有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
question: 字符串answer: 字符串id: 64位整数relevant_passage_ids: 64位整数序列train:
test:
passage: 字符串id: 64位整数test:
train: question-answer-passages/train-*test: question-answer-passages/test-*test: text-corpus/test-*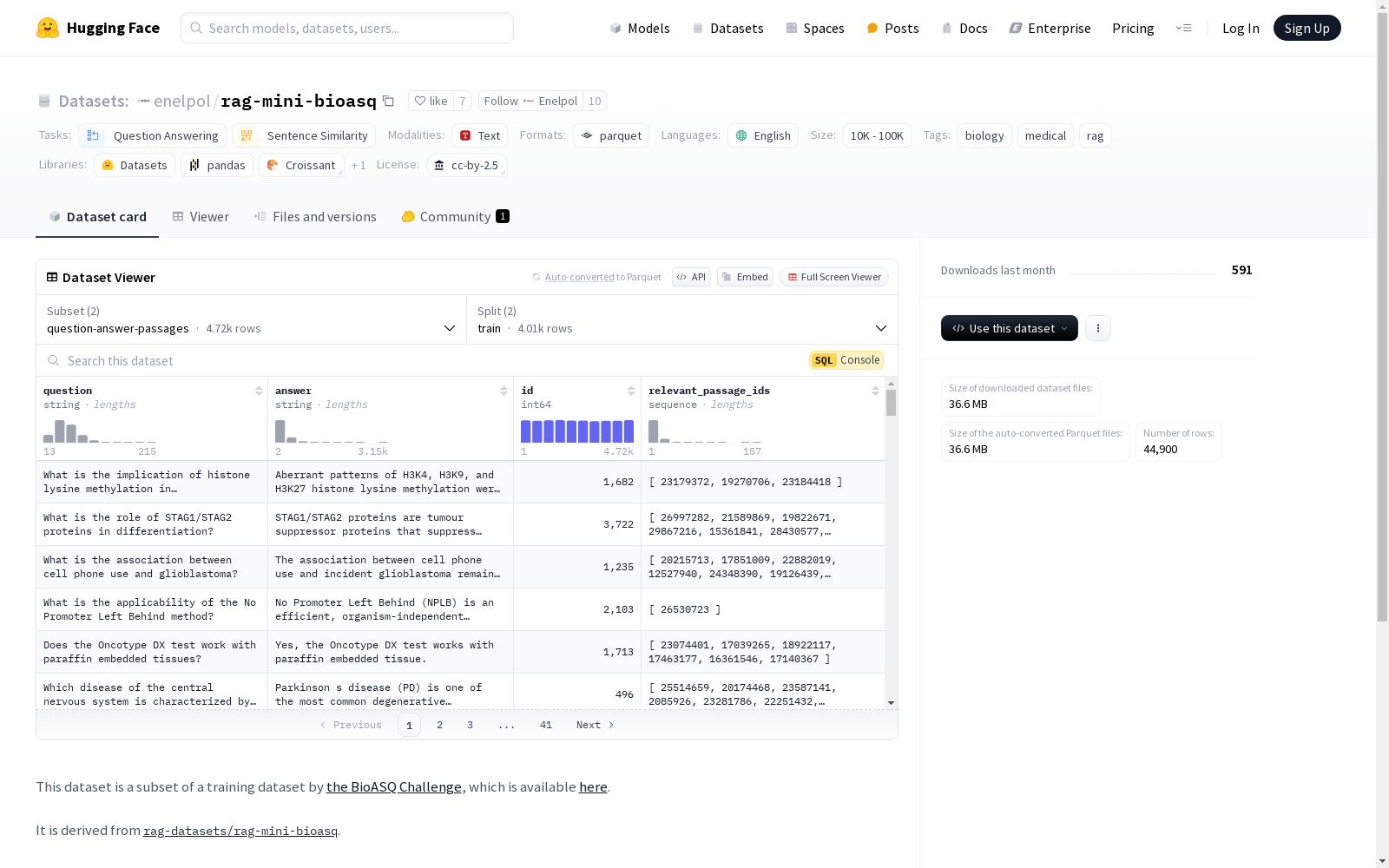
TM-Senti
TM-Senti是由伦敦玛丽女王大学开发的一个大规模、远距离监督的Twitter情感数据集,包含超过1.84亿条推文,覆盖了超过七年的时间跨度。该数据集基于互联网档案馆的公开推文存档,可以完全重新构建,包括推文元数据且无缺失推文。数据集内容丰富,涵盖多种语言,主要用于情感分析和文本分类等任务。创建过程中,研究团队精心筛选了表情符号和表情,确保数据集的质量和多样性。该数据集的应用领域广泛,旨在解决社交媒体情感表达的长期变化问题,特别是在表情符号和表情使用上的趋势分析。
arXiv 收录
CosyVoice 2
CosyVoice 2是由阿里巴巴集团开发的多语言语音合成数据集,旨在通过大规模多语言数据集训练,实现高质量的流式语音合成。数据集通过有限标量量化技术改进语音令牌的利用率,并结合预训练的大型语言模型作为骨干,支持流式和非流式合成。数据集的创建过程包括文本令牌化、监督语义语音令牌化、统一文本-语音语言模型和块感知流匹配模型等步骤。该数据集主要应用于语音合成领域,旨在解决高延迟和低自然度的问题,提供接近人类水平的语音合成质量。
arXiv 收录
flames-and-smoke-datasets
该仓库总结了多个公开的火焰和烟雾数据集,包括DFS、D-Fire dataset、FASDD、FLAME、BoWFire、VisiFire、fire-smoke-detect-yolov4、Forest Fire等数据集。每个数据集都有详细的描述,包括数据来源、图像数量、标注信息等。
github 收录
Figshare
Figshare是一个在线数据共享平台,允许研究人员上传和共享各种类型的研究成果,包括数据集、论文、图像、视频等。它旨在促进科学研究的开放性和可重复性。
figshare.com 收录
cais/mmlu
--- annotations_creators: - no-annotation language_creators: - expert-generated language: - en license: - mit multilinguality: - monolingual size_categories: - 10K<n<100K source_datasets: - original task_categories: - question-answering task_ids: - multiple-choice-qa paperswithcode_id: mmlu pretty_name: Measuring Massive Multitask Language Understanding language_bcp47: - en-US dataset_info: - config_name: abstract_algebra features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 49618.6654322746 num_examples: 100 - name: validation num_bytes: 5485.515349444808 num_examples: 11 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 17143 dataset_size: 57303.3562203159 - config_name: all features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 6967453 num_examples: 14042 - name: validation num_bytes: 763484 num_examples: 1531 - name: dev num_bytes: 125353 num_examples: 285 - name: auxiliary_train num_bytes: 161000625 num_examples: 99842 download_size: 51503402 dataset_size: 168856915 - config_name: anatomy features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 66985.19833357072 num_examples: 135 - name: validation num_bytes: 6981.5649902024825 num_examples: 14 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 28864 dataset_size: 76165.9387623697 - config_name: astronomy features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 75420.3714570574 num_examples: 152 - name: validation num_bytes: 7978.931417374265 num_examples: 16 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 39316 dataset_size: 85598.47831302814 - config_name: auxiliary_train features: - name: train struct: - name: answer dtype: int64 - name: choices sequence: string - name: question dtype: string - name: subject dtype: string splits: - name: train num_bytes: 161000625 num_examples: 99842 download_size: 47518592 dataset_size: 161000625 - config_name: business_ethics features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 49618.6654322746 num_examples: 100 - name: validation num_bytes: 5485.515349444808 num_examples: 11 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 31619 dataset_size: 57303.3562203159 - config_name: clinical_knowledge features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 131489.4633955277 num_examples: 265 - name: validation num_bytes: 14461.813193990856 num_examples: 29 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 51655 dataset_size: 148150.45202811505 - config_name: college_biology features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 71450.87822247542 num_examples: 144 - name: validation num_bytes: 7978.931417374265 num_examples: 16 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 43017 dataset_size: 81628.98507844617 - config_name: college_chemistry features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 49618.6654322746 num_examples: 100 - name: validation num_bytes: 3989.4657086871325 num_examples: 8 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 26781 dataset_size: 55807.30657955822 - config_name: college_computer_science features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 49618.6654322746 num_examples: 100 - name: validation num_bytes: 5485.515349444808 num_examples: 11 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 41132 dataset_size: 57303.3562203159 - config_name: college_mathematics features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 49618.6654322746 num_examples: 100 - name: validation num_bytes: 5485.515349444808 num_examples: 11 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 