corrstruct-testing
收藏Hugging Face2025-04-28 更新2025-04-29 收录
下载链接:
https://huggingface.co/datasets/idegen/corrstruct-testing
下载链接
链接失效反馈官方服务:
资源简介:
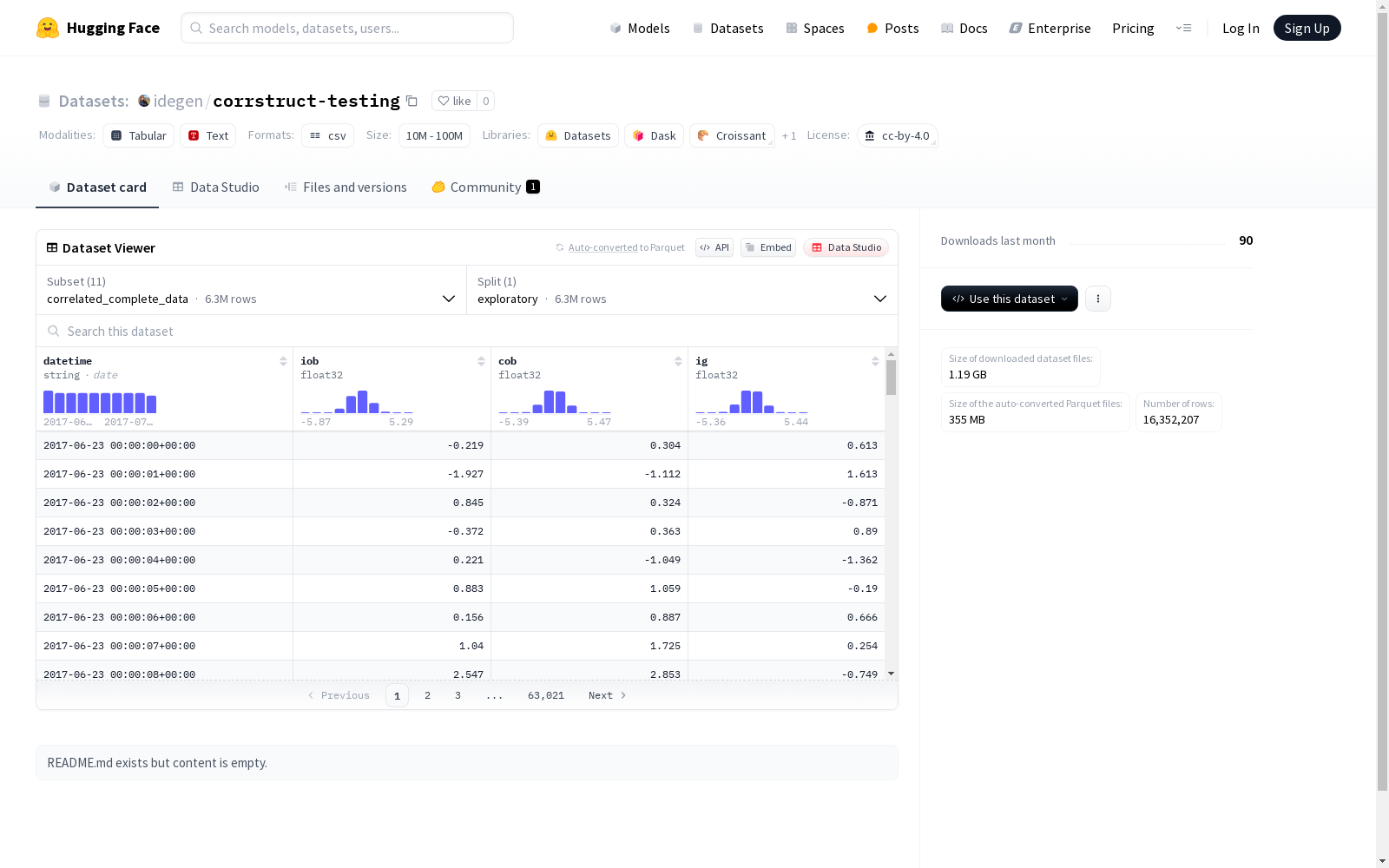
数据集包含不同配置的数据和标签文件,支持探索性数据分析。数据特征包括时间戳、三种浮点数类型的特征。标签特征包括索引、长度、聚类ID和与模型的关联度等。数据集分为完整数据、相关数据、部分数据和稀疏数据等类型,每种类型都有对应的标签数据。数据集的许可为cc-by-4.0。
创建时间:
2025-04-24
原始信息汇总
数据集概述
基本信息
- 许可证: CC-BY-4.0
- 数据集地址: https://huggingface.co/datasets/idegen/corrstruct-testing
数据特征
数据文件特征
- datetime: 字符串类型,时间戳
- iob: float32类型
- cob: float32类型
- ig: float32类型
标签文件特征
- id: int32类型
- start idx: int32类型
- end idx: int32类型
- length: int32类型
- cluster_id: int32类型
- correlation to model: 字符串类型
- correlation achieved: 字符串类型
- correlation achieved with tolerance: 字符串类型
- MAE: float32类型
- relaxed MAE: float32类型
配置信息
配置列表
-
raw_complete_data
- 数据文件路径: exploratory/raw/*-data.csv
- 特征: 数据文件特征
-
raw_complete_labels
- 数据文件路径: exploratory/raw/*-labels.csv
- 特征: 标签文件特征
-
correlated_complete_data
- 数据文件路径: exploratory/normal/*-data.csv
- 特征: 数据文件特征
-
correlated_complete_labels
- 数据文件路径: exploratory/normal/*-labels.csv
- 特征: 标签文件特征
-
correlated_partial_data
- 数据文件路径: exploratory/irregular_p30/normal/*-data.csv
- 特征: 数据文件特征
-
correlated_partial_labels
- 数据文件路径: exploratory/irregular_p30/normal/*-labels.csv
- 特征: 标签文件特征
-
nonnormal_partial_data
- 数据文件路径: exploratory/irregular_p30/non_normal/*-data.csv
- 特征: 数据文件特征
-
nonnormal_partial_labels
- 数据文件路径: exploratory/irregular_p30/non_normal/*-labels.csv
- 特征: 标签文件特征
-
correlated_sparse_data
- 数据文件路径: exploratory/irregular_p90/normal/*-data.csv
- 特征: 数据文件特征
-
correlated_sparse_labels
- 数据文件路径: exploratory/irregular_p90/normal/*-labels.csv
