pixelprose-shards
收藏Hugging Face2025-12-14 更新2025-12-15 收录
下载链接:
https://huggingface.co/datasets/pixelprose/pixelprose-shards
下载链接
链接失效反馈官方服务:
资源简介:
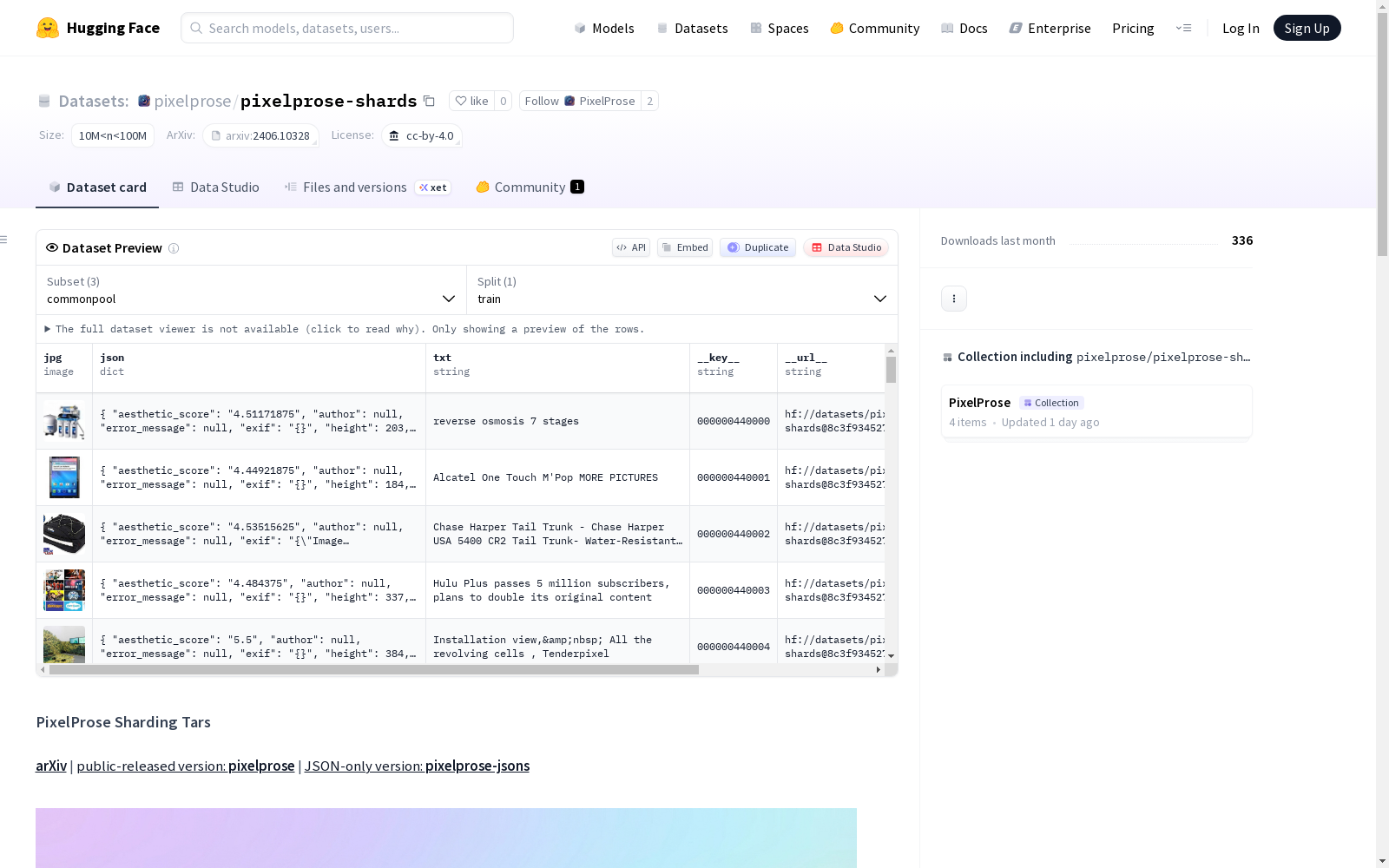
pixelprose-shards是一个包含图像、文本和JSON文件三元组的数据集,分为commonpool、cc12m和redcaps三个部分。每个tar文件大小约为500-600MB,便于快速采样和加载。数据集总共有16,874,890个三元组,其中commonpool有6,521,737个,cc12m有9,066,468个,redcaps有1,286,685个。文本文件包含原始标题,JSON文件包含所有相关信息。由于Gemini-1.0内部版本的变化,建议过滤掉短标题(如少于50个字符)。数据集还包含一些重复的三元组和由于URL损坏而缺失的图像。
The pixelprose-shards dataset is composed of triplets of images, text files, and JSON files, and is split into three subsets: commonpool, cc12m, and redcaps. Each tar archive has a size of approximately 500–600 MB, facilitating rapid sampling and loading. The full dataset contains a total of 16,874,890 triplets, broken down as 6,521,737 in commonpool, 9,066,468 in cc12m, and 1,286,685 in redcaps. The text files hold the original image captions, while the JSON files store all relevant associated information. Owing to internal version changes of Gemini-1.0, it is advisable to filter out captions with fewer than 50 characters. Additionally, the dataset includes some duplicate triplets as well as images missing due to corrupted URLs.
