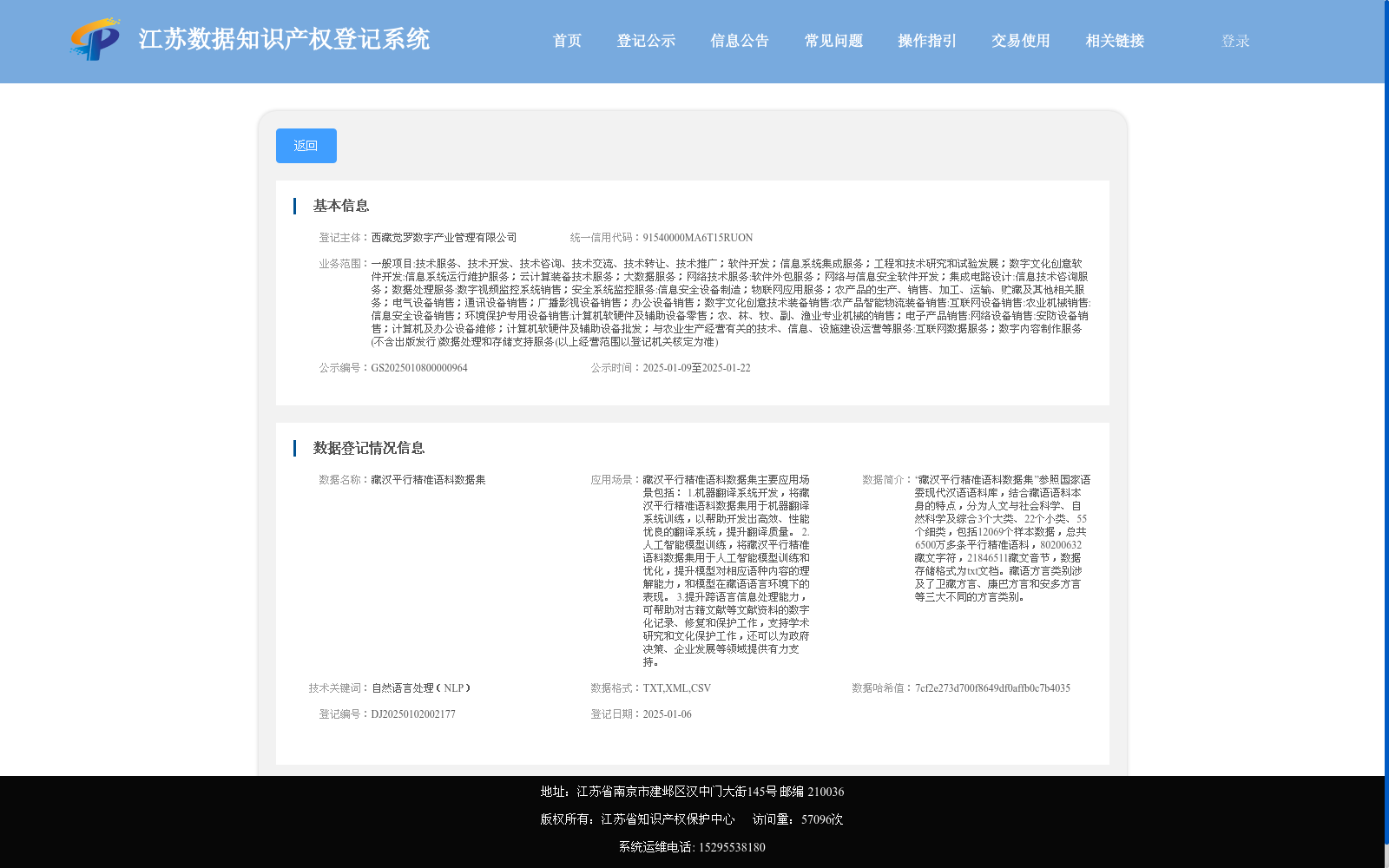
藏汉平行精准语料数据集
收藏江苏数据知识产权登记系统2025-01-08 更新2025-01-25 收录
下载链接:
https://dataip.jsipp.cn/#/changeDetialCertical?pType=登记&cType=登记&id=b9a142855d76f05820851377caa682b2
下载链接
链接失效反馈官方服务:
资源简介:
“藏汉平行精准语料数据集”参照国家语委现代汉语语料库,结合藏语语料本身的特点,分为人文与社会科学、自然科学及综合3个大类、22个小类、55个细类,包括12069个样本数据,总共6500万多条平行精准语料,80200632藏文字符,21846511藏文音节,数据存储格式为txt文档。藏语方言类别涉及了卫藏方言、康巴方言和安多方言等三大不同的方言类别。
"The Tibetan-Chinese Parallel Precision Corpus Dataset" is constructed with reference to the Modern Chinese Corpus under the National Language Commission, and categorized into three primary categories: humanities and social sciences, natural sciences, and comprehensive studies, based on the inherent characteristics of Tibetan language corpora. These primary categories are further subdivided into 22 secondary categories and 55 tertiary categories. The dataset encompasses 12,069 sample entries, with a total of over 65 million parallel precision corpus units, 80,200,632 Tibetan characters, and 21,846,511 Tibetan syllables. All data is stored in TXT document format. The dataset covers three major Tibetan dialect groups: Ü-Tsang dialect, Kham dialect, and Amdo dialect.
提供机构:
西藏觉罗数字产业管理有限公司
搜集汇总
数据集介绍
特点
藏汉平行精准语料数据集包含6500万条平行语料,覆盖藏语三大方言,分为人文社科、自然科学及综合三大类,适用于机器翻译、AI模型训练及跨语言信息处理。数据格式为TXT、XML、CSV,支持文化保护与学术研究。
以上内容由遇见数据集搜集并总结生成