26779 dataset_size: 57303.3562203159 - config_name: college_medicine features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 85840.29119783506 num_examples: 173 - name: validation num_bytes: 10971.030698889615 num_examples: 22 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 56303 dataset_size: 99010.49733532117 - config_name: college_physics features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 50611.0387409201 num_examples: 102 - name: validation num_bytes: 5485.515349444808 num_examples: 11 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 29539 dataset_size: 58295.7295289614 - config_name: computer_security features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 49618.6654322746 num_examples: 100 - name: validation num_bytes: 5485.515349444808 num_examples: 11 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 30150 dataset_size: 57303.3562203159 - config_name: conceptual_physics features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 116603.86376584532 num_examples: 235 - name: validation num_bytes: 12965.76355323318 num_examples: 26 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 34968 dataset_size: 131768.802757675 - config_name: econometrics features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 56565.27859279305 num_examples: 114 - name: validation num_bytes: 5984.198563030699 num_examples: 12 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 36040 dataset_size: 64748.652594420244 - config_name: electrical_engineering features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 71947.06487679818 num_examples: 145 - name: validation num_bytes: 7978.931417374265 num_examples: 16 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 26746 dataset_size: 82125.17173276893 - config_name: elementary_mathematics features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 187558.555333998 num_examples: 378 - name: validation num_bytes: 20446.011757021555 num_examples: 41 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 54987 dataset_size: 210203.74252961605 - config_name: formal_logic features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 62519.518444666 num_examples: 126 - name: validation num_bytes: 6981.5649902024825 num_examples: 14 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 32884 dataset_size: 71700.25887346498 - config_name: global_facts features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 49618.6654322746 num_examples: 100 - name: validation num_bytes: 4986.8321358589155 num_examples: 10 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 19258 dataset_size: 56804.67300673001 - config_name: high_school_biology features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 153817.86284005127 num_examples: 310 - name: validation num_bytes: 15957.86283474853 num_examples: 32 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 78216 dataset_size: 171974.90111339628 - config_name: high_school_chemistry features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 100725.89082751745 num_examples: 203 - name: validation num_bytes: 10971.030698889615 num_examples: 22 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 45799 dataset_size: 113896.09696500355 - config_name: high_school_computer_science features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 49618.6654322746 num_examples: 100 - name: validation num_bytes: 4488.148922273024 num_examples: 9 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 39072 dataset_size: 56305.989793144116 - config_name: high_school_european_history features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 81870.79796325309 num_examples: 165 - name: validation num_bytes: 8976.297844546049 num_examples: 18 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 196270 dataset_size: 93046.27124639563 - config_name: high_school_geography features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 98244.95755590372 num_examples: 198 - name: validation num_bytes: 10971.030698889615 num_examples: 22 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 38255 dataset_size: 111415.16369338983 - config_name: high_school_government_and_politics features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 95764.02428428999 num_examples: 193 - name: validation num_bytes: 10472.347485303722 num_examples: 21 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 52963 dataset_size: 108435.5472081902 - config_name: high_school_macroeconomics features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 193512.79518587096 num_examples: 390 - name: validation num_bytes: 