SAUSAGE-CRAFTING-sample
收藏Hugging Face2025-12-22 更新2025-12-23 收录
下载链接:
https://huggingface.co/datasets/orgn3ai/SAUSAGE-CRAFTING-sample
下载链接
链接失效反馈官方服务:
资源简介:
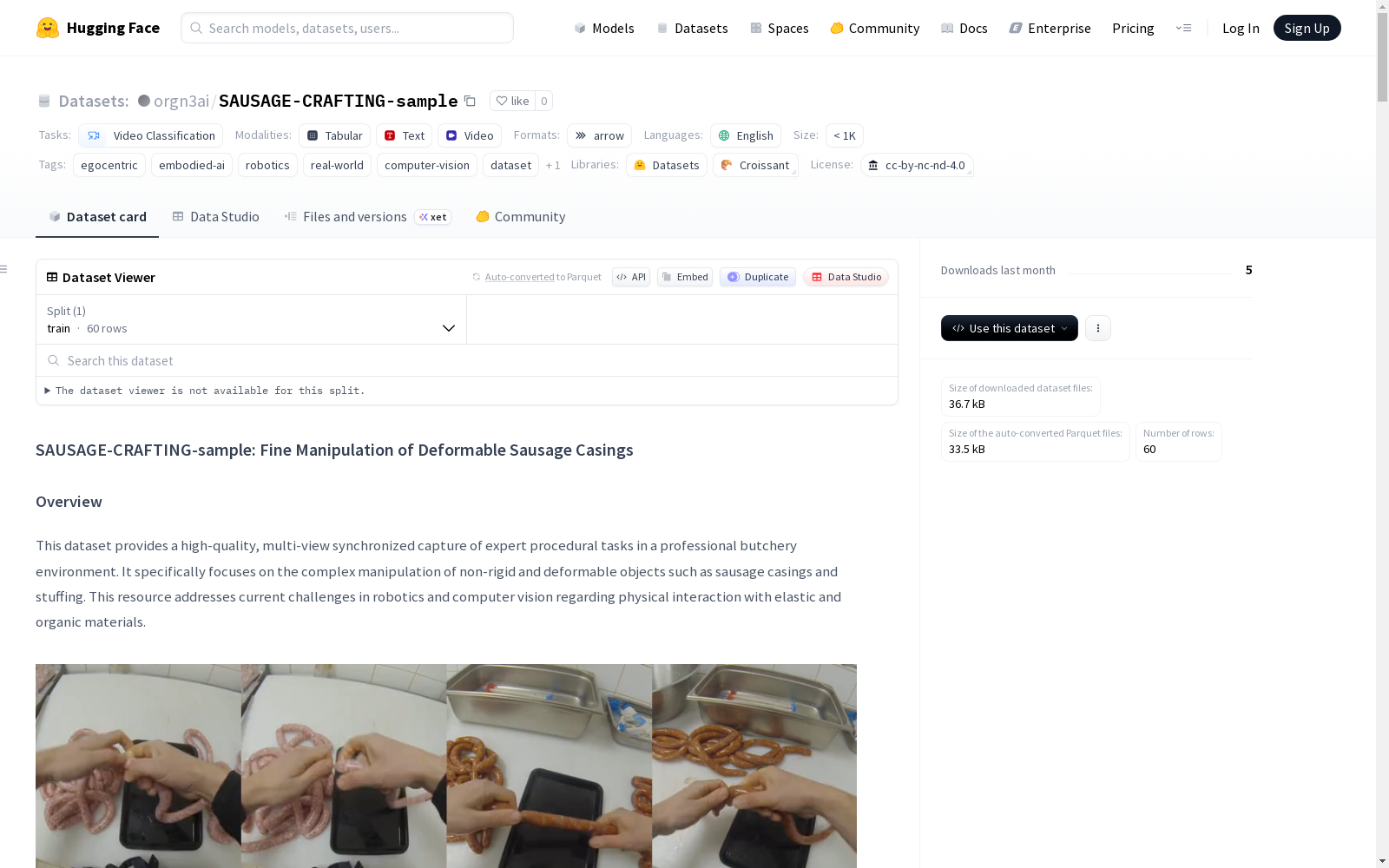
SAUSAGE-CRAFTING-sample数据集是一个高质量、多视角同步捕捉的专业香肠制作过程的数据集,特别关注非刚性和可变形物体(如香肠肠衣和填充物)的复杂操作。数据集包含双视角(第一人称视角和第三人称视角)同步视频,捕捉了材料在香肠制作过程中的弹性和塑性行为。数据集适用于机器人学、计算机视觉、AI代理训练等领域的研究。数据集包含120个同步场景,总时长为8分钟,每个场景包含两个同步视频流(ego和third),每个视频流的持续时间为4秒。数据集还提供了详细的元数据,包括场景ID、同步ID、持续时间等。
创建时间:
2025-12-19
原始信息汇总
SAUSAGE-CRAFTING-sample 数据集概述
数据集基本信息
- 数据集名称: SAUSAGE-CRAFTING-sample: Fine Manipulation of Deformable Sausage Casings
- 许可协议: cc-by-nc-nd-4.0
- 任务类别: 视频分类
- 主要语言: 英语
- 规模类别: n<1K
数据集核心描述
该数据集提供了专业屠宰环境中专家程序化任务的高质量、多视角同步采集数据,特别关注香肠肠衣和馅料等非刚性和可变形物体的复杂操作。该资源旨在解决当前机器人和计算机视觉领域在与弹性和有机材料进行物理交互方面面临的挑战。
关键特征
- 同步双视角: 包含完美对齐的自我中心视角(第一人称视角)和第三人称视角。
- 非刚性物理: 捕捉香肠制作过程中如塑性和弹性等复杂的材料行为。
- 高质量同步: 所有视角均使用统一的
sync_id进行精确时间对齐,以确保无缝的跨模态理解。 - 专家工艺: 专注于以专业技巧进行香肠肠衣卷制和测量的特定任务。
数据集统计信息
总体统计
- 批次ID: 01
- 总剪辑数: 120
- 序列数量: 6
- 流数量: 2
- 流类型: ego, third
时长统计
- 总时长: 8.00分钟 (480.00秒)
- 平均剪辑时长: 4.00秒
- 最短剪辑时长: 4.00秒
- 最长剪辑时长: 4.00秒
剪辑配置
- 基础剪辑时长: 3.00秒
- 带填充的剪辑时长: 4.00秒
- 填充: 500毫秒
按流类型统计
Ego(自我中心视角)
- 剪辑数量: 60
- 总时长: 4.00分钟 (240.00秒)
- 平均剪辑时长: 4.00秒
- 最短剪辑时长: 4.00秒
- 最长剪辑时长: 4.00秒
Third(第三人称视角)
- 剪辑数量: 60
- 总时长: 4.00分钟 (240.00秒)
- 平均剪辑时长: 4.00秒
- 最短剪辑时长: 4.00秒
- 最长剪辑时长: 4.00秒
数据集结构
数据集采用统一结构,每个示例包含所有同步的视频流:
