Amazon Reviews
收藏kaggle2020-05-30 更新2024-03-08 收录
下载链接:
https://www.kaggle.com/datasets/imkrkannan/kannan
下载链接
链接失效反馈官方服务:
资源简介:
Reviews of products of the amazon company
亚马逊公司(Amazon)的产品评论
创建时间:
2020-05-30
搜集汇总
数据集介绍
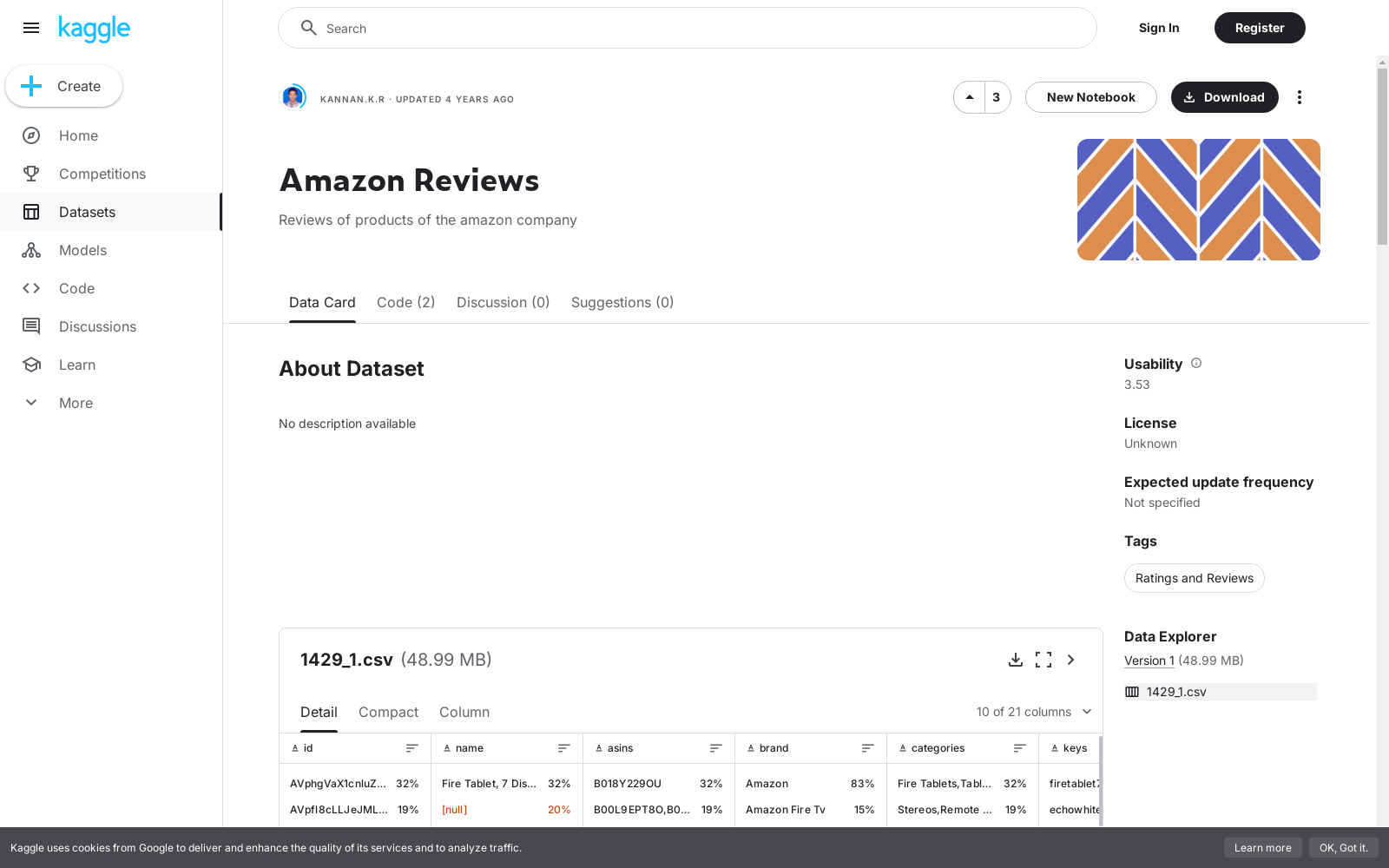
构建方式
Amazon Reviews数据集的构建基于亚马逊平台上数百万用户的商品评论。该数据集通过爬虫技术从亚马逊网站上收集,涵盖了从书籍到电子产品等多个类别的商品评论。数据收集过程中,确保了评论的完整性和真实性,同时对评论文本进行了预处理,包括去除HTML标签、标点符号和停用词,以提高数据质量。
特点
Amazon Reviews数据集以其庞大的规模和多样性著称,包含了超过3000万条评论,涵盖了数十个商品类别。每条评论不仅包含文本内容,还附有评分、评论时间等元数据,为研究者提供了丰富的分析维度。此外,该数据集的评论文本具有较高的自然性和真实性,适用于情感分析、推荐系统等多种应用场景。
使用方法
Amazon Reviews数据集可用于多种自然语言处理任务,如情感分析、主题建模和产品推荐。研究者可以通过分析评论文本中的情感倾向,评估用户对产品的满意度;通过主题建模,挖掘用户关注的重点;通过构建推荐系统,提升用户体验。使用该数据集时,建议先进行数据清洗和预处理,以确保模型的准确性和稳定性。
背景与挑战
背景概述
Amazon Reviews数据集,由亚马逊公司于2013年发布,主要研究人员包括J. McAuley和J. Leskovec,该数据集的核心研究问题集中在用户评论的情感分析和产品推荐系统上。该数据集包含了数百万条用户对亚马逊平台上商品的评论,涵盖了从电子产品到图书等多个类别。其发布极大地推动了自然语言处理和推荐系统领域的发展,为研究人员提供了丰富的语料库,促进了情感分析、文本挖掘和个性化推荐算法的研究与应用。
当前挑战
Amazon Reviews数据集在解决情感分析和产品推荐领域的挑战中,面临着多方面的困难。首先,评论文本的多样性和复杂性使得情感分类任务变得异常复杂,需要高效的文本预处理和特征提取技术。其次,用户评论中存在大量的噪声数据,如拼写错误和非标准语言表达,增加了数据清洗的难度。此外,构建个性化推荐系统时,如何有效利用用户的历史行为和评论信息,以提高推荐的准确性和用户满意度,也是一个亟待解决的问题。
发展历史
创建时间与更新
Amazon Reviews数据集首次发布于2013年,由Julian McAuley和Jure Leskovec在斯坦福大学创建。该数据集定期更新,以反映亚马逊平台上最新的用户评论和产品信息。