21443.378184193338 num_examples: 43 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 68758 dataset_size: 217155.34880866078 - config_name: high_school_mathematics features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 133970.39666714144 num_examples: 270 - name: validation num_bytes: 14461.813193990856 num_examples: 29 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 45210 dataset_size: 150631.38529972878 - config_name: high_school_microeconomics features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 118092.42372881356 num_examples: 238 - name: validation num_bytes: 12965.76355323318 num_examples: 26 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 49885 dataset_size: 133257.36272064323 - config_name: high_school_physics features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 74924.18480273466 num_examples: 151 - name: validation num_bytes: 8477.614630960157 num_examples: 17 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 45483 dataset_size: 85600.9748722913 - config_name: high_school_psychology features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 270421.7266058966 num_examples: 545 - name: validation num_bytes: 29920.992815153495 num_examples: 60 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 113158 dataset_size: 302541.8948596466 - config_name: high_school_statistics features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 107176.31733371314 num_examples: 216 - name: validation num_bytes: 11469.713912475507 num_examples: 23 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 74924 dataset_size: 120845.20668478514 - config_name: high_school_us_history features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 101222.0774818402 num_examples: 204 - name: validation num_bytes: 10971.030698889615 num_examples: 22 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 200043 dataset_size: 114392.2836193263 - config_name: high_school_world_history features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 117596.23707449081 num_examples: 237 - name: validation num_bytes: 12965.76355323318 num_examples: 26 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 250302 dataset_size: 132761.17606632048 - config_name: human_aging features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 110649.62391397236 num_examples: 223 - name: validation num_bytes: 11469.713912475507 num_examples: 23 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 41196 dataset_size: 124318.51326504436 - config_name: human_sexuality features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 65000.451716279735 num_examples: 131 - name: validation num_bytes: 5984.198563030699 num_examples: 12 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 32533 dataset_size: 73183.82571790692 - config_name: international_law features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 60038.58517305227 num_examples: 121 - name: validation num_bytes: 6482.88177661659 num_examples: 13 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 41592 dataset_size: 68720.64238826535 - config_name: jurisprudence features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 53588.15866685657 num_examples: 108 - name: validation num_bytes: 5485.515349444808 num_examples: 11 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 33578 dataset_size: 61272.84945489787 - config_name: logical_fallacies features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 80878.4246546076 num_examples: 163 - name: validation num_bytes: 8976.297844546049 num_examples: 18 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 33669 dataset_size: 92053.89793775014 - config_name: machine_learning features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 55572.90528414756 num_examples: 112 - name: validation num_bytes: 5485.515349444808 num_examples: 11 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 31121 dataset_size: 63257.596072188855 - config_name: management features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 51107.225395242844 num_examples: 103 - name: validation num_bytes: 5485.515349444808 num_examples: 11 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 22828 dataset_size: 58791.91618328414 - config_name: marketing features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 116107.67711152257 num_examples: 234 - name: validation num_bytes: 12467.08033964729 num_examples: 25 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 49747 dataset_size: 130773.93288976635 - config_name: medical_genetics features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 49618.6654322746 num_examples: 100 - name: