MoRoVoc
收藏arXiv2025-09-21 更新2025-09-24 收录
下载链接:
https://huggingface.co/datasets/avramandrei/morovoc
下载链接
链接失效反馈官方服务:
资源简介:
MoRoVoc是目前为止最大的用于分析罗马尼亚语地区变体的数据集,包含93+小时的音频和88,192个音频样本,罗马尼亚语和摩尔多瓦方言之间的样本数量平衡。该数据集包括全面的年龄和性别元数据,来源于高质量议会辩论。MoRoVoc数据集的创建是为了解决低资源语言在语音技术中的方言识别挑战。该数据集可用于公共研究,旨在通过引入多目标对抗训练框架来提高语音模型在方言识别、性别和年龄分类任务上的性能。
MoRoVoc is the largest dataset to date for analyzing Romanian regional varieties. It contains over 93 hours of audio and 88,192 audio samples, with a balanced number of samples between Romanian and Moldovan dialects. The dataset includes comprehensive age and gender metadata, and is sourced from high-quality parliamentary debates. MoRoVoc was created to address the dialect recognition challenge in speech technology for low-resource languages. It is available for public research, and aims to improve the performance of speech models on dialect recognition, gender and age classification tasks by introducing a multi-objective adversarial training framework.
提供机构:
罗马尼亚布加勒斯特理工大学的科学与技术国家大学
创建时间:
2025-09-21
原始信息汇总
MoRoVoc数据集概述
基本信息
- 许可证: MIT
- 语言: 罗马尼亚语 (ro)
- 任务类别: 音频分类
- 标签: 方言、政治
- 规模类别: 10K<n<100K
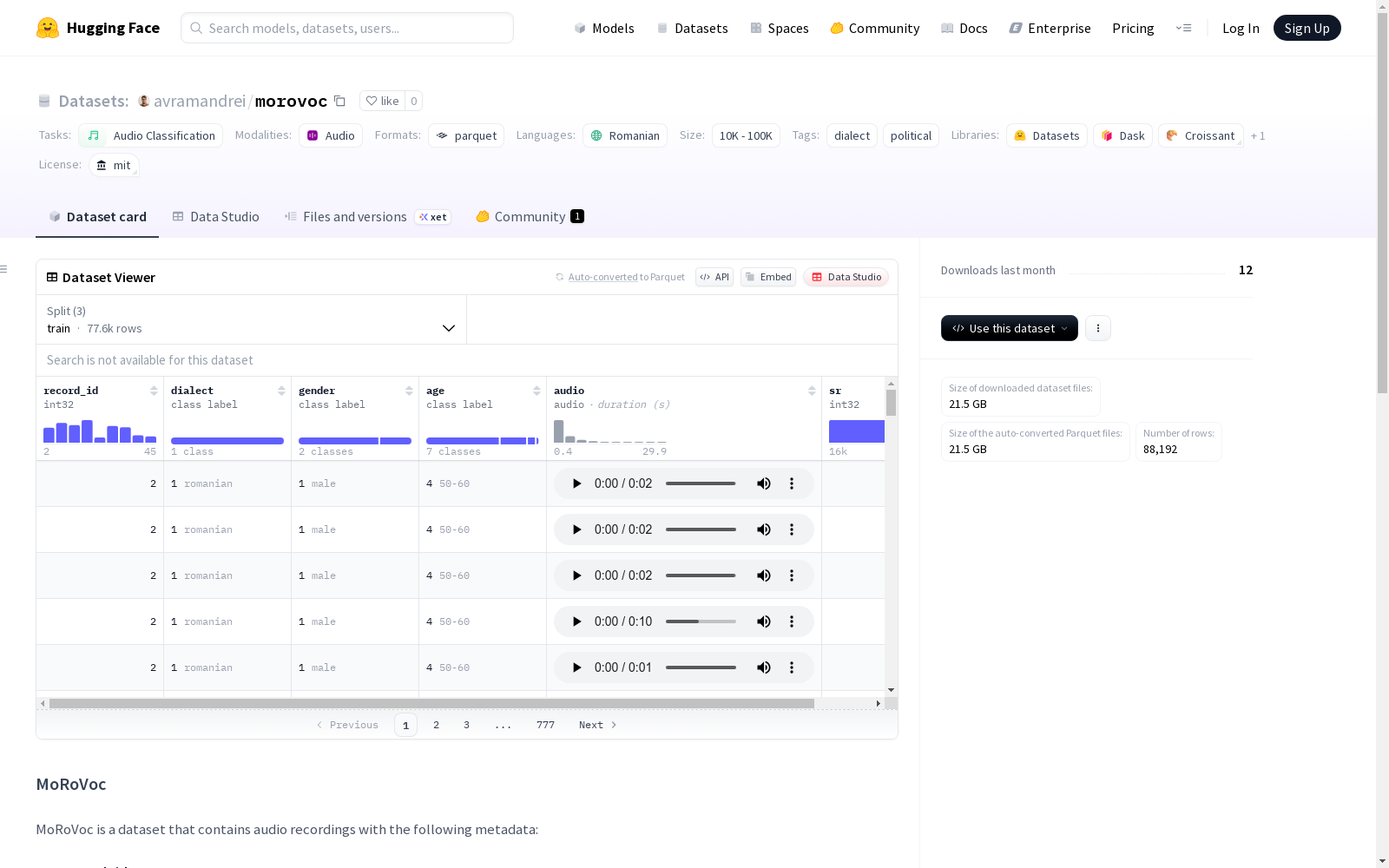
数据集结构
- 训练集: 77,638个样本
- 验证集: 5,348个样本
- 测试集: 5,348个样本
数据特征
- record_id: 每个记录的唯一标识符 (int32)
