CONFLICTS
收藏github2025-06-11 更新2025-06-16 收录
下载链接:
https://github.com/google-research-datasets/rag_conflicts
下载链接
链接失效反馈官方服务:
资源简介:
CONFLICTS是一个带有知识冲突类型标注的QA数据集。每个实例包括一个查询、一组检索到的相关段落、相应的冲突类型标签,以及特定类型的正确答案。
CONFLICTS is a QA dataset annotated with knowledge conflict types. Each instance includes a query, a set of retrieved relevant paragraphs, the corresponding conflict type label, and the correct answer of a specific type.
创建时间:
2025-06-06
原始信息汇总
CONFLICTS 数据集概述
数据集来源
- 数据集来源于论文《DRAGged into CONFLICTS: Detecting and Addressing Conflicting Sources in Search-Augmented LLMs》,作者包括Arie Cattan等。
数据结构
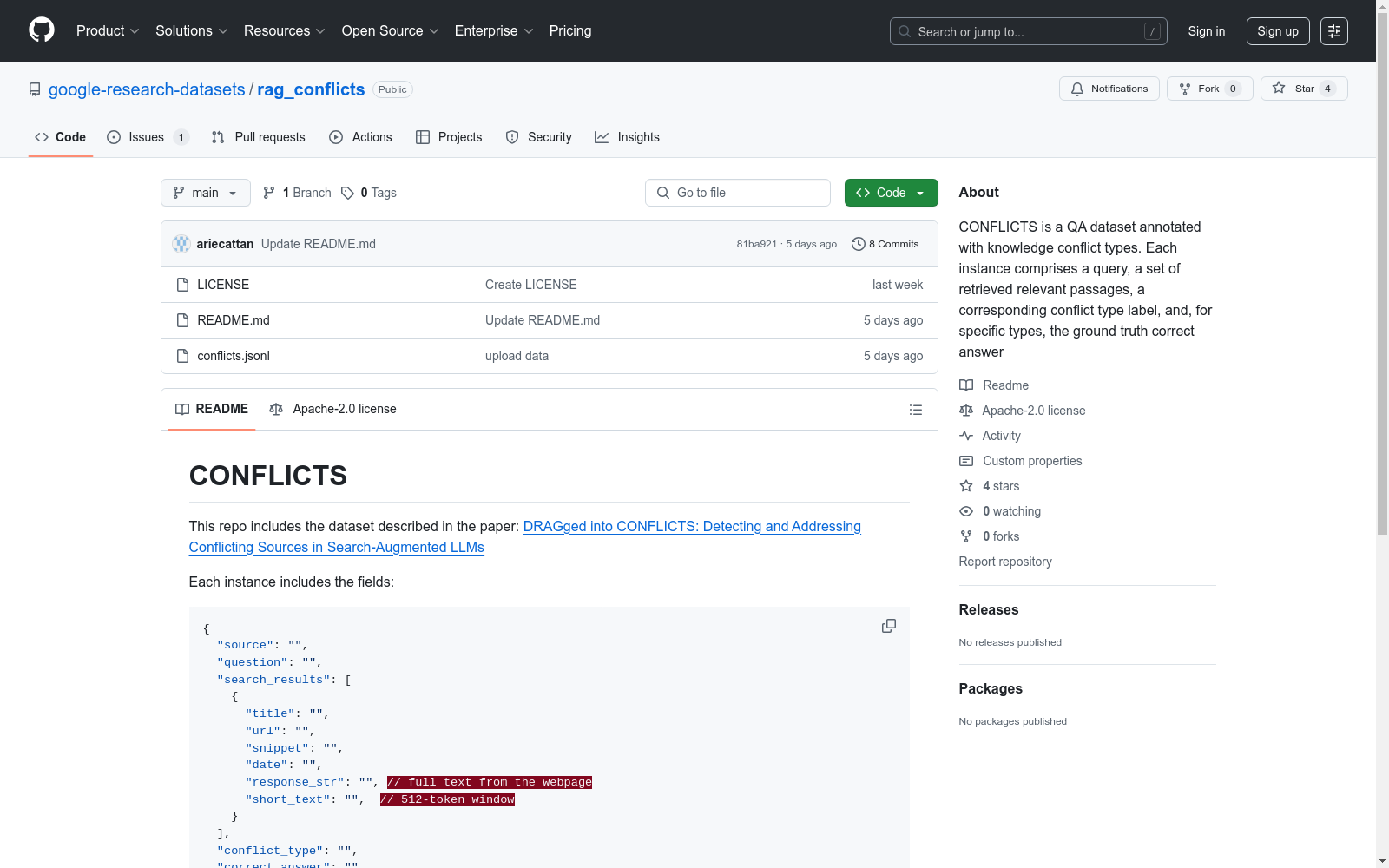
- 每个实例包含以下字段:
source: 来源question: 问题search_results: 搜索结果列表,包含以下子字段:title: 标题url: URL地址snippet: 摘要date: 日期response_str: 网页全文short_text: 512个token的文本窗口
conflict_type: 冲突类型correct_answer: 正确答案
引用信息
bibtex @article{cattan2025dragged, title={DRAGged into CONFLICTS: Detecting and Addressing Conflicting Sources in Search-Augmented LLMs}, author={Arie Cattan and Alon Jacovi and Ori Ram and Jonathan Herzig and Roee Aharoni and Sasha Goldshtein and Eran Ofek and Idan Szpektor and Avi Caciularu}, journal={ArXiv}, year={2025}, volume={abs/2506.08500}, }
免责声明
- 本数据集并非Google官方产品。
搜集汇总
数据集介绍
构建方式