validation num_bytes: 5485.515349444808 num_examples: 11 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 25775 dataset_size: 57303.3562203159 - config_name: miscellaneous features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 388514.15033471014 num_examples: 783 - name: validation num_bytes: 42886.756368386676 num_examples: 86 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 115097 dataset_size: 433600.08214169333 - config_name: moral_disputes features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 171680.58239567012 num_examples: 346 - name: validation num_bytes: 18949.96211626388 num_examples: 38 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 76043 dataset_size: 192829.71995053047 - config_name: moral_scenarios features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 444087.05561885773 num_examples: 895 - name: validation num_bytes: 49868.32135858916 num_examples: 100 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 109869 dataset_size: 496154.5524160434 - config_name: nutrition features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 151833.1162227603 num_examples: 306 - name: validation num_bytes: 16456.54604833442 num_examples: 33 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 69050 dataset_size: 170488.8377096912 - config_name: philosophy features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 154314.04949437402 num_examples: 311 - name: validation num_bytes: 16955.229261920314 num_examples: 34 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 61912 dataset_size: 173468.45419489083 - config_name: prehistory features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 160764.47600056973 num_examples: 324 - name: validation num_bytes: 17453.912475506204 num_examples: 35 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 68826 dataset_size: 180417.5639146724 - config_name: professional_accounting features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 139924.6365190144 num_examples: 282 - name: validation num_bytes: 15459.179621162639 num_examples: 31 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 87297 dataset_size: 157582.99157877354 - config_name: professional_law features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 761150.3277310925 num_examples: 1534 - name: validation num_bytes: 84776.14630960157 num_examples: 170 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 1167828 dataset_size: 848125.6494792906 - config_name: professional_medicine features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 134962.7699757869 num_examples: 272 - name: validation num_bytes: 15459.179621162639 num_examples: 31 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 153242 dataset_size: 152621.12503554605 - config_name: professional_psychology features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 303666.2324455206 num_examples: 612 - name: validation num_bytes: 34409.14173742652 num_examples: 69 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 159357 dataset_size: 340274.5496215436 - config_name: public_relations features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 54580.53197550207 num_examples: 110 - name: validation num_bytes: 5984.198563030699 num_examples: 12 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 31500 dataset_size: 62763.90597712925 - config_name: security_studies features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 121565.73030907278 num_examples: 245 - name: validation num_bytes: 13464.446766819072 num_examples: 27 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 140258 dataset_size: 137229.35251448833 - config_name: sociology features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 99733.51751887196 num_examples: 201 - name: validation num_bytes: 10971.030698889615 num_examples: 22 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 56480 dataset_size: 112903.72365635807 - config_name: us_foreign_policy features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 49618.6654322746 num_examples: 100 - name: validation num_bytes: 5485.515349444808 num_examples: 11 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 29027 dataset_size: 57303.3562203159 - config_name: virology features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 82366.98461757584 num_examples: 166 - name: validation num_bytes: 8976.297844546049 num_examples: 18 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 38229 dataset_size: 93542.45790071838 - config_name: world_religions features: - name: question dtype: string - name: subject dtype: string - name: choices sequence: string - name: