zxbsmk/webnovel_cn
收藏Hugging Face2023-08-09 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/zxbsmk/webnovel_cn
下载链接
链接失效反馈官方服务:
资源简介:
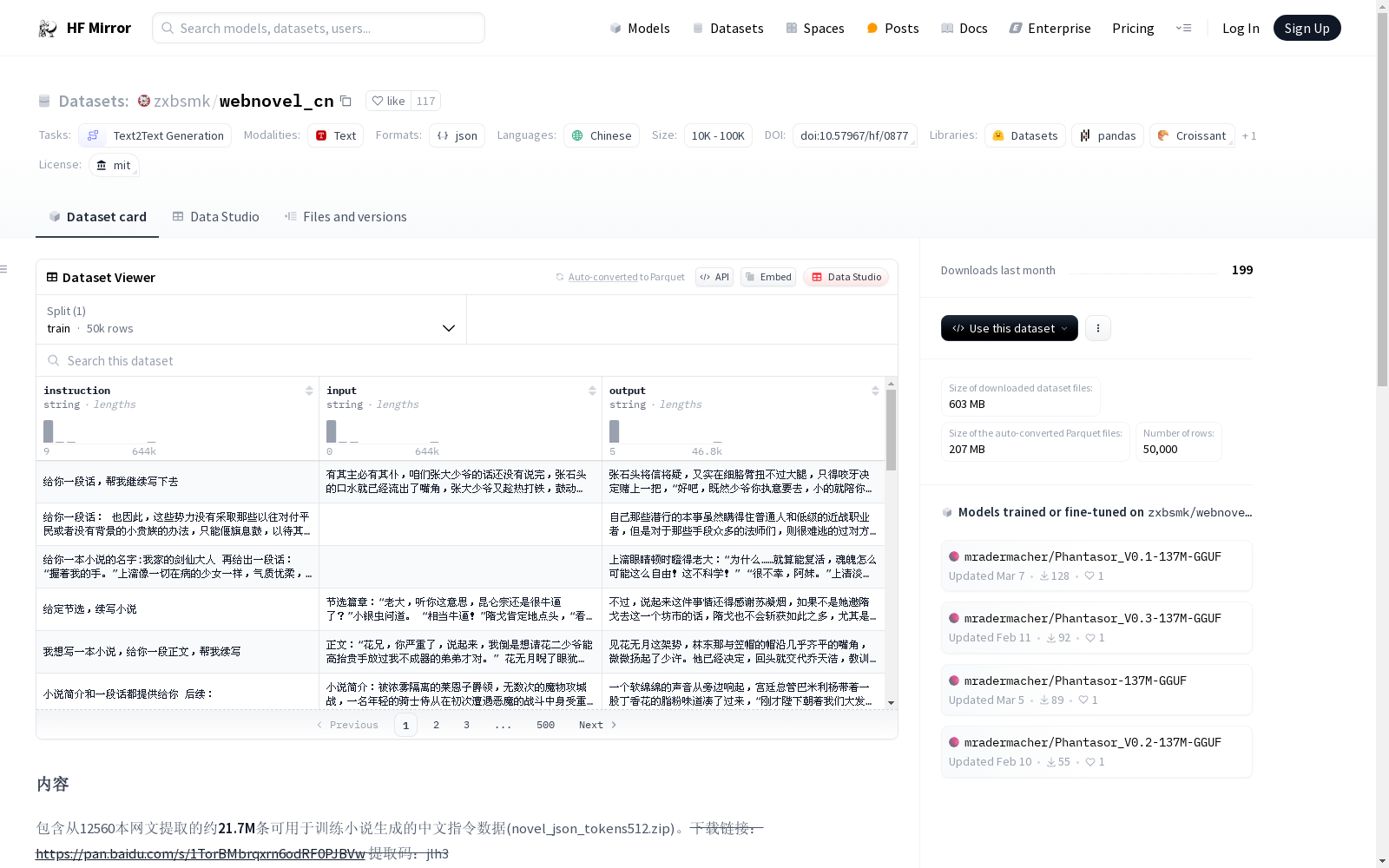
该数据集包含从12560本网文提取的约21.7M条中文指令数据,用于训练小说生成。此外,还有一个包含50k条数据的子集。每个样本包含三个字段:instruction(指令)、input(输入)和output(输出)。数据生成基于五种指令类型,包括给定标题生成简介、给定标题和简介生成开头、给定简介和一段文本生成后续文本等。数据集仅允许用于研究目的,不得用于商业或其他有害用途。
This dataset contains approximately 21.7 million Chinese instruction data entries extracted from 12,560 online literary works, intended for novel generation training. In addition, there is a subset containing 50,000 data entries. Each sample consists of three fields: instruction, input, and output. The data generation is based on five types of instructions, including generating a summary given a title, generating an opening given a title and a summary, generating subsequent text given a summary and a passage of text, among others. This dataset is only permitted for research purposes and shall not be used for commercial or other harmful purposes.