dataset/ ├── data-*.arrow # 数据集文件(Arrow格式) ├── dataset_info.json # 数据集元数据 ├── dataset_metadata.json # 完整的数据集统计信息 ├── state.json # 数据集状态 ├── README.md # 说明文件 ├── medias/ # 媒体文件(拼接视频、预览等) │ └── mosaic.mp4 # 拼接预览视频(绝对地址:https://huggingface.co/datasets/orgn3ai/SAUSAGE-CRAFTING-sample/resolve/main/medias/mosaic.mp4) └── videos/ # 所有视频剪辑 └── ego/ # 自我中心视角视频剪辑 └── third/ # 第三人称视角视频剪辑
数据集格式
数据集在单个train分割中包含120个同步场景。每个示例包括:
- 同步视频列: 每种流类型一列(例如,
ego_video,third_video) - 场景元数据:
scene_id,sync_id,duration_sec,fps - 丰富的元数据字典: 任务、环境、音频信息和同步细节
单个示例中的所有视频都是同步的,并对应于同一时刻。
数据集特征
每个示例包含:
scene_id: 唯一场景标识符(例如,"01_0000")sync_id: 链接同步剪辑的同步IDduration_sec: 同步剪辑的时长(秒)fps: 每秒帧数(默认:30.0)batch_id: 批次标识符dataset_name: 配置中的数据集名称ego_video: 自我中心视角的视频对象(Hugging FaceVideo类型,decode=False,存储路径)third_video: 第三人称视角的视频对象(Hugging FaceVideo类型,decode=False,存储路径)metadata: 包含以下内容的字典:task: 任务标识符environment: 环境描述has_audio: 视频是否包含音频num_fluxes: 同步流类型的数量flux_names: 存在的流名称列表sequence_ids: 原始序列ID列表sync_offsets_ms: 同步偏移列表
研究用途
- 具身AI与世界模型: 训练智能体预测与可变形有机物质交互的物理后果。
- 程序化任务学习: 对专家意图至关重要的长序列动作进行建模。
- 触觉-视觉推理: 通过观察精细操作的视觉信息来学习估计力和材料阻力。
完整数据集规格(相关服务提及)
- 专家音频解说: 现场解说,解释意图、触觉反馈和专业启发式方法。
- 总时长: 超过50小时的连续专业专家操作。
- 扩展任务: 包括馅料准备、肠衣填充和专用工具维护。
- 数据质量: 原生4K分辨率和全面的时间动作标注。
商业许可与联系
- 完整数据集和定制采集服务可用于商业许可和大规模研发。
- 联系邮箱: orgn3ai@gmail.com
搜集汇总
数据集介绍
构建方式
在专业屠宰环境中,该数据集通过多视角同步采集技术构建而成,聚焦于非刚性物体如香肠肠衣的精细操作过程。构建过程涉及双视角视频流的精确时间对齐,利用统一同步标识符确保跨模态数据的一致性。数据采集在真实世界场景中进行,捕捉了专家级操作流程,涵盖了从材料准备到工具维护的完整任务链,为研究提供了高质量、结构化的视觉序列。
特点