创建时间:
2025-12-13
原始信息汇总
PixelProse Shards 数据集概述
数据集基本信息
- 数据集名称:pixelprose-shards
- 许可证:cc-by-4.0
- 数据规模:10M < n < 100M
- 总数据量:16,874,890 (16.8M) 个三元组(图像、文本和JSON文件)
配置与结构
数据集包含三个配置(configs),每个配置对应一个数据子集:
- commonpool(默认配置)
- 数据文件路径模式:
commonpool_node*_part*/*.tar - 三元组总数:6,521,737
- 数据文件路径模式:
- cc12m
- 数据文件路径模式:
cc12m_part*/*.tar - 三元组总数:9,066,468
- 数据文件路径模式:
- redcaps
- 数据文件路径模式:
redcaps_part*/*.tar - 三元组总数:1,286,685
- 数据文件路径模式:
数据文件详情
- 文件格式:每个tar文件大小约为500-600 MB。
- 文件内容:每个tar文件包含图像、文本(.txt)和JSON(.json)文件的三元组。
*.txt文件包含原始描述。*.json文件包含所有相关信息。
各子集详细说明
commonpool
- 总三元组数:6,521,737
- 分片详情:
commonpool_node[0-5]_part[0-6]:6,066,616 个三元组,由 Gemini-1.0-Pro 生成描述。commonpool_node[d]_part[0]:455,121 个三元组,由早期Gemini版本生成,存在重复三元组。
- JSON文件备注:对于早期Gemini版本生成的数据,
vlm_model = None。 - 与已发布HF数据集对比:已发布数据集包含6,083,777个唯一uid和455,121个重复uid,总计6,538,898张图像。有17,161张图像因链接失效而缺失。
cc12m
- 总三元组数:9,066,468
- 分片详情:
cc12m_part[0-9]:8,987,898 个三元组,由 Gemini-1.0-Pro 生成描述。cc12m_part[d]:78,570 个三元组,由 Gemini-1.0-Pro 生成,存在重复三元组,其中包含约31,000张因链接失效而生成的占位符类型图像。
- 与已发布HF数据集对比:已发布数据集包含8,987,886个唯一uid、26,829个重复uid和78,569张重复图像,总计9,066,455张图像。本仓库额外包含13张图像。
redcaps
- 总三元组数:1,286,685
- 分片详情:
redcaps_part[0-6]:1,269,304 个三元组,由 Gemini-1.0-Pro 生成描述。redcaps_part[d]:17,381 个三元组,由 Gemini-1.0-Pro 生成,存在重复三元组。
- 与已发布HF数据集对比:已发布数据集包含1,270,176个唯一uid、16,800个重复uid和20,685张重复图像,总计1,290,861张图像。有4,176张图像因链接失效而缺失。
使用注意
- 由于数据生成过程中使用的Gemini-1.0内部版本发生变化,如需可考虑过滤掉短描述(例如少于50个字符)。
- 有关短描述的参考,请查看数据集查看器:https://huggingface.co/datasets/tomg-group-umd/pixelprose。
下载方式
可通过 huggingface_hub 库的 snapshot_download 函数下载数据集。
搜集汇总
数据集介绍
构建方式