重要里程碑
Amazon Reviews数据集的一个重要里程碑是其在2015年发布的扩展版本,包含了超过1.42亿条评论,涵盖了从1995年到2015年的数据。这一扩展版本极大地丰富了研究者对消费者行为和市场趋势的理解。此外,2018年,该数据集进一步整合了多语言评论,为跨文化研究提供了宝贵的资源。
当前发展情况
当前,Amazon Reviews数据集已成为自然语言处理和推荐系统研究中的重要资源。其庞大的数据量和多样化的内容为算法开发和模型训练提供了丰富的素材。研究者们利用该数据集进行情感分析、产品推荐、用户行为预测等多方面的研究,推动了相关领域的技术进步。此外,随着数据隐私和伦理问题的日益受到关注,Amazon Reviews数据集的使用也在不断调整,以确保符合最新的法规和伦理标准。
发展历程
- Amazon首次推出在线评论功能,允许用户对购买的商品进行评价。
- Amazon开始公开其评论数据集,供学术界和研究机构使用,以促进自然语言处理和机器学习领域的研究。
- Amazon Reviews数据集首次被用于大规模情感分析研究,标志着其在自然语言处理领域的重要应用。
- Amazon Reviews数据集被广泛应用于推荐系统研究,特别是在个性化推荐算法中,显著提升了推荐效果。
- Amazon Reviews数据集成为多个国际数据挖掘竞赛的标准数据集,进一步推动了其在学术界和工业界的应用。
- Amazon Reviews数据集被用于研究深度学习模型在文本分类和情感分析中的表现,取得了显著的成果。
常用场景
经典使用场景
在自然语言处理领域,Amazon Reviews数据集被广泛用于情感分析任务。该数据集包含了大量用户对亚马逊商品的评论,涵盖了从电子产品到日常用品的多个类别。通过分析这些评论,研究者可以提取出用户对商品的情感倾向,从而为商品推荐、市场分析和用户行为预测提供有力支持。
解决学术问题
Amazon Reviews数据集在学术研究中解决了情感分析领域的多个关键问题。首先,它为研究者提供了一个大规模、多样化的文本数据源,使得情感分类模型的训练和验证成为可能。其次,该数据集的丰富性有助于探索不同商品类别和用户群体的情感表达差异,推动了情感分析技术的精细化发展。此外,通过对评论数据的深入挖掘,研究者还能揭示消费者行为背后的心理和社会因素,为市场营销策略提供科学依据。
衍生相关工作
基于Amazon Reviews数据集,研究者们开展了一系列相关工作。例如,有研究利用该数据集开发了多语言情感分析模型,提升了跨文化市场的情感识别能力。此外,还有工作通过分析评论中的上下文信息,构建了更加精细化的情感分类体系。在推荐系统领域,研究者们利用评论数据进行协同过滤和内容推荐算法的改进,显著提升了推荐效果。这些衍生工作不仅丰富了情感分析的理论框架,也为实际应用提供了更多创新解决方案。
以上内容由遇见数据集搜集并总结生成


