unlearning-cleanslate/eval-22-debug-llama-3_1-8b-simnpo-gentle-bm25-6t-target-100-localtrain-checkpoint-1
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/unlearning-cleanslate/eval-22-debug-llama-3_1-8b-simnpo-gentle-bm25-6t-target-100-localtrain-checkpoint-1
下载链接
链接失效反馈官方服务:
资源简介:
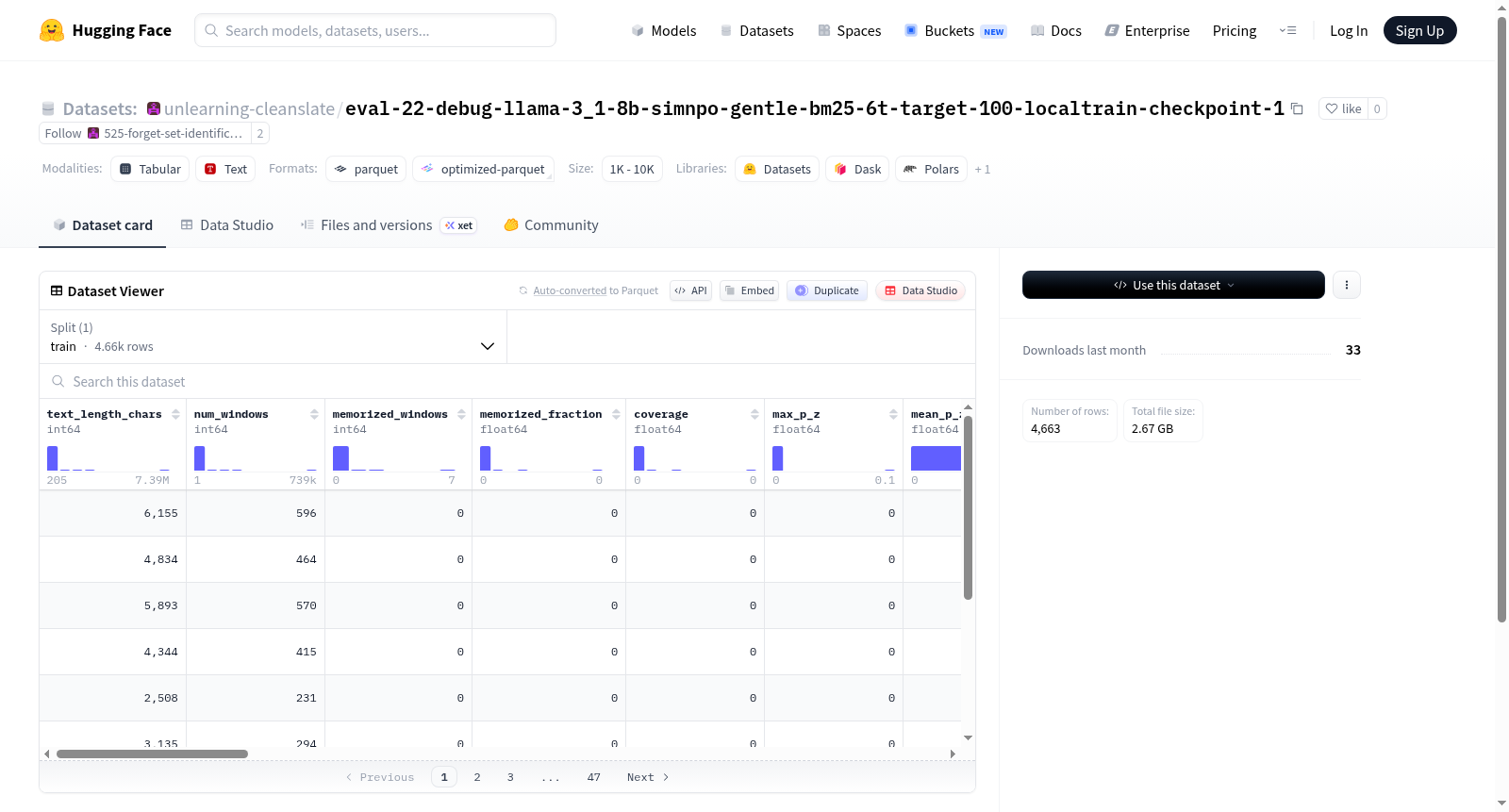
该数据集包含与文本分析相关的详细特征,如文本长度、窗口统计、记忆化指标和各种概率测量。数据集还包括内容的ID、标题、创作者和年份等信息。它有一个单独的train分割,包含大量示例和字节。这些特征表明该数据集用于评估文本窗口的记忆化和概率特性。
The dataset contains detailed features related to text analysis, such as text length, window statistics, memorization metrics, and various probability measures. The dataset also includes information about content such as ID, title, creators, and year. It has a single train split with a large number of examples and bytes. The features suggest the dataset is used for evaluating memorization and probabilistic characteristics of text windows.