answer dtype: class_label: names: '0': A '1': B '2': C '3': D splits: - name: test num_bytes: 84847.91788918957 num_examples: 171 - name: validation num_bytes: 9474.98105813194 num_examples: 19 - name: dev num_bytes: 2199.1754385964914 num_examples: 5 download_size: 27165 dataset_size: 96522.07438591801 configs: - config_name: abstract_algebra data_files: - split: test path: abstract_algebra/test-* - split: validation path: abstract_algebra/validation-* - split: dev path: abstract_algebra/dev-* - config_name: all data_files: - split: test path: all/test-* - split: validation path: all/validation-* - split: dev path: all/dev-* - split: auxiliary_train path: all/auxiliary_train-* - config_name: anatomy data_files: - split: test path: anatomy/test-* - split: validation path: anatomy/validation-* - split: dev path: anatomy/dev-* - config_name: astronomy data_files: - split: test path: astronomy/test-* - split: validation path: astronomy/validation-* - split: dev path: astronomy/dev-* - config_name: auxiliary_train data_files: - split: train path: auxiliary_train/train-* - config_name: business_ethics data_files: - split: test path: business_ethics/test-* - split: validation path: business_ethics/validation-* - split: dev path: business_ethics/dev-* - config_name: clinical_knowledge data_files: - split: test path: clinical_knowledge/test-* - split: validation path: clinical_knowledge/validation-* - split: dev path: clinical_knowledge/dev-* - config_name: college_biology data_files: - split: test path: college_biology/test-* - split: validation path: college_biology/validation-* - split: dev path: college_biology/dev-* - config_name: college_chemistry data_files: - split: test path: college_chemistry/test-* - split: validation path: college_chemistry/validation-* - split: dev path: college_chemistry/dev-* - config_name: college_computer_science data_files: - split: test path: college_computer_science/test-* - split: validation path: college_computer_science/validation-* - split: dev path: college_computer_science/dev-* - config_name: college_mathematics data_files: - split: test path: college_mathematics/test-* - split: validation path: college_mathematics/validation-* - split: dev path: college_mathematics/dev-* - config_name: college_medicine data_files: - split: test path: college_medicine/test-* - split: validation path: college_medicine/validation-* - split: dev path: college_medicine/dev-* - config_name: college_physics data_files: - split: test path: college_physics/test-* - split: validation path: college_physics/validation-* - split: dev path: college_physics/dev-* - config_name: computer_security data_files: - split: test path: computer_security/test-* - split: validation path: computer_security/validation-* - split: dev path: computer_security/dev-* - config_name: conceptual_physics data_files: - split: test path: conceptual_physics/test-* - split: validation path: conceptual_physics/validation-* - split: dev path: conceptual_physics/dev-* - config_name: econometrics data_files: - split: test path: econometrics/test-* - split: validation path: econometrics/validation-* - split: dev path: econometrics/dev-* - config_name: electrical_engineering data_files: - split: test path: electrical_engineering/test-* - split: validation path: electrical_engineering/validation-* - split: dev path: electrical_engineering/dev-* - config_name: elementary_mathematics data_files: - split: test path: elementary_mathematics/test-* - split: validation path: elementary_mathematics/validation-* - split: dev path: elementary_mathematics/dev-* - config_name: formal_logic data_files: - split: test path: formal_logic/test-* - split: validation path: formal_logic/validation-* - split: dev path: formal_logic/dev-* - config_name: global_facts data_files: - split: test path: global_facts/test-* - split: validation path: global_facts/validation-* - split: dev path: global_facts/dev-* - config_name: high_school_biology data_files: - split: test path: high_school_biology/test-* - split: validation path: high_school_biology/validation-* - split: dev path: high_school_biology/dev-* - config_name: high_school_chemistry data_files: - split: test path: high_school_chemistry/test-* - split: validation path: high_school_chemistry/validation-* - split: dev path: high_school_chemistry/dev-* - config_name: high_school_computer_science data_files: - split: test path: high_school_computer_science/test-* - split: validation path: high_school_computer_science/validation-* - split: dev path: high_school_computer_science/dev-* - config_name: high_school_european_history