在视觉语言模型蓬勃发展的背景下,pixelprose-shards数据集通过整合多个知名图像-文本对来源构建而成。其核心方法是将CommonPool、CC12M和RedCaps等原始数据集进行统一处理,利用Gemini-1.0-Pro模型为图像生成高质量的文本描述,形成图像、原始文本和包含元信息的JSON文件的三元组。数据被精心组织成数百个大小约为500-600MB的tar文件分片,这种分片策略不仅便于分布式存储,也优化了数据加载效率。构建过程中还细致标注了因模型版本迭代或源URL失效而产生的少量重复或缺失样本,确保了数据集的完整性与可追溯性。
特点
该数据集最显著的特征在于其庞大的规模与精良的组织结构,总计提供约1680万条高质量图像-文本对。每个数据单元均由图像、原始描述文本和富含元数据的JSON文件构成,为多模态研究提供了丰富的上下文信息。数据集采用分片存储设计,每个tar文件大小适中,极大地便利了在数据加载器中进行动态采样、过滤和流式读取。此外,数据集明确区分了来自CommonPool、CC12M和RedCaps三个子集的样本,并详细记录了其中因技术原因产生的重复项与占位符图像,赋予了研究者高度的数据透明度和使用的灵活性。
使用方法
为高效利用该数据集,研究者可通过Hugging Face Hub提供的snapshot_download接口进行下载,并指定并行工作线程数以加速过程。数据加载后,用户可根据研究需求,灵活选择commonpool、cc12m或redcaps等配置。由于数据集已预打包为分片文件,可直接集成到训练流程中,实现无需解压的实时流式读取与样本过滤。针对部分由早期Gemini版本生成的简短描述,使用者可依据字符长度等条件进行筛选,以确保输入文本的质量,满足特定视觉语言预训练或生成式任务对数据一致性的要求。
背景与挑战
背景概述
PixelProse Shards数据集由马里兰大学汤姆·戈德斯坦研究团队于2024年构建,旨在为视觉语言模型训练提供大规模、高质量的图像-文本对数据。该数据集整合了CommonPool、CC12M和RedCaps等多个来源,共计约1680万条三元组数据,每条数据包含图像、原始文本描述及结构化JSON元信息。其核心研究问题聚焦于解决多模态预训练中数据稀缺与质量不均的瓶颈,通过利用Gemini-1.0-Pro等先进模型生成精准描述,显著提升了数据集的语义一致性与多样性,为图像生成、跨模态检索等任务提供了关键资源。
当前挑战
该数据集致力于应对视觉语言预训练领域的数据质量与规模平衡难题,具体挑战包括:在领域问题层面,需确保图像与文本描述间的高语义对齐,并克服多源数据异构性带来的标注噪声;在构建过程中,面临Gemini模型内部版本迭代导致的描述长度不一致,需设计过滤策略以剔除过短文本。同时,数据整合时出现部分URL失效引发的图像缺失,以及跨分片重复样本的识别与处理,均对数据集的完整性与纯净度构成技术考验。
常用场景
经典使用场景
在视觉语言预训练领域,pixelprose-shards数据集以其大规模图像-文本对资源,成为多模态模型训练的基石。该数据集通过精心分片的结构,每个tar文件约500-600MB,便于在数据加载器中实现快速采样与过滤,极大优化了训练流程。研究人员通常利用其丰富的图文对,进行对比学习或生成式任务的端到端训练,为模型提供高质量的语义对齐素材。
解决学术问题
该数据集有效缓解了视觉语言模型中数据稀缺与质量不均的学术挑战。通过整合CommonPool、CC12M和RedCaps等来源,并采用Gemini-1.0-Pro生成描述,它提供了超过1680万条图文三元组,解决了传统数据标注成本高昂、规模有限的问题。其结构化JSON文件包含完整元信息,支持细粒度数据筛选,为多模态表征学习、跨模态检索等研究提供了可靠基准。
衍生相关工作
围绕该数据集衍生的经典工作,主要集中在多模态模型架构与训练方法的创新上。许多研究利用其分片设计优化大规模分布式训练,探索更高效的视觉语言融合策略。此外,基于其提供的Gemini生成文本,学者们深入分析了合成描述对模型泛化能力的影响,推动了数据清洗与增强技术的进步,为后续数据集的构建提供了重要参考。
以上内容由遇见数据集搜集并总结生成