CONFLICTS数据集构建于搜索增强型大语言模型(LLMs)领域,旨在检测和处理搜索源中的冲突信息。该数据集通过系统化地收集网络搜索结果的多样化响应,精心构建了包含冲突信息的实例。每个实例均包含原始问题、多个搜索结果的完整文本片段及摘要,并标注了冲突类型和正确答案,数据来源于真实网络环境下的多源异构信息。
特点
该数据集的核心特点在于其精细标注的冲突类型和正确答案,为研究搜索增强型LLMs在处理冲突信息时的表现提供了基准。数据集中的每个实例不仅包含原始搜索结果的完整文本,还提供了512个token的摘要窗口,便于模型处理长文本。多源异构的搜索结果为研究信息可信度评估和冲突消解算法提供了丰富的实验素材。
使用方法
使用该数据集时,研究人员可通过加载标准化的JSON格式数据,快速访问问题、搜索结果及标注信息。数据集适用于训练和评估模型在冲突信息检测与处理方面的能力,特别适合用于搜索增强型LLMs的鲁棒性研究。通过分析conflict_type字段,可针对特定类型的冲突设计专门的解决方案,而correct_answer则为模型性能评估提供了黄金标准。
背景与挑战
背景概述
CONFLICTS数据集由Google研究团队于2025年推出,核心研究聚焦于搜索增强型大语言模型(LLMs)中冲突源的检测与处理。该数据集源于Arie Cattan等学者在ArXiv发表的论文,旨在解决多源信息检索场景下LLMs面临的答案一致性挑战。作为首个系统化标注冲突类型的语料库,其通过结构化记录网页标题、摘要、全文及标准答案,为提升模型在真实网络环境中的推理可靠性提供了重要基准。
当前挑战
该数据集针对搜索增强LLMs领域的两大核心挑战:多源信息冲突消解与噪声干扰下的答案生成。构建过程中需克服网页文本动态性带来的标注困难,包括时效性内容更新、片段截断导致的语义损失,以及人工验证高冲突样本的复杂度。数据采集还需平衡不同冲突类型(如事实矛盾、表述歧义)的分布,确保模型评估的全面性。
常用场景
经典使用场景
在自然语言处理领域,CONFLICTS数据集为研究搜索增强型大语言模型(LLMs)中的冲突源检测与处理提供了重要支持。该数据集通过模拟真实搜索场景中的信息冲突,帮助研究者分析模型在面对相互矛盾的信息源时的表现。典型的使用场景包括评估模型在信息检索与整合过程中的鲁棒性,以及验证不同冲突解决策略的有效性。数据集的结构化设计使得研究者能够深入探究冲突类型对模型输出的影响。
解决学术问题
CONFLICTS数据集有效解决了搜索增强型LLMs领域的关键学术问题,即如何识别和处理来自不同信息源的冲突内容。通过提供标注的冲突类型和正确答案,该数据集为研究模型在信息整合过程中的偏差和错误提供了基准。其意义在于推动了模型可信度评估方法的发展,并为构建更可靠的搜索增强系统奠定了数据基础。这一资源填补了该领域缺乏标准评估数据的空白。
衍生相关工作
围绕CONFLICTS数据集已经产生了一系列重要研究工作,包括冲突检测算法的改进、多源信息可信度评估框架的构建等。该数据集启发了对搜索增强型LLMs鲁棒性的系统性研究,推动了如冲突消解模型、信息可信度评分机制等创新方法的出现。这些衍生工作共同促进了搜索增强技术在真实场景中的应用落地。
以上内容由遇见数据集搜集并总结生成