提供机构:
zxbsmk
原始信息汇总
数据集概述
数据集信息
- 许可证: MIT
- 任务类别: 文本到文本生成
- 语言: 中文
- 数据集大小: 10M<n<100M
数据集特征
- instruction: 字符串类型,指令信息
- input: 字符串类型,输入信息
- output: 字符串类型,输出信息
数据集内容
- 主要数据集: 包含从12560本网文中提取的约21.7M条中文指令数据,用于训练小说生成。
- 子集: 包含50k条数据的子集,其中输入和输出都不多于512 tokens。
样例说明
数据集中的样例展示了五种不同的指令生成数据的方式,包括:
- 给定标题,直接生成简介。
- 给定标题和简介,生成开头。
- 给定简介和一段文本,生成后续文本。
- 给定标题和一段文本,生成后续文本。
- 给定一段文本,生成后续文本。
使用限制
- 仅允许将此数据集及使用此数据集生成的衍生物用于研究目的,不得用于商业,以及其他会对社会带来危害的用途。
- 本数据集不代表任何一方的立场、利益或想法,无关任何团体的任何类型的主张。因使用本数据集带来的任何损害、纠纷,本项目不承担任何责任。
搜集汇总
数据集介绍
构建方式
该数据集名为zxbsmk/webnovel_cn,其构建基于12560本网络小说,从中提取约21.7M条中文指令数据,以及一个包含50k条数据的子集。数据集通过模拟小说创作过程中的不同指令生成任务,如根据标题生成简介、开头,或根据现有文本生成后续内容,以此构建出丰富的文本生成训练数据。
使用方法
使用该数据集时,研究者可以依据数据集中的指令、输入和输出字段进行模型的训练和评估。数据集适用于文本生成领域的模型训练,特别是针对中文小说创作。用户需遵守使用限制,仅将数据集用于研究目的,并在使用过程中确保数据的合法合规使用。
背景与挑战
背景概述
zxbsmk/webnovel_cn数据集,诞生于我国网络文学研究领域的黄金时期,由专业的数据科学家和研究人员共同构建。该数据集汇集了从12560本网文提取的约21.7M条中文指令数据,旨在推动自然语言处理任务中的文本生成技术研究。其创建背景主要来源于对网络文学创作模式及文本生成算法的深入研究,自推出以来,在自然语言处理、机器学习等领域产生了广泛影响,成为学者们研究文本生成任务的重要资源。
当前挑战
该数据集在构建过程中面临的挑战主要包括:如何从海量的网络文学作品中提取出具有代表性的文本数据,以及如何确保所提取的数据能够满足文本生成任务的需求。此外,在所解决的领域问题方面,该数据集面临的挑战包括如何生成符合文学创作规范的文本,以及如何保证生成的文本在语义和语法上的正确性。同时,数据集的使用限制也提出了挑战,即如何在确保研究目的纯粹性的同时,避免数据集被用于不当用途,对社会造成潜在危害。
常用场景
经典使用场景
在自然语言处理领域,尤其是文本生成任务中,zxbsmk/webnovel_cn数据集以其丰富的小说生成指令和对应的文本输出来填补了中文创作指令数据的空白。该数据集的经典使用场景主要在于训练和评估文本到文本生成的模型,如生成小说的开头、续写故事情节、根据标题生成简介等,为研究者和开发者提供了一个实践和创新平台。
解决学术问题
zxbsmk/webnovel_cn数据集解决了中文自然语言处理领域中的多个学术研究问题,包括但不限于文本生成中的上下文连贯性、指令遵循度以及创造性文本生成的可能性。通过该数据集,研究者能够探索和提升模型的生成质量,进而推动文本生成技术的进步,对学术研究和应用发展产生了积极影响。
实际应用
在实际应用场景中,zxbsmk/webnovel_cn数据集可以被用于开发智能写作助手、自动小说生成工具等,为内容创作提供辅助。此外,该数据集也可用于训练娱乐型聊天机器人,以提升其故事叙述和内容创作的能力,为用户提供更为丰富的互动体验。
数据集最近研究
最新研究方向
在自然语言处理领域,尤其是文本生成任务中, zxbsmk/webnovel_cn 数据集的构建为研究者和开发者提供了一个丰富的中文小说生成指令数据资源。该数据集的最新研究方向主要集中在利用这些指令数据提升文本生成模型的智能性和创造性。通过深度学习模型训练,研究者试图使模型能够根据简短的指令生成连贯、有深度的小说文本,以满足多样化的创作需求。此外,该数据集也被用于探索如何通过上下文理解生成更为合理的小说续篇,这对于故事生成算法的优化和创意写作的自动化具有重要的研究意义和实际应用价值。与此同时,相关研究还关注于数据集在情感分析、角色性格刻画等方面的应用潜力,以期为读者提供更为丰富和个性化的阅读体验。
以上内容由遇见数据集搜集并总结生成


