tahsinsoyak/gsm8k-tr-finetune-full
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/tahsinsoyak/gsm8k-tr-finetune-full
下载链接
链接失效反馈官方服务:
资源简介:
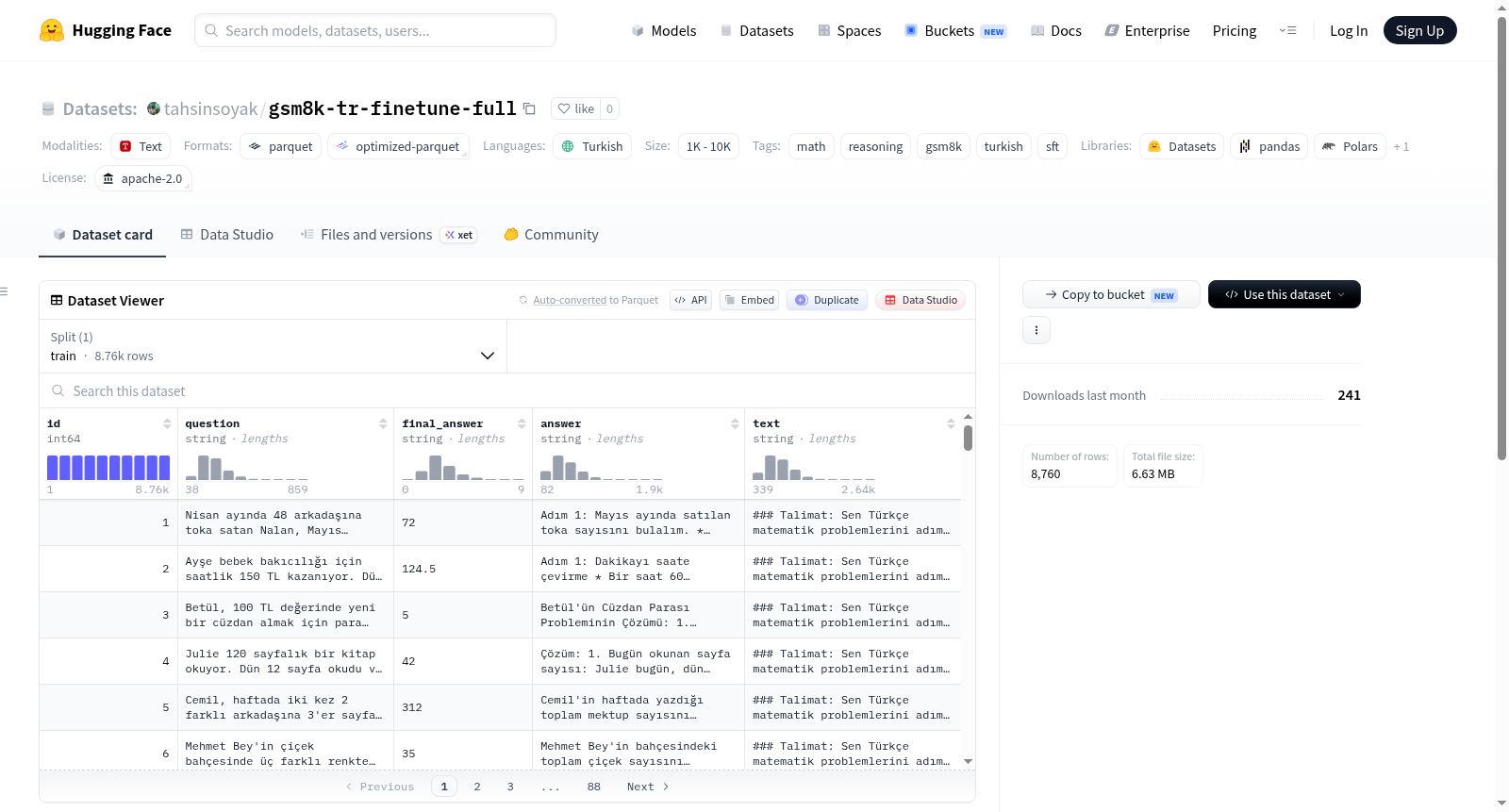
GSM8K-TR Finetune Full (SFT)是一个土耳其语的数学推理数据集,用于监督微调。它源自`bezir/gsm8k-tr`的`test`分割,并排除了与`tahsinsoyak/gsm8k-tr-benchmark`中100个保留问题匹配的项目以避免评估泄漏。数据集包含8760行,没有配置。数据模式包括id(原始索引)、question(问题)、answer(包含逐步推理的完整答案)、final_answer(仅数字最终答案)和text(为TRL SFTTrainer预构建的字符串)。
GSM8K-TR Finetune Full (SFT) is a Turkish-language math reasoning dataset for supervised fine-tuning. It is derived from the `test` split of `bezir/gsm8k-tr`, with items matching the 100 holdout questions from `tahsinsoyak/gsm8k-tr-benchmark` excluded to prevent evaluation leakage. The dataset contains 8760 rows, with no configs. The schema includes id (original index), question (question), answer (full step-by-step rationale ending with `#### <number>`), final_answer (numeric final answer only), and text (precomposed SFT string for TRL SFTTrainer).