data_files: - split: test path: high_school_european_history/test-* - split: validation path: high_school_european_history/validation-* - split: dev path: high_school_european_history/dev-* - config_name: high_school_geography data_files: - split: test path: high_school_geography/test-* - split: validation path: high_school_geography/validation-* - split: dev path: high_school_geography/dev-* - config_name: high_school_government_and_politics data_files: - split: test path: high_school_government_and_politics/test-* - split: validation path: high_school_government_and_politics/validation-* - split: dev path: high_school_government_and_politics/dev-* - config_name: high_school_macroeconomics data_files: - split: test path: high_school_macroeconomics/test-* - split: validation path: high_school_macroeconomics/validation-* - split: dev path: high_school_macroeconomics/dev-* - config_name: high_school_mathematics data_files: - split: test path: high_school_mathematics/test-* - split: validation path: high_school_mathematics/validation-* - split: dev path: high_school_mathematics/dev-* - config_name: high_school_microeconomics data_files: - split: test path: high_school_microeconomics/test-* - split: validation path: high_school_microeconomics/validation-* - split: dev path: high_school_microeconomics/dev-* - config_name: high_school_physics data_files: - split: test path: high_school_physics/test-* - split: validation path: high_school_physics/validation-* - split: dev path: high_school_physics/dev-* - config_name: high_school_psychology data_files: - split: test path: high_school_psychology/test-* - split: validation path: high_school_psychology/validation-* - split: dev path: high_school_psychology/dev-* - config_name: high_school_statistics data_files: - split: test path: high_school_statistics/test-* - split: validation path: high_school_statistics/validation-* - split: dev path: high_school_statistics/dev-* - config_name: high_school_us_history data_files: - split: test path: high_school_us_history/test-* - split: validation path: high_school_us_history/validation-* - split: dev path: high_school_us_history/dev-* - config_name: high_school_world_history data_files: - split: test path: high_school_world_history/test-* - split: validation path: high_school_world_history/validation-* - split: dev path: high_school_world_history/dev-* - config_name: human_aging data_files: - split: test path: human_aging/test-* - split: validation path: human_aging/validation-* - split: dev path: human_aging/dev-* - config_name: human_sexuality data_files: - split: test path: human_sexuality/test-* - split: validation path: human_sexuality/validation-* - split: dev path: human_sexuality/dev-* - config_name: international_law data_files: - split: test path: international_law/test-* - split: validation path: international_law/validation-* - split: dev path: international_law/dev-* - config_name: jurisprudence data_files: - split: test path: jurisprudence/test-* - split: validation path: jurisprudence/validation-* - split: dev path: jurisprudence/dev-* - config_name: logical_fallacies data_files: - split: test path: logical_fallacies/test-* - split: validation path: logical_fallacies/validation-* - split: dev path: logical_fallacies/dev-* - config_name: machine_learning data_files: - split: test path: machine_learning/test-* - split: validation path: machine_learning/validation-* - split: dev path: machine_learning/dev-* - config_name: management data_files: - split: test path: management/test-* - split: validation path: management/validation-* - split: dev path: management/dev-* - config_name: marketing data_files: - split: test path: marketing/test-* - split: validation path: marketing/validation-* - split: dev path: marketing/dev-* - config_name: medical_genetics data_files: - split: test path: medical_genetics/test-* - split: validation path: medical_genetics/validation-* - split: dev path: medical_genetics/dev-* - config_name: miscellaneous data_files: - split: test path: miscellaneous/test-* - split: validation path: miscellaneous/validation-* - split: dev path: miscellaneous/dev-* - config_name: moral_disputes data_files: - split: test path: moral_disputes/test-* - split: validation path: moral_disputes/validation-* - split: dev path: moral_disputes/dev-* - config_name: moral_scenarios data_files: - split: test path: moral_scenarios/test-* - split: validation path: moral_scenarios/validation-* - split: dev path: moral_scenarios/dev-* - config_name: nutrition data_files: - split: test path: nutrition/test-* - split: validation path: