Beemo
收藏arXiv2024-11-07 更新2024-11-08 收录
下载链接:
https://huggingface.co/datasets/toloka/beemo
下载链接
链接失效反馈官方服务:
资源简介:
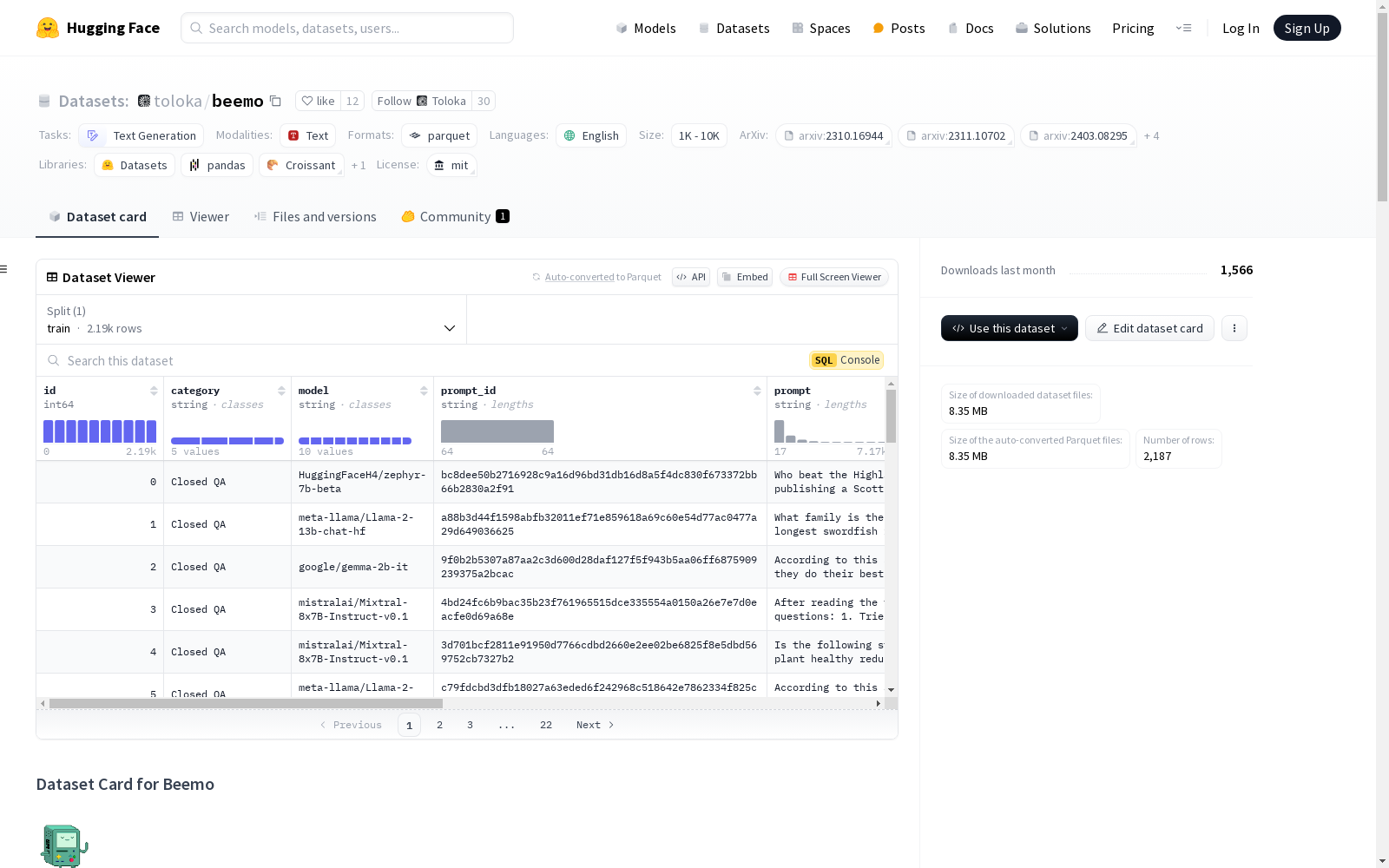
Beemo数据集由托洛卡人工智能创建,包含19.6k条文本,涵盖人类编写、机器生成和专家编辑的内容。数据集内容丰富,包括创意写作、重写、总结和开放及封闭式问答等多种用例。创建过程涉及使用No Robots数据集作为提示和人类编写响应的来源,生成十种开源指令微调的大型语言模型响应,并由专家和先进的语言模型进行编辑。Beemo数据集主要用于评估机器生成文本检测器在多作者场景下的表现,旨在解决文本真实性和潜在恶意使用的问题。
The Beemo dataset, developed by Toloka AI, consists of 19.6k text samples covering human-written, machine-generated, and expert-edited content. The dataset includes a diverse range of use cases, such as creative writing, rewriting, summarization, as well as both open-ended and closed-domain question answering. Its construction utilized the No Robots dataset as the source for prompts and human-written responses, generated responses from ten open-source instruction-tuned large language models, and underwent editing by human experts and state-of-the-art language models. The Beemo dataset is primarily designed to evaluate the performance of machine-generated text detectors in multi-author scenarios, aiming to address issues related to text authenticity and potential malicious utilization of generated content.