提供机构:
tahsinsoyak
搜集汇总
数据集介绍
构建方式
该数据集源于土耳其语数学推理领域,为GSM8K数据集的土耳其语版本微调细分。其构建基于`bezir/gsm8k-tr`测试集拆分,通过剔除与`tahsinsoyak/gsm8k-tr-benchmark`中100道保留问题相匹配的样本,有效避免了评估泄露。最终形成仅含训练集的单配置数据集,共计8760条样本,每个样本从原始测试集中基于1基索引提取。
使用方法
使用该数据集时,可直接加载其单训练拆分进行监督微调。优先利用`text`字段,该字段已按SFTTrainer格式预制,支持直接输入训练循环。若需精细控制,可解析`answer`字段获取逐步推理,或提取`final_answer`作为数值目标。适用于微调土耳其语模型以增强其数学推理能力,尤其在避免评估数据污染的场景下,可作为可靠微调基准集。
背景与挑战
背景概述
GSM8K-TR Finetune Full 数据集创建于近年来,由研究人员基于土耳其语数学推理需求开发,源自 bezir/gsm8k-tr 的测试集,并经 tahsinsoyak/gsm8k-tr-benchmark 的100道保留问题筛选以避免评估泄露。核心研究问题聚焦于提升大语言模型在土耳其语数学问题上的推理能力与监督微调效果。该数据集在自然语言处理与数学推理交叉领域具有重要影响力,为多语言推理模型评估提供了标准化资源,尤其填补了土耳其语数学数据集稀缺的空白,推动了非英语推理任务的研究进展。
当前挑战
该数据集主要挑战体现在领域问题与构建过程两方面。领域问题方面,数学推理任务要求模型具备符号理解、多步推导与数值精度,而土耳其语语法结构复杂,词汇形态丰富,增加了模型解析自然语言问题的难度。构建过程方面,需严格确保数据质量,包括从原始测试集排除与基准集重叠的100道问题以防数据泄露,同时保证8760条样本的答案格式一致,如步进推理链需以'#### <数字>'结尾,且数值答案必须准确提取,处理中需应对噪声与翻译不一致性,以维护监督微调数据的可靠性与有效性。
常用场景
经典使用场景
GSM8K-TR Finetune Full数据集作为土耳其语数学推理领域的标杆性资源,其最经典的使用场景在于构建和微调面向土耳其语的大规模语言模型,以提升模型在数学文字题上的多步推理能力。该数据集包含了8760条精心构造的监督微调样本,每条样本均提供了完整的分步推理过程与最终数值答案,特别适用于采用Supervised Fine-Tuning(SFT)范式的训练流程。研究者通常利用该数据集对预训练语言模型进行领域适配,使其能够理解土耳其语语境下的数学问题表述,并生成逻辑严密的解题步骤,从而在数学推理任务中达到更高的准确率。
解决学术问题
在学术研究层面,该数据集的核心价值在于解决了土耳其语低资源环境下数学推理任务缺乏高质量训练数据的难题。GSM8K-TR的构建不仅填补了土耳其语数学语料库的空白,还通过严格剔除与基准测试集重合的样本,有效防止了评估泄漏,为模型泛化能力的公正测评提供了保障。借助该数据集,研究人员能够深入探索多语言模型在算术推理中的迁移学习效果、推理步骤的连贯性生成以及最终答案的精准提取等关键问题。这一工作的意义在于推动了非英语语言在复杂推理任务上的研究进展,为构建真正多语言、多文化包容的智能系统奠定了数据基础。
实际应用
在实际应用场景中,GSM8K-TR Finetune Full数据集赋能了土耳其语智能教育辅导系统的开发。基于该数据集微调的语言模型可以被集成到在线学习平台或虚拟助手中,为学生提供个性化的数学解题指导,自动生成分步解析,帮助理解复杂的数学模型。此外,该数据集还可用于构建土耳其语的自动化试题解答与批改系统,减轻教师重复性劳动,提升教育效率。在金融、工程等需要数值推理的专业领域,经过该数据集训练的模型也能辅助进行数据分析和决策支持,展现出广泛的实用价值。
数据集最近研究
最新研究方向
GSM8K-TR Finetune Full 数据集聚焦于将数学推理能力迁移至低资源语言土耳其语的前沿方向,通过构建高质量的监督微调(SFT)语料库,推动多语言大模型在复杂数学问题上的推理泛化。该数据集严格剔除了评估集泄露样本,确保训练与测试的独立性,从而支持对模型推理能力的鲁棒性评估。结合当前大模型在多语言推理任务中的热点研究,如跨语言链式思考(CoT)和少样本学习,该数据集为探索非英语环境下的数学问题求解提供了关键基准,有助于缓解语言资源不均导致的推理性能差距,对提升全球范围内教育科技与智能辅导系统的公平性具有深远意义。
以上内容由遇见数据集搜集并总结生成