nutrition/validation-* - split: dev path: nutrition/dev-* - config_name: philosophy data_files: - split: test path: philosophy/test-* - split: validation path: philosophy/validation-* - split: dev path: philosophy/dev-* - config_name: prehistory data_files: - split: test path: prehistory/test-* - split: validation path: prehistory/validation-* - split: dev path: prehistory/dev-* - config_name: professional_accounting data_files: - split: test path: professional_accounting/test-* - split: validation path: professional_accounting/validation-* - split: dev path: professional_accounting/dev-* - config_name: professional_law data_files: - split: test path: professional_law/test-* - split: validation path: professional_law/validation-* - split: dev path: professional_law/dev-* - config_name: professional_medicine data_files: - split: test path: professional_medicine/test-* - split: validation path: professional_medicine/validation-* - split: dev path: professional_medicine/dev-* - config_name: professional_psychology data_files: - split: test path: professional_psychology/test-* - split: validation path: professional_psychology/validation-* - split: dev path: professional_psychology/dev-* - config_name: public_relations data_files: - split: test path: public_relations/test-* - split: validation path: public_relations/validation-* - split: dev path: public_relations/dev-* - config_name: security_studies data_files: - split: test path: security_studies/test-* - split: validation path: security_studies/validation-* - split: dev path: security_studies/dev-* - config_name: sociology data_files: - split: test path: sociology/test-* - split: validation path: sociology/validation-* - split: dev path: sociology/dev-* - config_name: us_foreign_policy data_files: - split: test path: us_foreign_policy/test-* - split: validation path: us_foreign_policy/validation-* - split: dev path: us_foreign_policy/dev-* - config_name: virology data_files: - split: test path: virology/test-* - split: validation path: virology/validation-* - split: dev path: virology/dev-* - config_name: world_religions data_files: - split: test path: world_religions/test-* - split: validation path: world_religions/validation-* - split: dev path: world_religions/dev-* --- # Dataset Card for MMLU ## Table of Contents - [Table of Contents](#table-of-contents) - [Dataset Description](#dataset-description) - [Dataset Summary](#dataset-summary) - [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards) - [Languages](#languages) - [Dataset Structure](#dataset-structure) - [Data Instances](#data-instances) - [Data Fields](#data-fields) - [Data Splits](#data-splits) - [Dataset Creation](#dataset-creation) - [Curation Rationale](#curation-rationale) - [Source Data](#source-data) - [Annotations](#annotations) - [Personal and Sensitive Information](#personal-and-sensitive-information) - [Considerations for Using the Data](#considerations-for-using-the-data) - [Social Impact of Dataset](#social-impact-of-dataset) - [Discussion of Biases](#discussion-of-biases) - [Other Known Limitations](#other-known-limitations) - [Additional Information](#additional-information) - [Dataset Curators](#dataset-curators) - [Licensing Information](#licensing-information) - [Citation Information](#citation-information) - [Contributions](#contributions) ## Dataset Description - **Repository**: https://github.com/hendrycks/test - **Paper**: https://arxiv.org/abs/2009.03300 ### Dataset Summary [Measuring Massive Multitask Language Understanding](https://arxiv.org/pdf/2009.03300) by [Dan Hendrycks](https://people.eecs.berkeley.edu/~hendrycks/), [Collin Burns](http://collinpburns.com), [Steven Basart](https://stevenbas.art), Andy Zou, Mantas Mazeika, [Dawn Song](https://people.eecs.berkeley.edu/~dawnsong/), and [Jacob Steinhardt](https://www.stat.berkeley.edu/~jsteinhardt/) (ICLR 2021). This is a massive multitask test consisting of multiple-choice questions from various branches of knowledge. The test spans subjects in the humanities, social sciences, hard sciences, and other areas that are important for some people to learn. This covers 57 tasks including elementary mathematics, US history, computer science, law, and more. To attain high accuracy on this test, models must possess extensive world knowledge and problem solving ability. A complete list of tasks: ['abstract_algebra', 'anatomy', 'astronomy', 'business_ethics', 'clinical_knowledge', 'college_biology', 'college_chemistry', 'college_computer_science', 'college_mathematics', 'college_medicine', 'college_physics', 'computer_security', 