wikifragments
收藏Hugging Face2025-08-06 更新2025-08-07 收录
下载链接:
https://huggingface.co/datasets/nicolafan/wikifragments
下载链接
链接失效反馈官方服务:
资源简介:
WikiFragments是一个多模态数据集,由Wikipedia的英文版构建而成,包含清理后的文本段落及其相关图片。每个文本段落都配有一组图片,形成了一个多模态片段,适合用于信息检索和多模态研究。
创建时间:
2025-08-05
原始信息汇总
WikiFragments数据集概述
数据集基本信息
- 名称: WikiFragments
- 类型: 多模态数据集
- 语言: 英语
- 数据来源: 英文维基百科
- 许可协议:
- 代码: MIT License
- 文本数据: CC BY-SA 4.0
- 图像: 遵循各自原始页面的许可协议
- 数据集大小: 58,037,298,060.96字节
- 下载大小: 47,531,941,595字节
- 样本数量: 42,482,460
数据集结构
特征
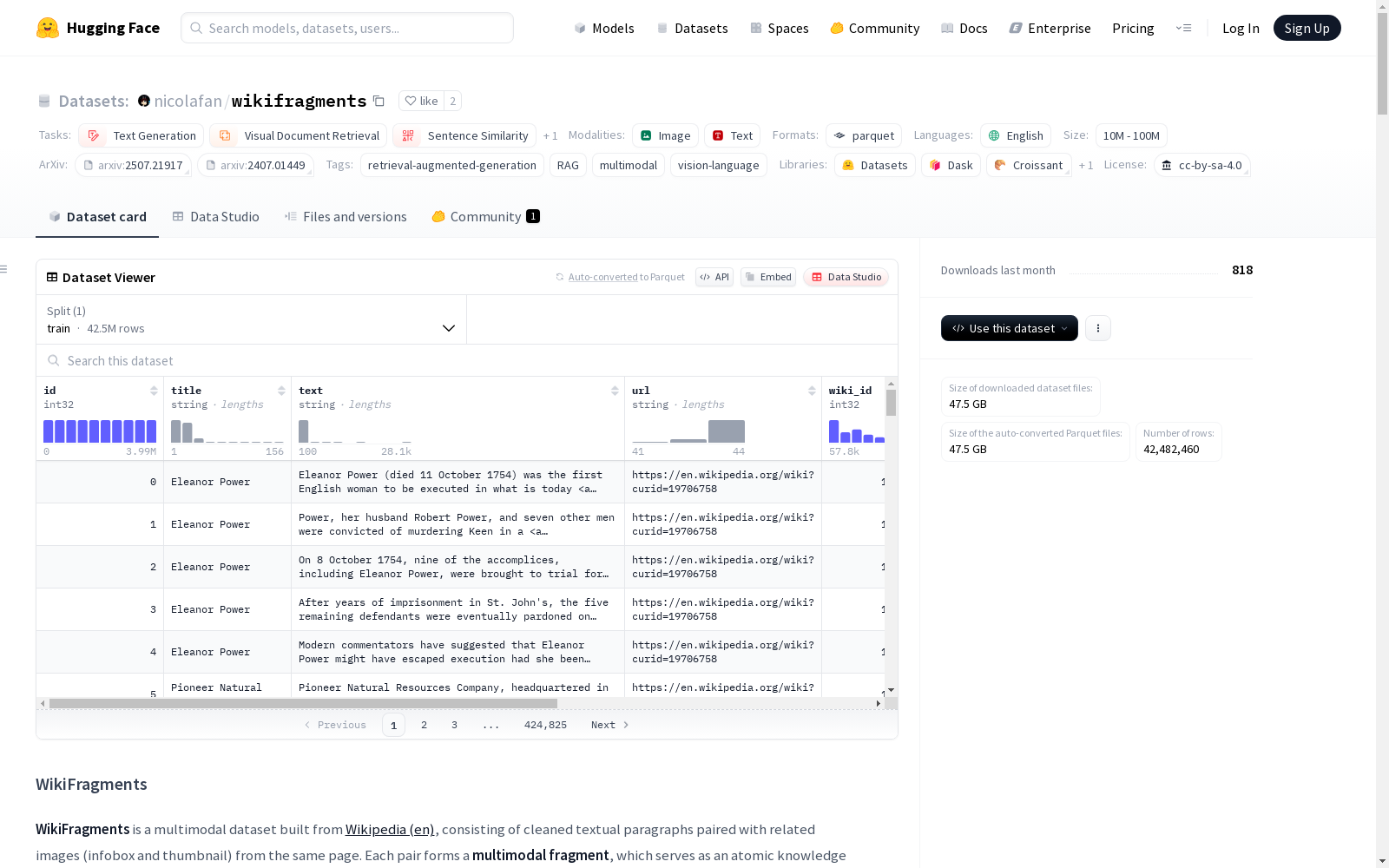
id: 段落唯一标识符 (int32)title: 维基百科页面标题 (string)text: 清理后的段落文本 (string)url: 维基百科页面URL (string)wiki_id: 维基百科页面ID (int32)paragraph_id: 段落在该页面中的序号 (int32)images: 图像序列,包含:caption: 图像标题 (string)image: PIL图像对象 (image)type: 图像类型 ("infobox"或"thumb") (string)url: 图像内部URL (string)
数据划分
- 仅包含训练集(train):
- 样本数: 42,482,460
- 字节数: 58,037,298,060.96
数据集描述
内容
- 从维基百科提取的清理后文本段落
- 每个段落与其相关的图像(来自同一页面的infobox和缩略图)配对
- 每个段落-图像对构成一个多模态片段
统计信息
- 总段落数: 42,482,460
- 包含至少一张图像的段落数: 2,254,123
- 图像总数: 2,499,977
- 每个段落的平均图像数: 1.109
- 单个段落的最大图像数: 125
数据集用途
适用场景
- 多模态检索
- 检索增强生成(RAG)
- 多模态预训练与评估
- 文档理解(如问答系统)
- 多模态上下文学习基准测试
不适用场景
- 需要实时更新的系统
- 法律、医疗或金融等对事实准确性要求高的应用
- 未经许可的商业用途
数据集创建
数据来源
- 文本和图像内容来自英文维基百科和Wikimedia Commons
- 通过Kiwix ZIM dump获取(2024年1月)
处理过程
- 使用修改版的wikiextractor工具提取文本
- 保留超链接和段落顺序
- 从HTML infobox和缩略图引用中解析图像
- 图像与下方段落关联
- 从HTML元数据中提取标题
限制与注意事项
- 继承维基百科的潜在偏见
- 图像许可协议各不相同,需单独遵守
- 仅反映特定时间点的数据快照
- 不适用于安全关键或事实敏感的应用
引用信息
BibTeX:
@article{fanelli2025artseek, title={ArtSeek: Deep artwork understanding via multimodal in-context reasoning and late interaction retrieval}, author={Fanelli, Nicola and Vessio, Gennaro and Castellano, Giovanna}, journal={arXiv preprint arXiv:2507.21917}, year={2025} }