- dialect: 说话者的方言/语言变体
- 0: moldavian
- 1: romanian
- gender: 说话者的性别
- 0: female
- 1: male
- age: 说话者的年龄范围
- 0: 10-20
- 1: 20-30
- 2: 30-40
- 3: 40-50
- 4: 50-60
- 5: 50-70
- 6: 60-70
- 7: 70-80
- 8: 80-90
- audio: 音频文件 (WAV格式,采样率16,000Hz)
- sr: 音频采样率 (int32)
技术规格
- 下载大小: 21,519,950,558字节
- 数据集大小: 21,198,182,075.088字节
- 音频采样率: 16,000Hz
使用方式
python from datasets import load_dataset
dataset = load_dataset("avramandrei/morovoc")
访问数据分割
train_data = dataset[train] valid_data = dataset[validation] test_data = dataset[test]
访问样本
sample = train_data[0] audio_array = sample[audio][array] sampling_rate = sample[audio][sampling_rate]
引用信息
- 论文状态: 工作进展中
- 引用格式: Work in progress
搜集汇总
数据集介绍
构建方式
在罗马尼亚语方言识别研究领域,MoRoVoc数据集的构建采用了严谨的语料采集流程。该数据集源自罗马尼亚和摩尔多瓦议会公开辩论录音,通过人工分段筛选出纯净的单人语音片段,剔除重叠发言或低清晰度内容。所有样本均经由本地母语标注者进行方言标签验证,确保标注可靠性。最终形成的语料库包含88,192个音频样本,时长跨越0.4至30秒,采样率统一为22,050Hz,并采用严格的说话人分离划分策略,确保训练集、验证集与测试集之间不存在说话人重叠。
特点
作为目前最大的罗马尼亚语口语方言数据集,MoRoVoc呈现出多维度特征优势。其核心价值体现在93.48小时的高质量语音数据平衡覆盖标准罗马尼亚语与摩尔多瓦方言,同时集成详尽的说话人年龄与性别元数据。音频质量指标显示信噪比(SNR)达20.86dB,混响比(SRR)为23.24dB,表明背景噪声与混响控制良好。数据分布反映议会语料特性,男性说话人占比67.9%,年龄集中分布于40-60岁区间,标注者间一致性系数0.87与平均准确率91%共同保障了标注可靠性。
使用方法
