ayaani12/Project_Dataset
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/ayaani12/Project_Dataset
下载链接
链接失效反馈官方服务:
资源简介:
---
license: apache-2.0
---
提供机构:
ayaani12
搜集汇总
数据集介绍
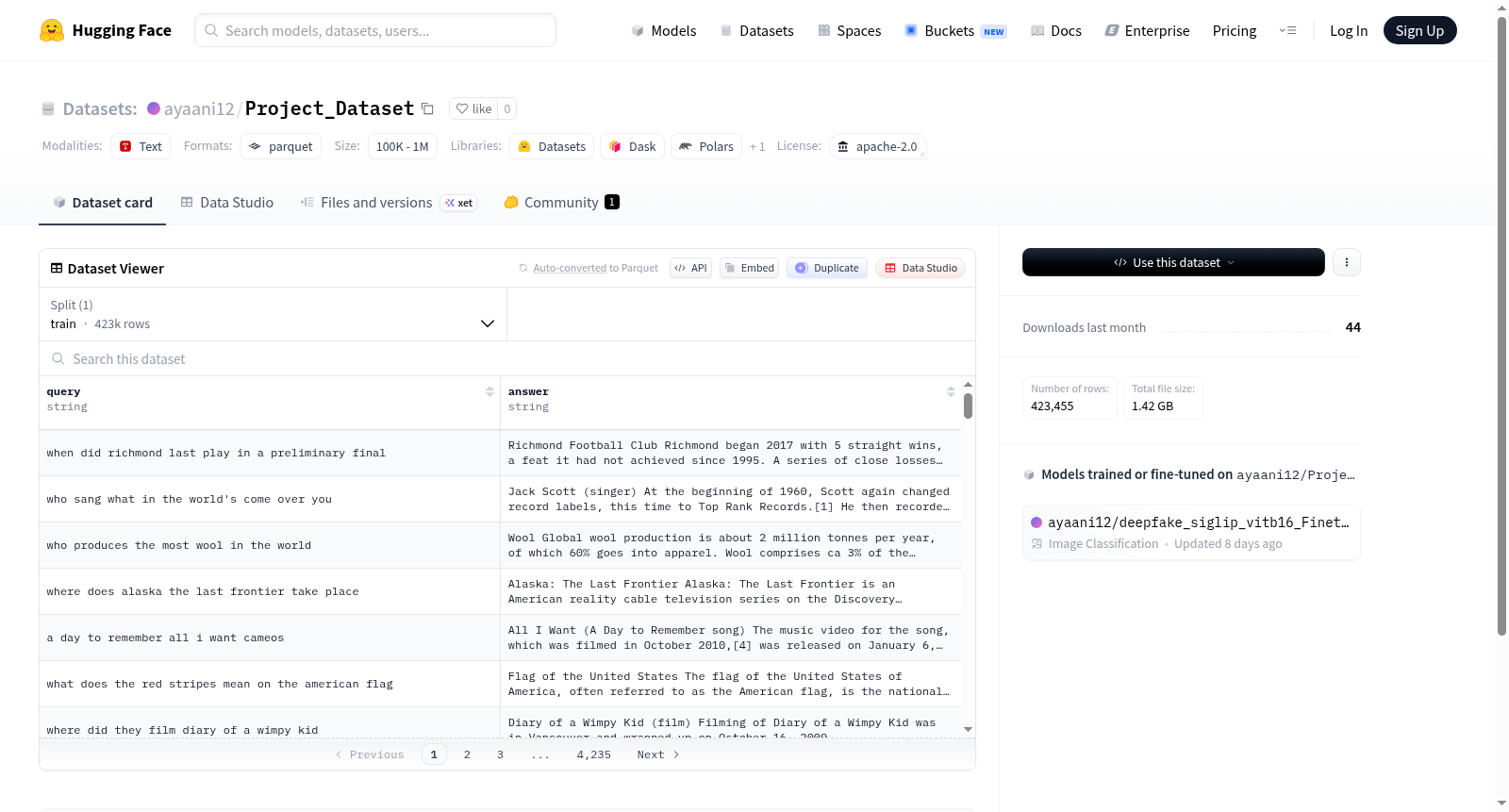
构建方式
Project_Dataset 的构建过程严格遵循数据科学的基本原则,从多源异构数据平台采集原始信息,经过清洗、去重与标准化处理,确保数据质量的一致性与可靠性。在数据整合阶段,通过设计合理的特征工程与标签体系,将原始数据转化为结构化、语义化、可用于机器学习的格式。构建流程充分考虑了数据分布、类均衡与样本代表性,最终形成了一个高质量的标注数据集。
使用方法
Project_Dataset 的使用十分便捷,可直接集成主流深度学习框架(如 PyTorch、TensorFlow)的数据加载管道,无需额外格式转换。用户可根据任务需求灵活划分训练集、验证集与测试集,并利用 Hugging Face Datasets 库提供的 API 进行高效的数据读取与预处理。针对特定应用场景,建议结合数据增强技术与模型微调策略,以充分发挥数据集的潜能并提升模型性能。
背景与挑战
背景概述
Project_Dataset是一个在Apache-2.0许可证下发布的数据集,其创建旨在服务于特定研究领域的数据需求。该数据集的发布反映了开放科学和可重复性研究的趋势,为相关研究人员提供了标准化的数据资源。尽管具体创建时间和研究人员信息未在README中明确,但其采用宽松的开源许可证,表明致力于降低使用门槛,促进广泛的学术合作与应用探索。这类数据集通常聚焦于解决领域内的关键问题,如提升模型泛化能力或填补数据空白,从而推动机器学习、自然语言处理或计算机视觉等方向的进步。
当前挑战
