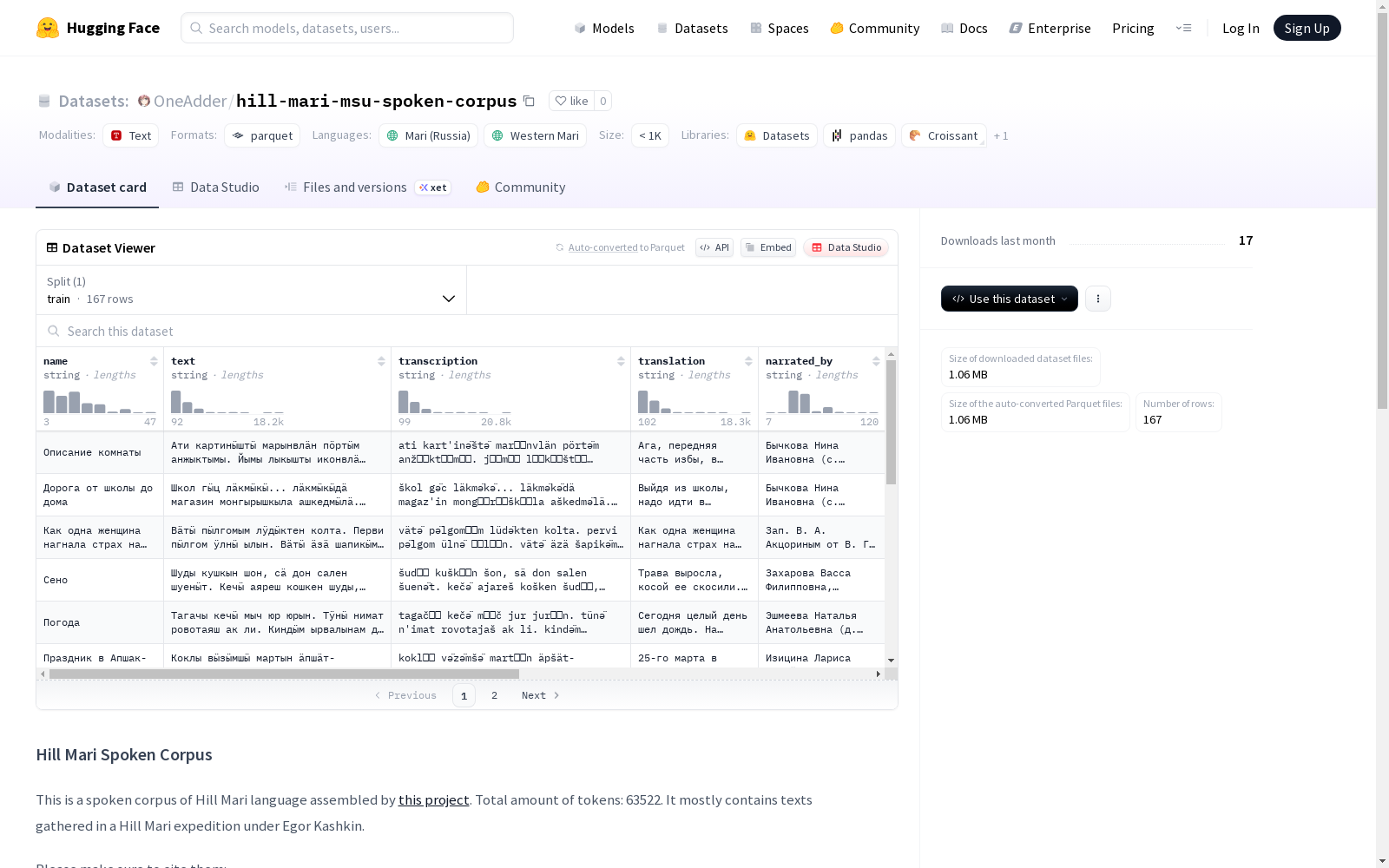
hill-mari-msu-spoken-corpus
收藏Hill Mari Spoken Corpus数据集概述
数据集基本信息
- 语言:Hill Mari (mrj), Chuvash (chm)
- 数据量:167个样本
- 总大小:2,259,898字节
- 下载大小:1,059,662字节
- 数据来源:莫斯科国立大学Hill Mari考察队收集
数据集结构
-
特征字段:
name:名称(字符串)text:文本内容(字符串)transcription:转写文本(字符串)translation:翻译文本(字符串)narrated_by:讲述者(字符串)recorded_by:录制者(字符串)year:年份(字符串)transcribed_by:转写者(字符串)proofread_by:校对者(字符串)glossed_by:注释者(字符串)
-
数据划分:
train:训练集(包含全部167个样本)
内容描述
- 主要内容:包含Hill Mari语言的口语语料,主要为Egor Kashkin领导的Hill Mari考察中收集的文本
- 总词数:63,522个标记
引用信息
主要引用
bibtex @online{hill_mari_msu_corpus, author = {Айгуль Закирова and Анастасия Гарейшина and Анастасия Сибирёва and Анастасия Сиротина and Анита Соловьёва and Анна Бочкова and Вадим Дьячков and Владимир Иванов and Дарья Белова and Дарья Мордашова and Дмитрий Петелин and Егор Кашкин and Егор Кислых and Илья Учитель and Иннокентий Щербинин and Ирина Хомченкова and Ксения Студеникина and Мария Винклер and Наталья Абовьян and Полина Плешак and Татьяна Давидюк and Юлия Синицына}, title = {Материалы горномарийских экспедиций МГУ под рук. Е. В. Кашкина}, titleaddon = {Text Corpus from the Hill Mari Expeditions of Moscow State University under the direction of E. V. Kaškin}, year = 2017, url = {https://hillmari-exp.tilda.ws/corpus}, urldate = {2025-07-19}, note = {English version of the link: https://hillmari-exp.tilda.ws/en/corpus} }
附加引用
bibtex @book{aktsorin1991, author = {B. А. Акцорин}, editor = {C. С. Сабитова}, title = {Марий калык ойпого}, subtitle = {Марийский фольклор. Мифы, легенды, предания}, titleaddon = {Mari Folklore: Myths, Legends, Stories}, year = {1991}, address = {Йошкар-Ола}, publisher = {Марийское книжное издательство}, pagetotal = {288}, } @thesis{savateeva2005, author = {Галина Алексеевна Саватеева}, title = {Лексические особенности правобережных говоров горномарийского языка}, titleaddon = {Lexical Peculiarities of the Right-Bank Local Varieties of Hill Mari}, type = {PhD dissertation in Philology}, institution = {Марийский государственный университет}, address = {Йошкар-Ола}, year = {2005}, language = {russian}, }