该数据集支持多任务语音模型研究,特别适配于对抗训练框架的应用。使用者可基于预训练语音模型(如Wav2Vec2)加载音频数据,通过配置多目标分类头实现方言识别、性别分类与年龄预测的联合学习。具体操作中,可将任意任务设为主目标,其余属性作为对抗目标,利用梯度反转机制优化模型表征的判别性与不变性。动态元学习策略能自适应调整对抗系数,实验表明该方法可使Wav2Vec2-Base方言识别准确率提升5.20%,Wav2Vec2-Large性别分类达93.08%准确率。
背景与挑战
背景概述
MoRoVoc数据集于2025年由布加勒斯特理工大学与索邦大学等机构联合发布,作为罗马尼亚语口语方言识别的最大规模资源,填补了低资源语言在语音技术领域的空白。该数据集收录了93小时议会辩论音频,涵盖罗马尼亚与摩尔多瓦两大方言变体,并标注了说话人的年龄与性别属性,为研究方言地理变异提供了高质量数据基础。其构建依托公开立法会议录音,通过人工分段与本土标注者验证,确保了方言标签的可靠性,显著推动了罗马尼亚语语音模型在多任务学习中的发展。
当前挑战
在方言识别任务中,MoRoVoc需解决正式语域下方言特征弱化的挑战,如摩尔多瓦方言中古语特征与俄语影响的混合现象,导致模型对过渡性方言的误判率达12.3%。数据集构建过程中,议会录音的固有局限性带来显著挑战:说话人 demographic 分布失衡(男性占比67.9%,中老年群体主导),且年轻与高龄说话人样本稀缺,制约了模型对年龄分类的泛化能力。此外,二进制方言分类简化了罗马尼亚五大传统方言的复杂性,需未来扩展更多语域与方言变体以提升实用性。
常用场景
经典使用场景
在罗马尼亚语语音变异研究领域,MoRoVoc数据集最经典的应用场景是作为方言识别的基准测试平台。该数据集通过包含标准罗马尼亚语与摩尔多瓦方言的平衡样本,为语音模型提供了区分两种主要方言变体的训练基础。研究人员利用其高质量的议会录音数据,能够系统分析方言间的声学特征差异,例如元音质量、辅音发音方式以及韵律模式的细微差别。这种应用不仅推动了低资源语言的技术发展,更为跨方言语音识别系统的构建提供了重要数据支撑。
解决学术问题
MoRoVoc数据集有效解决了罗马尼亚语作为低资源语言在语音技术研究中面临的数据稀缺问题。其包含的9.3万条标注样本填补了该语言方言识别领域的空白,使得基于深度学习的声学模型训练成为可能。通过引入多目标对抗训练框架,该数据集助力模型在保持方言区分能力的同时消除性别、年龄等无关变量的干扰,显著提升了分类任务的鲁棒性。这项工作为资源受限语言的语音处理研究提供了可复现的范式,推动了计算语言学在多元语言环境下的方法论创新。
衍生相关工作
该数据集的发布催生了多项创新性研究,其中最具代表性的是基于元学习的多目标对抗训练框架的深入探索。研究者通过动态调整方言、性别、年龄等对抗目标的系数权重,实现了Wav2Vec2-Large模型在性别分类任务上93.08%的准确率突破。后续工作进一步验证了该框架在HuBERT和WavLM等不同语音架构上的普适性,推动形成了针对低资源语言的对抗训练方法论体系。这些衍生研究不仅丰富了语音表征学习理论,还为多语种方言识别任务提供了可迁移的技术方案。
以上内容由遇见数据集搜集并总结生成