- 特征: 标签文件特征
-
correlated_sparse_badclusterings_labels
- 数据文件路径: exploratory/irregular_p90/normal/bad_partitions/*-labels.csv
- 特征: 标签文件特征
搜集汇总
数据集介绍
构建方式
在时间序列分析领域,corrstruct-testing数据集通过多维度特征采集与标注构建而成。其数据特征包含时间戳、开盘价、收盘价等金融指标,以CSV格式存储于不同配置路径下,涵盖原始数据、标准化处理数据及稀疏数据等多种形态。标签特征则采用事件切片标注方式,记录每个事件段的起止位置、聚类归属及相关性指标,通过文件分片策略实现数据模块化管理。
特点
该数据集呈现出鲜明的层次化特征架构,数据特征与标签特征采用YAML锚点实现结构复用,提升数据一致性。时间序列数据包含常规金融指标与非常规扰动数据,标签系统则创新性地引入容忍度评估指标和松弛平均绝对误差,为模型鲁棒性测试提供多维评估基准。不同配置方案覆盖完整数据、部分缺失及异常聚类场景,为算法验证构建了丰富的测试环境。
使用方法
研究者可通过加载不同配置方案实现针对性实验设计,raw_complete系列适用于基础模型训练,correlated_complete配置提供标准化测试场景,而irregular_p30/p90系列则专攻数据缺失情况下的算法稳定性验证。数据与标签文件的配对加载机制确保实验可重复性,MAE与relaxed_MAE双指标系统支持模型误差的严格与宽松双重评估标准。
背景与挑战
背景概述
corrstruct-testing数据集聚焦于时间序列数据的相关性结构分析,由专业研究团队构建,旨在解决复杂系统中多维时间序列的关联模式识别问题。该数据集通过精确记录时间戳(datetime)及多种数值型特征(iob、cob、ig等),结合聚类标识(cluster_id)和相关性度量指标(MAE、relaxed MAE等),为研究非线性时序依赖关系提供了标准化评估框架。其多配置设计(如correlated_complete、nonnormal_partial等)支持对数据完整性、分布特性及聚类质量的系统性探究,显著推动了时序数据分析领域的方法验证与算法优化。
当前挑战
该数据集面临的挑战主要体现在两方面:其一,在领域问题层面,高维时间序列的动态相关性建模存在计算复杂度高、噪声敏感性强等难点,且稀疏数据(如irregular_p90配置)下的聚类有效性评估亟待更鲁棒的度量标准;其二,在构建过程中,需平衡数据生成的真实性与可控性,例如通过人工引入非常规分布(non_normal)和分区错误(bad_partitions)来模拟现实场景的复杂性,这对特征工程的泛化性提出了更高要求。
常用场景
经典使用场景
在金融时间序列分析领域,corrstruct-testing数据集因其包含多维度的市场指标(如开盘价、收盘价、成交量等)和精细的标签特征(如聚类ID、相关性指标等),常被用于检验新型相关性结构模型的性能。该数据集特别适合模拟高频交易环境下市场变量的动态关联性研究,为量化分析师提供了验证模型鲁棒性的基准平台。
实际应用
实际应用中,该数据集被广泛用于构建智能交易系统的风控模块。对冲基金利用其多维相关性标签训练算法,以预测资产价格的联动效应;监管机构则借助数据中的异常聚类模式,监测跨市场风险传导。数据中特意设计的稀疏和非常规子集,更可模拟极端市场条件下的模型表现。
衍生相关工作
基于该数据集衍生的经典工作包括《基于层次聚类的跨市场风险传染检测》等研究,这些成果创新性地将拓扑数据分析引入金融领域。后续研究进一步拓展了数据集的应用边界,开发出能够处理非正态分布和极端稀疏场景的新型相关性建模框架,推动了计算金融学的方法论革新。
以上内容由遇见数据集搜集并总结生成