APA: Fanelli, N., Vessio, G., & Castellano, G. (2025). ArtSeek: Deep artwork understanding via multimodal in-context reasoning and late interaction retrieval. arXiv preprint arXiv:2507.21917.
联系方式
- 作者: Nicola Fanelli
- 邮箱: nicola.fanelli@uniba.it
搜集汇总
数据集介绍
构建方式
在知识图谱与多模态学习融合的背景下,WikiFragments数据集通过改进的wikiextractor工具从英文维基百科中系统提取文本段落,保留超链接结构并关联对应的信息框与缩略图图像。图像数据源自Kiwix离线维基百科转储文件,采用低分辨率存储以优化数据集体积,最终形成以段落为单位的图文对齐多模态片段单元。
特点
该数据集的核心特征在于其原子化的多模态知识单元结构,每个片段包含清洁文本、关联图像及其元数据(标题、类型、原始URL),支持图像类型标注与段落级语义对齐。数据规模涵盖4248万段落,其中225万段落配有图像,呈现长尾分布特性,为多模态检索与生成任务提供高覆盖度的百科全书式知识基底。
使用方法
研究者可通过HuggingFace数据集库直接加载该数据,利用内置的文本-图像对开展多模态检索增强生成(RAG)、视觉问答及文档理解等实验。配套提供的FragmentCreator工具可将原始数据转换为视觉化片段表示,结合ColPali等多向量编码模型实现跨模态查询与表示学习,需注意遵循CC BY-SA 4.0协议并校验图像版权约束。
背景与挑战
背景概述
WikiFragments数据集由意大利巴里大学Nicola Fanelli等人于2025年构建,旨在为多模态检索与生成研究提供高质量的百科全书式知识单元。该数据集基于英文维基百科的文本段落与关联图像构建,每个多模态片段包含经过清洗的文本段落及其对应的信息框图像或缩略图,形成原子化的知识单元。作为检索增强生成(RAG)和多模态理解研究的基础资源,该数据集通过结构化整合维基百科的图文信息,推动了多模态表示学习与跨模态检索技术的发展。
当前挑战
该数据集核心挑战在于解决多模态信息检索中图文对齐与语义一致性问题,需克服维基百科原始数据中图像分布稀疏性、段落-图像关联噪声以及异构许可证兼容性等构建难点。具体而言,构建过程中需处理HTML源码解析的复杂性,确保图像与段落的精确空间对应关系,同时需协调数百万张图像的不同版权许可要求。此外,数据集继承了维基百科固有的地域覆盖偏差和编辑偏好,要求使用者具备偏差识别与跨模态表示对齐的能力。
常用场景
经典使用场景
在跨模态信息检索研究领域,WikiFragments数据集通过构建文本段落与对应图像的原子化知识单元,为多模态检索增强生成系统提供了标准化的评估基准。研究者可借助该数据集训练视觉-语言联合表征模型,探索图文关联性计算与跨模态语义对齐机制,尤其适用于处理百科全书式知识密集型任务。
实际应用
基于WikiFragments构建的多模态检索系统可应用于智能问答平台,通过匹配用户查询与百科全书片段提供图文并茂的答案。在数字人文领域,该数据集支持艺术作品检索与文化知识可视化,博物馆智能导览系统可利用其实现展品信息的跨模态关联查询。
衍生相关工作
该数据集催生了ArtSeek多模态推理框架,其提出的片段可视化编码技术被扩展应用于ColPali模型。后续研究基于此发展了多向量跨模态表示方法,在无需额外训练的前提下实现了图文联合查询,为多模态检索架构设计提供了重要范式参考。
以上内容由遇见数据集搜集并总结生成