提供机构:
unlearning-cleanslate
搜集汇总
数据集介绍
构建方式
该数据集是为评估大语言模型对特定领域文本的记忆程度而构建的,其生成过程基于对模型输出内容的细粒度分析。具体而言,研究者采用滑动窗口技术将原始文本切分为多个片段,并利用Llama-3.1-8B模型(经SimNPO与Gentle策略微调)逐一计算每个窗口的log概率、目标标记的排序及记忆状态。通过BM25算法筛选与原始文本高度相关的目标序列,最终汇总出覆盖度、记忆分数(如memorized_fraction)及最佳窗口特征,形成包含4663个训练样本的结构化评估集。
特点
该数据集的核心特色在于其多维度的记忆量化指标,涵盖了从字符级文本长度到窗口级记忆状态的全面信息。每个样本不仅记录了整篇文本的统计特征(如平均概率密度max_p_z、标准差std_p_z等),还详细刻画了最优窗口的种子、目标序列及字符起止位置,使研究者能精确定位模型记忆的具体片段。此外,windows字段中嵌套的逐窗口数据(如log_prob、target_ranks等)提供了粒度极细的记忆剖析能力,适合用于探究模型记忆机制与长度效应。
使用方法
该数据集适用于大语言模型记忆行为的诊断与对比研究。使用者可直接加载HuggingFace上的数据集,提取每个样本的memorized_fraction等全局指标进行批次分析,或遍历windows列表深入检查特定窗口的模型输出。由于数据已按固定分割(train split)组织,便于直接用于训练分类器或作为评估基准。建议结合原始文本内容与best_window_target字段,验证模型记忆是否源于训练数据泄露或过拟合现象,从而指导后续的隐私保护与模型优化策略。
背景与挑战
背景概述
该数据集名为 eval-22-debug-llama-3_1-8b-simnpo-gentle-bm25-6t-target-100-localtrain-checkpoint-1,诞生于大语言模型(LLM)记忆化现象研究的前沿领域。由相关研究团队构建,其核心目标在于系统性地评估和诊断 LLM 在文本生成过程中对训练数据的记忆程度,特别是针对通过 SimNPO 等偏好优化算法微调后的模型。数据集聚焦于细粒度的记忆化指标,如滑动窗口内的 p_z 值、覆盖率和最佳记忆窗口特征,为理解模型是否以及如何泄露私有训练语料提供了量化工具。该成果对于提升 LLM 的安全性和隐私保护能力具有重要影响,为后续模型审计与幻觉矫正研究奠定了数据基础。
当前挑战
该数据集面临的核心挑战在于精准界定和量化 LLM 的记忆化边界。领域问题层面,现有记忆评估方法多依赖于精确字符串匹配,难以捕捉模型对语义相似而非逐字复制内容的隐式记忆,导致评价指标存在偏差。构建过程中,挑战主要源于大规模数据的高效处理与窗口化分析:需要从超长文本中合理划分滑动窗口,确定最优窗口大小和步长以避免计算开销爆炸,同时保证每个窗口中的目标片段能够反映真实的记忆程度。此外,跨窗口的统计量(如 p_z 的均值与方差)对噪声敏感,需要设计鲁棒的阈值判定策略来区分偶然生成与确定性记忆,这进一步增加了数据标注和模型评估的复杂性。
常用场景
经典使用场景
该数据集旨在服务于大语言模型的记忆行为评估与调试场景,尤其聚焦于模型对特定训练数据的片段级记忆程度。通过提供详尽的窗口化分析指标(如文本长度、滑动窗口数量、记忆窗口占比、记忆分数及p值分布等),研究人员能够精准量化模型在生成过程中是否复现了训练语料中的具体内容。这一设计使其成为检验模型泛化能力与记忆边界的理想基准,广泛应用于对比不同训练策略、正则化手段或模型架构对记忆倾向的影响。
衍生相关工作
该数据集的出现催生了一系列关于模型记忆机制与缓解策略的高影响力研究。基于其窗口化评估框架,衍生工作包括:对比监督微调、强化学习与偏好优化等训练范式对记忆程度的影响;探索基于剪枝、噪声注入或成员推断防御的记忆减轻技术;开发自动化审计流水线,将记忆检测无缝集成至模型开发周期。此外,该数据集所定义的评估指标(如记忆分数与p值)已被后续研究采纳为标准化测评工具,用于评价新提出的反记忆训练方法与数据去重策略的效果,形成了持续演进的研究脉络。
数据集最近研究
最新研究方向
该数据集聚焦于大语言模型在训练过程中对特定文本片段的记忆化程度评估,尤其是针对LLaMA-3.1-8B模型经过SimNPO偏好优化后的表现。通过分析滑动窗口内的token概率分布、记忆窗口比例及覆盖度,该研究为理解模型是否过度记忆训练数据中的敏感或私有内容提供了量化工具。这一方向与当前AI安全领域的热点——模型遗忘学习与隐私保护——紧密相连,尤其在欧盟《人工智能法案》等法规推动下,如何精准检测并缓解模型对训练数据的记忆化泄露成为前沿议题。该数据集通过细粒度的窗口级评估指标,如最佳窗口的p_z值及目标文本的token对数概率,为后续研究模型压缩、数据去重及对抗性遗忘提供了可复现的基准,对于构建更鲁棒且符合伦理的语言模型具有重要实践意义。
以上内容由遇见数据集搜集并总结生成


