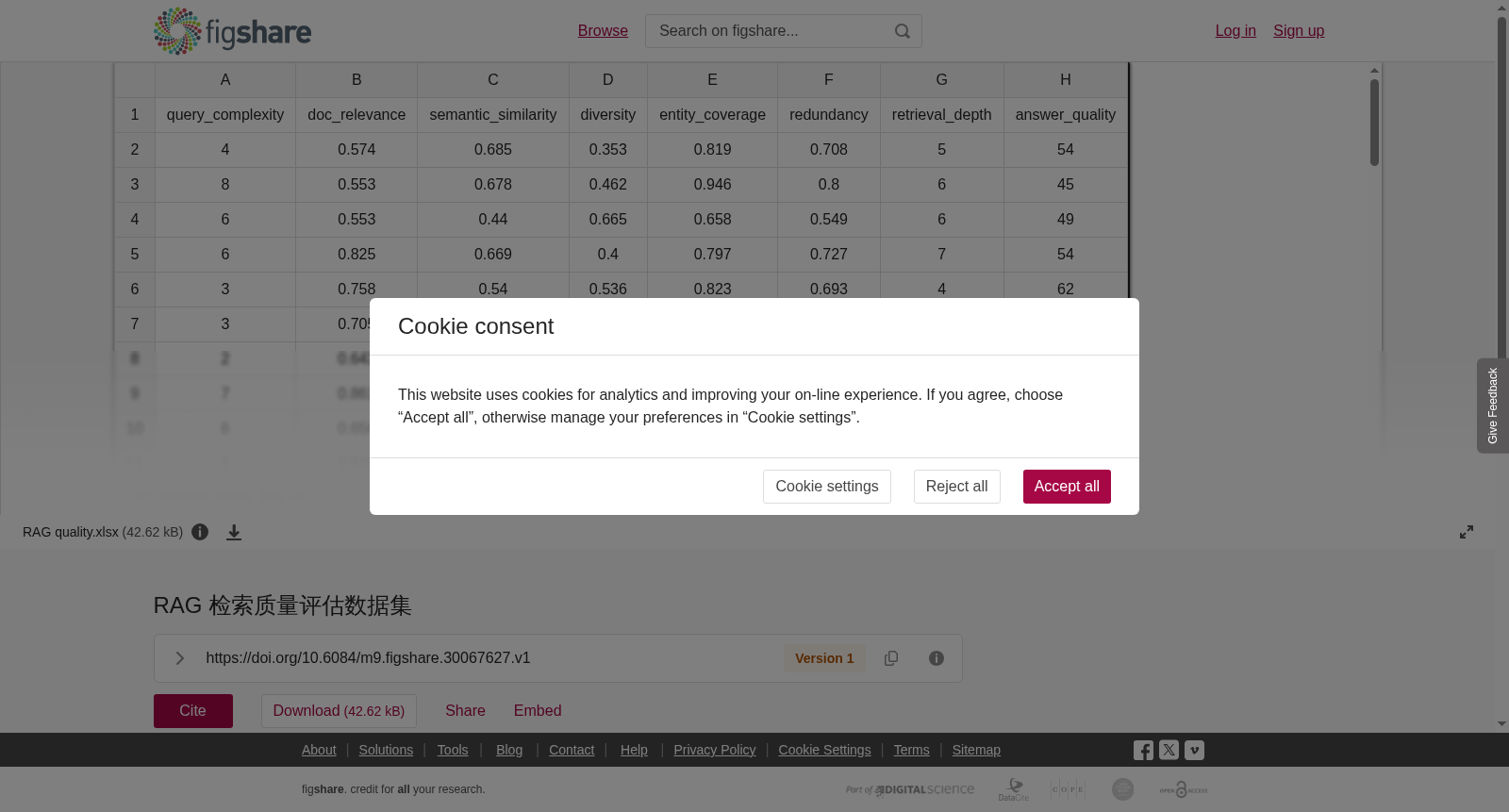
该数据集旨在评估检索质量对检索增强生成(RAG)系统生成效果的影响,共包含728个样本。在数据收集过程中,我们从公开的问答数据集(包括SQuAD、Natural Questions和WebQuestions)中筛选出728个不同复杂程度的真实用户查询,涵盖事实问答、多跳推理、观点查询等多种类型。对于每个查询,使用基于 BM25 和 Sentence-BERT 的混合检索策略从维基百科语料库中获取相关文档,每次查询检索 5 到 15 个文档。在数据处理阶段,我们通过人工标注和自动计算相结合的方式,提取了8个关键特征:3名标注者独立评估查询复杂度(1-10分)并取平均值。文档相关性是通过将基于注释 (0-1) 的相关性分数与预训练模型的预测值融合而获得的。通过Sentence-BERT计算文档之间的语义相似度,结合基于TF-IDF的多样性评分生成检索多样性特征。使用实体链接工具自动计算关键实体的覆盖率;根据文档内容的重叠程度量化信息冗余;将实际检索到的文档数量记录为检索深度;最后,五位专家将从相关性、准确性和完整性(0 到 100 分)三个维度对生成的响应进行评分,作为最终的质量标签。所有特征值均经过标准化处理,确保数据范围合理且符合实际应用场景,为RAG系统检索策略的优化和质量评估提供了真实可靠的研究依据。
This dataset is designed to assess the impact of retrieval quality on the generation performance of Retrieval-Augmented Generation (RAG) systems, consisting of 728 samples in total. During data collection, we screened 728 real-world user queries with varying levels of complexity from open-domain question answering datasets including SQuAD, Natural Questions, and WebQuestions, covering diverse types such as factual question answering, multi-hop reasoning, and opinion-seeking queries. For each query, a hybrid retrieval strategy combining BM25 and Sentence-BERT was employed to retrieve relevant documents from the Wikipedia corpus, with 5 to 15 documents retrieved per query. In the data processing phase, 8 key features were extracted via a hybrid approach of manual annotation and automatic computation: 1) Query Complexity: Three annotators independently rated the query complexity on a 1-10 scale, and the average score was taken as the final value; 2) Document Relevance: Obtained by fusing the annotation-based relevance score (ranging from 0 to 1) with the prediction output of a pre-trained model; 3) Semantic Similarity Between Retrieved Documents: Calculated using Sentence-BERT to measure pairwise semantic similarity among the retrieved documents; 4) Retrieval Diversity: Generated by combining the semantic similarity scores and the TF-IDF-based diversity score of the retrieved document set; 5) Key Entity Coverage: Automatically computed using an entity linking tool; 6) Information Redundancy: Quantified based on the degree of content overlap between the retrieved documents; 7) Retrieval Depth: Recorded as the actual number of documents retrieved for each query; 8) Final Response Quality: Scored by five experts across three dimensions—relevance, accuracy, and completeness—on a 0-100 scale, which serves as the ground-truth quality label. All feature values were standardized to ensure a reasonable data range that aligns with real-world application scenarios, providing reliable and authentic research support for the optimization and quality evaluation of RAG system retrieval strategies.
提供机构:
figshare
创建时间:
2025-09-06
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集包含728个样本,用于评估RAG系统的检索质量对生成效果的影响,涵盖了多种查询类型,并通过人工标注和自动计算提取了8个关键特征。
以上内容由遇见数据集搜集并总结生成


