first-impressions-v2
收藏Hugging Face2025-03-25 更新2025-03-26 收录
下载链接:
https://huggingface.co/datasets/yeray142/first-impressions-v2
下载链接
链接失效反馈官方服务:
资源简介:
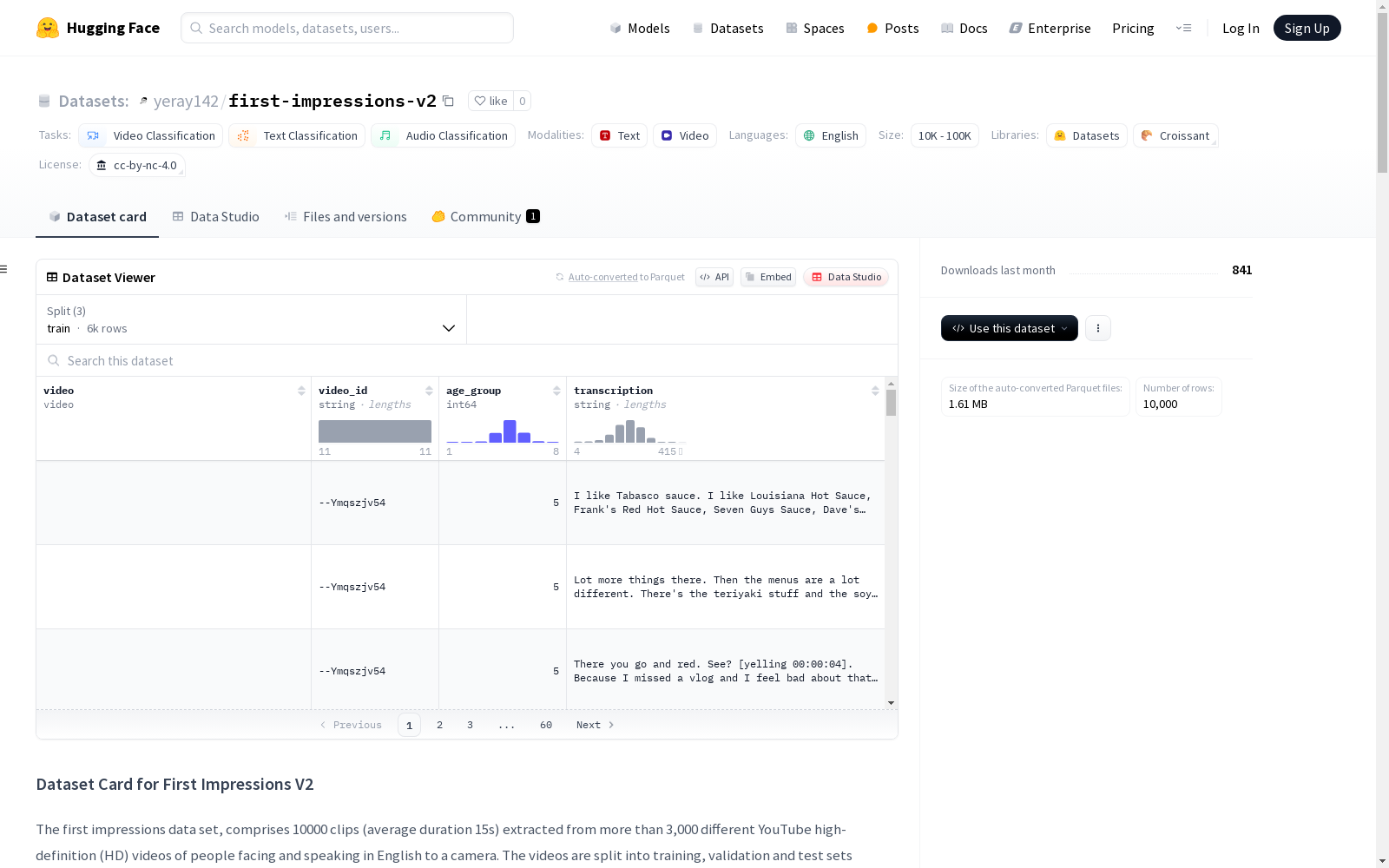
First Impressions V2数据集包含了从超过3000个不同的YouTube高清视频中提取的10000个视频片段(平均时长15秒),这些视频中的面对镜头说英语的人展示了不同的性别、年龄、国籍和种族。视频被分为训练集、验证集和测试集,比例为3:1:1。视频通过亚马逊Mechanical Turk进行标注,标注包含五大性格特质变量,即五大人格模型(大五人格),包括外向性、宜人性、责任心、神经质和开放性。每个视频片段都有这五个特质的地面真实标签,值在0到1之间。数据集还扩展了新的语言数据(转录)和新的工作面试变量(面试注释)。转录由专业转录服务Rev完成,平均每个视频43个单词。此外,还有关于性别和种族的标注。数据集还提供了原始成对注释和预测属性(软标签)。
First Impressions V2 Dataset contains 10,000 video clips (average duration: 15 seconds) extracted from over 3,000 distinct high-definition YouTube videos, where English-speaking individuals facing the camera exhibit diverse genders, ages, nationalities and ethnicities. The dataset is split into training, validation and test sets with a ratio of 3:1:1. All videos were annotated via Amazon Mechanical Turk, with annotations covering the Big Five Personality Traits model, namely extraversion, agreeableness, conscientiousness, neuroticism and openness to experience. Each video clip has ground-truth labels for these five traits, with values ranging from 0 to 1. The dataset also includes new linguistic data (transcriptions) and novel job interview-related variables (interview annotations). The transcriptions were completed by professional transcription service Rev, with an average of 43 words per video. Additionally, annotations for gender and race are provided. The dataset also offers original pairwise annotations and predicted attributes (soft labels).