提供机构:
托洛卡人工智能
创建时间:
2024-11-07
搜集汇总
数据集介绍
构建方式
Beemo数据集的构建过程融合了多种先进的自然语言处理技术。首先,从No Robots数据集中提取指令和人类编写的响应,作为基准数据。随后,利用十个开源的指令微调大型语言模型(LLMs)生成相应的文本。为了模拟实际应用场景中的多作者协作,专家团队对这些机器生成的文本进行了编辑,以确保其自然流畅性和事实准确性。此外,通过两个最先进的LLMs使用多种编辑提示进行二次编辑,最终形成了包含19.6k文本的Beemo数据集,涵盖了从创意写作到摘要等多种应用场景。
特点
Beemo数据集的主要特点在于其多作者编辑的复杂性,这使得数据集能够更真实地反映实际应用中的人机协作场景。数据集包含了人类编写、机器生成以及经过专家和LLMs编辑的文本,提供了多样化的编辑类型和风格。此外,Beemo数据集的规模和多样性使其成为评估机器生成文本检测器性能的理想平台,特别是在多作者场景下的检测能力。
使用方法
Beemo数据集适用于多种自然语言处理任务,特别是机器生成文本的检测和分类。研究者和开发者可以利用该数据集训练和评估机器生成文本检测器,探索其在不同编辑类型和应用场景下的表现。此外,Beemo数据集还可用于研究文本编辑策略和人类与机器协作的优化方法。通过分析数据集中的编辑模式和检测结果,可以进一步推动相关领域的发展和应用。
背景与挑战
背景概述
随着大型语言模型(LLMs)的迅速发展,机器生成文本(MGTs)的数量显著增加,导致文本作者身份的模糊化。现有的MGT基准主要包含单一作者的文本(人类撰写和机器生成),未能捕捉到更实际的多作者场景,即用户对LLM响应进行细化以实现自然流畅、连贯性和事实正确性。为此,我们引入了专家编辑的机器生成输出基准(Beemo),包含6.5k人类撰写的文本和由十种指令微调LLMs生成的文本,并由专家编辑以适应各种用例,从创意写作到摘要。此外,Beemo还包含13.1k机器生成和LLM编辑的文本,允许在不同编辑类型下进行多样化的MGT检测评估。
当前挑战
Beemo数据集在构建过程中面临多个挑战。首先,如何有效地模拟多作者场景,确保数据集能够真实反映用户对LLM输出的编辑需求。其次,专家编辑的质量控制和一致性问题,确保编辑后的文本在自然流畅、连贯性和事实正确性方面达到预期标准。此外,数据集的多样性和覆盖范围也是一个挑战,需要涵盖从创意写作到摘要等多种用例,以确保检测模型的泛化能力。最后,如何处理和评估LLM编辑的文本,确保其在检测模型中的表现与人类编辑的文本相当,也是一个重要的研究问题。
常用场景
经典使用场景
Beemo数据集的经典使用场景在于评估和提升机器生成文本(MGT)检测器的性能。通过包含由人类编写、机器生成以及专家编辑的文本,Beemo提供了一个多作者场景的基准,使得研究人员能够更准确地评估检测器在不同编辑类型下的表现,从而推动MGT检测技术的发展。
衍生相关工作
基于Beemo数据集,研究者们已经开展了一系列相关工作,包括开发新的MGT检测算法、评估现有检测器的性能以及探索多作者文本的特征分析。这些工作不仅提升了检测技术的准确性和鲁棒性,还为未来的研究提供了丰富的数据支持和理论基础。
数据集最近研究
最新研究方向
在大型语言模型(LLMs)快速发展的背景下,Beemo数据集聚焦于多作者场景下的机器生成文本(MGTs)检测。最新研究方向主要集中在通过专家编辑和LLM自我编辑的文本,以评估和提升MGT检测器的性能。Beemo数据集不仅包含了人类编写的文本和LLM生成的文本,还引入了专家和LLM对生成文本的编辑版本,从而提供了更为复杂和实际的检测环境。这一研究方向对于识别和防范机器生成文本在新闻、社交媒体等领域的滥用具有重要意义,同时也推动了MGT检测技术在多作者场景下的应用和优化。
相关研究论文
- 1Beemo: Benchmark of Expert-edited Machine-generated Outputs托洛卡人工智能 · 2024年
以上内容由遇见数据集搜集并总结生成