该数据集的核心特征在于其双视角同步捕获能力,同时提供第一人称和第三人称视角,完美呈现了非刚性物体的复杂物理行为。视频流经过严格的时间对齐处理,确保了跨视角数据的一致性,便于进行多模态学习分析。数据集专注于香肠制作中的精细操作,展现了材料弹性和塑性的动态变化,为研究提供了真实且高保真的视觉素材。
使用方法
研究人员可通过Hugging Face的`datasets`库直接加载该数据集,利用其统一的Arrow格式结构访问同步视频流。每个数据样本包含`ego_video`和`third_video`两个视频列,以及丰富的元数据字段如`scene_id`和`sync_id`。用户可基于`train`分割进行数据迭代,通过过滤操作按同步标识符或元数据条件筛选特定场景,进而开展具身智能或物理交互预测等研究任务。
背景与挑战
背景概述
在具身人工智能与机器人学领域,对非刚性、可变形物体的精细操作一直是核心挑战之一。SAUSAGE-CRAFTING-sample数据集由orgn3ai团队创建,专注于记录专业屠夫环境中香肠肠衣等弹性有机材料的复杂处理过程。该数据集通过同步的双视角采集,包括第一人称和第三人称视频流,旨在为物理交互、世界模型构建以及长序列程序性任务学习提供高质量的真实世界数据。其核心研究问题在于如何让智能体理解并预测对可变形物体施加动作所产生的物理后果,从而推动机器人在非结构化环境中的灵巧操作能力发展。
当前挑战
该数据集致力于解决机器人视觉与操作中针对可变形物体交互的领域挑战,具体包括从视觉观察中推断触觉反馈(如力与材料阻力),以及对长时程、依赖专家意图的程序性动作进行建模。在构建过程中,挑战主要源于在动态、非受控的专业环境中实现多模态数据的高质量同步采集,例如确保双视角视频流的时间精准对齐,以及捕捉材料在受力下表现出的塑性、弹性等复杂物理行为。此外,如何将专业领域的隐性知识(如屠夫的技巧与启发式决策)转化为可计算、可注释的数据形式,也是数据集构建面临的关键难题。
常用场景
经典使用场景
在具身人工智能与机器人学领域,SAUSAGE-CRAFTING-sample数据集为研究非刚性物体的精细操作提供了经典范例。该数据集通过同步的双视角视频,捕捉了专业屠夫处理香肠肠衣等可变形有机材料的完整过程,其核心应用在于训练智能体理解并预测对弹性物质进行物理交互时产生的复杂形变与力学响应。研究者可利用这一多模态数据,构建能够模拟真实世界物理交互的世界模型,从而推动机器人在柔性物体操控方面的能力突破。
实际应用
超越纯学术研究,SAUSAGE-CRAFTING-sample数据集的实际价值延伸至多个工业与专业场景。在食品加工自动化领域,它可为开发能够处理生鲜肉类、面团等易变形产品的机器人提供关键训练数据。同时,其数据采集范式——在真实专业环境中同步记录第一人称与第三人称视角——可被复用于医疗手术辅助机器人训练、精密装配工艺学习以及任何需要传递专家隐性知识的技能自动化场景,加速了人工智能从实验室走向实际应用的进程。
衍生相关工作
围绕该数据集所代表的真实世界可变形物体操作范式,已衍生出一系列经典研究工作。这些工作主要集中在基于视觉的物理属性预测、从演示中学习精细操作策略,以及多模态(视觉-触觉)表征学习等领域。数据集提供的专家音频解说与同步多视角视频,进一步催生了旨在理解操作意图与专业启发式知识的研究,推动了从被动观察到主动物理交互的具身智能模型发展,为后续在更广泛材料与场景下的机器人技能学习设立了基准。
以上内容由遇见数据集搜集并总结生成