创建时间:
2025-03-25
搜集汇总
数据集介绍
构建方式
在人格计算研究领域,First Impressions V2数据集通过科学严谨的方法构建而成。研究人员从3000余个YouTube高清视频中精心截取10000个平均时长15秒的片段,确保样本覆盖不同性别、年龄、国籍和种族的人群。采用亚马逊土耳其机器人(AMT)平台进行标注,通过标准化流程确保五大人格特质标签的可靠性,每个特质维度均以[0,1]区间的连续值表示。数据集按3:1:1比例划分为训练集、验证集和测试集,并新增专业转录文本和面试评估标注,形成多模态研究基础。
使用方法
该数据集支持视频分类、文本分类和音频分类等多模态任务。研究人员可通过解析pickle格式的标注字典获取结构化数据,其中转录文本以视频名称为键值存储,人格特质标注采用嵌套字典结构实现多维访问。典型应用包括:通过`annotation['neuroticism']['video_name']`获取特定视频的神经质评分,或利用`transcription['video_name']`提取对应文本特征。数据集特别适用于跨模态 personality computing 研究,可结合视觉、声学和语言特征进行多任务学习,但需注意遵循CC BY-NC 4.0许可协议的非商业使用限制。
背景与挑战
背景概述
First Impressions V2数据集由ChaLearn Looking at People、CVC和UAB等机构联合创建,旨在研究人类在视频中的第一印象与人格特质之间的关联。该数据集基于YouTube高清视频,收录了10,000个平均时长为15秒的片段,涵盖了不同性别、年龄、国籍和族裔的个体。数据集的核心研究问题围绕五大人格特质模型(Big Five)展开,包括外向性、宜人性、尽责性、神经质和开放性。该数据集通过亚马逊土耳其机器人(AMT)进行标注,确保了标签的可靠性,并在人格计算和多媒体分析领域产生了广泛影响。
当前挑战
First Impressions V2数据集在解决视频人格特质分析问题时面临多重挑战。首先,人格特质的标注具有高度主观性,不同标注者可能对同一视频产生分歧,影响模型的泛化能力。其次,数据集的构建过程中,视频的多样性和复杂性增加了标注难度,尤其是在处理多模态数据(如音频、文本和视觉信息)时。此外,数据集的扩展部分引入了新的变量(如面试邀请决策),进一步增加了标注的复杂性。最后,数据集在性别和族裔标注上的局限性可能引发公平性和偏见问题,对模型的公正性提出了更高要求。
常用场景
经典使用场景
在心理学与计算机视觉交叉领域,first-impressions-v2数据集为研究者提供了丰富的多模态数据,用于探索人类第一印象形成的复杂机制。该数据集通过YouTube视频片段捕捉人物面部表情、语音内容和肢体语言,结合大五人格模型的标注,成为研究非语言行为与人格特质关联性的重要基准。其经典应用场景包括构建端到端的深度学习模型,从视听特征中预测人物的外向性、亲和性等维度,推动自动人格识别技术的发展。
解决学术问题
该数据集有效解决了传统人格研究中主观评估效率低下、样本量有限的问题。通过众包标注和标准化处理,研究者能够量化分析非语言线索与人格特质的相关性,验证心理学理论中的第一印象形成假说。特别在跨文化人格感知研究中,其包含的多民族样本为探索认知偏差提供了数据基础,相关成果已发表于IEEE Transactions on Affective Computing等顶级期刊,推动了计算行为科学的方法论革新。
实际应用
在人力资源智能化领域,该数据集衍生的技术可辅助初筛面试候选人,通过分析视频简历中的非语言特征评估岗位适配度。教育机构利用其构建的模型能识别学生的课堂参与倾向,优化个性化教学方案。值得注意的是,研究者严格遵循伦理准则,仅将系统作为决策辅助工具,避免自动化偏见影响关键人事决定。
数据集最近研究
最新研究方向
近年来,first-impressions-v2数据集在计算人格感知和多媒体行为分析领域引起了广泛关注。该数据集通过结合视频、音频和文本多模态数据,为研究者提供了丰富的人格特质分析素材。前沿研究主要聚焦于利用深度学习模型从非语言行为中预测人格特质,探索跨模态融合技术在人格计算中的应用潜力。随着可解释人工智能的兴起,如何解释模型对人格特质的预测过程成为热点方向。数据集新增的面试标注变量进一步拓展了其在人力资源智能化评估中的应用场景。近期研究还揭示了数据集中存在的认知偏差问题,促使学界更加关注算法公平性和数据代表性。这些进展不仅推动了人格计算理论的发展,也为多模态情感计算和人机交互领域提供了重要参考。
以上内容由遇见数据集搜集并总结生成