'conceptual_physics', 'econometrics', 'electrical_engineering', 'elementary_mathematics', 'formal_logic', 'global_facts', 'high_school_biology', 'high_school_chemistry', 'high_school_computer_science', 'high_school_european_history', 'high_school_geography', 'high_school_government_and_politics', 'high_school_macroeconomics', 'high_school_mathematics', 'high_school_microeconomics', 'high_school_physics', 'high_school_psychology', 'high_school_statistics', 'high_school_us_history', 'high_school_world_history', 'human_aging', 'human_sexuality', 'international_law', 'jurisprudence', 'logical_fallacies', 'machine_learning', 'management', 'marketing', 'medical_genetics', 'miscellaneous', 'moral_disputes', 'moral_scenarios', 'nutrition', 'philosophy', 'prehistory', 'professional_accounting', 'professional_law', 'professional_medicine', 'professional_psychology', 'public_relations', 'security_studies', 'sociology', 'us_foreign_policy', 'virology', 'world_religions'] ### Supported Tasks and Leaderboards | Model | Authors | Humanities | Social Science | STEM | Other | Average | |------------------------------------|----------|:-------:|:-------:|:-------:|:-------:|:-------:| | [UnifiedQA](https://arxiv.org/abs/2005.00700) | Khashabi et al., 2020 | 45.6 | 56.6 | 40.2 | 54.6 | 48.9 | [GPT-3](https://arxiv.org/abs/2005.14165) (few-shot) | Brown et al., 2020 | 40.8 | 50.4 | 36.7 | 48.8 | 43.9 | [GPT-2](https://arxiv.org/abs/2005.14165) | Radford et al., 2019 | 32.8 | 33.3 | 30.2 | 33.1 | 32.4 | Random Baseline | N/A | 25.0 | 25.0 | 25.0 | 25.0 | 25.0 | 25.0 ### Languages English ## Dataset Structure ### Data Instances An example from anatomy subtask looks as follows: ``` { "question": "What is the embryological origin of the hyoid bone?", "choices": ["The first pharyngeal arch", "The first and second pharyngeal arches", "The second pharyngeal arch", "The second and third pharyngeal arches"], "answer": "D" } ``` ### Data Fields - `question`: a string feature - `choices`: a list of 4 string features - `answer`: a ClassLabel feature ### Data Splits - `auxiliary_train`: auxiliary multiple-choice training questions from ARC, MC_TEST, OBQA, RACE, etc. - `dev`: 5 examples per subtask, meant for few-shot setting - `test`: there are at least 100 examples per subtask | | auxiliary_train | dev | val | test | | ----- | :------: | :-----: | :-----: | :-----: | | TOTAL | 99842 | 285 | 1531 | 14042 ## Dataset Creation ### Curation Rationale Transformer models have driven this recent progress by pretraining on massive text corpora, including all of Wikipedia, thousands of books, and numerous websites. These models consequently see extensive information about specialized topics, most of which is not assessed by existing NLP benchmarks. To bridge the gap between the wide-ranging knowledge that models see during pretraining and the existing measures of success, we introduce a new benchmark for assessing models across a diverse set of subjects that humans learn. ### Source Data #### Initial Data Collection and Normalization [More Information Needed] #### Who are the source language producers? [More Information Needed] ### Annotations #### Annotation process [More Information Needed] #### Who are the annotators? [More Information Needed] ### Personal and Sensitive Information [More Information Needed] ## Considerations for Using the Data ### Social Impact of Dataset [More Information Needed] ### Discussion of Biases [More Information Needed] ### Other Known Limitations [More Information Needed] ## Additional Information ### Dataset Curators [More Information Needed] ### Licensing Information [MIT License](https://github.com/hendrycks/test/blob/master/LICENSE) ### Citation Information If you find this useful in your research, please consider citing the test and also the [ETHICS](https://arxiv.org/abs/2008.02275) dataset it draws from: ``` @article{hendryckstest2021, title={Measuring Massive Multitask Language Understanding}, author={Dan Hendrycks and Collin Burns and Steven Basart and Andy Zou and Mantas Mazeika and Dawn Song and Jacob Steinhardt}, journal={Proceedings of the International Conference on Learning Representations (ICLR)}, year={2021} } @article{hendrycks2021ethics, title={Aligning AI With Shared Human Values}, author={Dan Hendrycks and Collin Burns and Steven Basart and Andrew Critch and Jerry Li and Dawn Song and Jacob Steinhardt}, journal={Proceedings of the International Conference on Learning Representations (ICLR)}, year={2021} } ``` ### Contributions Thanks to [@andyzoujm](https://github.com/andyzoujm) for adding this dataset.
hugging_face 收录