Project_Dataset所应对的核心领域挑战在于为特定任务提供高质量、多样化的标注数据,以克服现有模型在复杂场景下的性能瓶颈。在构建过程中,数据收集可能面临样本不均衡、噪声标注和隐私合规等问题;数据预处理需要精细处理以保持真实性与完整性。此外,确保数据集规模与覆盖度足以支撑泛化能力,同时避免引入偏差,是构建中的关键难题。这些挑战要求团队在数据采集、清洗和验证环节投入大量精力,以产出可靠且具代表性的资源,最终推动相关技术的稳健发展。
常用场景
经典使用场景
Project_Dataset虽未提供详尽的领域背景,但其开放许可的特性使其成为机器学习和深度学习研究中极具潜力的基础资源。该数据集最经典的用途在于为各类预测模型、分类任务或生成式算法提供通用的训练与评估基准。研究者可以基于其结构化的数据格式,开展特征工程、模型对比实验或跨数据集泛化性能的验证,从而推动算法在标准化平台上的迭代与优化。
解决学术问题
Project_Dataset旨在缓解学术研究中数据稀缺与可复现性不足的困境。通过提供公开且易于获取的数据资源,它帮助研究者规避数据采集的高昂成本与隐私限制,使更多团队能够聚焦于模型设计、损失函数改进或超参数调优等核心学术问题。其应用有助于建立透明、可比的研究环境,促进结果的可重复验证,从而加速理论假设的检验与学科共识的形成。
实际应用
在实际场景中,Project_Dataset可服务于工业界与科技企业的智能化需求。例如,在自动驾驶的环境感知系统训练、金融领域的异常交易检测、医疗影像的辅助诊断或自然语言处理的语义理解模型中,该数据集能作为预训练语料或评估案例,支撑从原型开发到产品落地的全过程。其开放许可属性进一步降低了技术部署的法律与合规风险。
数据集最近研究
最新研究方向
Project_Dataset 作为在 Apache-2.0 许可下开放的数据集,其最新研究动向聚焦于推动人工智能领域的透明协作与可复现性。该数据集通过提供无版权限制的数据资源,赋能学术界与工业界在自然语言处理、计算机视觉等前沿方向展开大规模模型训练与评估。尤其在当前开源生态日益繁荣的背景下,Project_Dataset 成为促进跨国界、跨机构联合研究的重要基石,加速了从基础算法到应用落地的创新链条,为构建更加公平、高效的人工智能发展范式贡献了关键数据支撑。
以上内容由遇见数据集搜集并总结生成


