SmolLM, SmolLM2
收藏arXiv2025-10-31 更新2025-11-04 收录
下载链接:
https://huggingface.co/datasets/stai-tuebingen/faiss-smollm
下载链接
链接失效反馈官方服务:
资源简介:
SmolLM和SmolLM2是两个具有开放预训练语料库的大型语言模型。这些数据集被用于评估模型输出与预训练语料库之间的关系,特别是评估输出是否新颖,即是否无法追溯到记忆的训练数据。通过使用轻量级的GIST嵌入和ColBERTv2重新排序,研究者能够有效地在大规模预训练语料库上进行新颖性分析。该研究揭示了模型在更长序列上使用预训练数据,不同领域对新颖性的影响,以及指令调整对新颖性和风格的影响。
SmolLM and SmolLM2 are two large language models (LLMs) equipped with open pre-training corpora. Relevant datasets are utilized to evaluate the relationship between model outputs and their pre-training corpora, particularly to determine whether the model outputs are novel—meaning they cannot be traced back to memorized training data. By employing lightweight GIST embeddings and ColBERTv2 reranking, researchers can efficiently conduct novelty analysis on large-scale pre-training corpora. This study reveals the model's usage of pre-training data for longer sequences, the influence of different domains on novelty, as well as the impacts of instruction tuning on both novelty and output style.
提供机构:
蒂宾根大学
创建时间:
2025-10-31
原始信息汇总
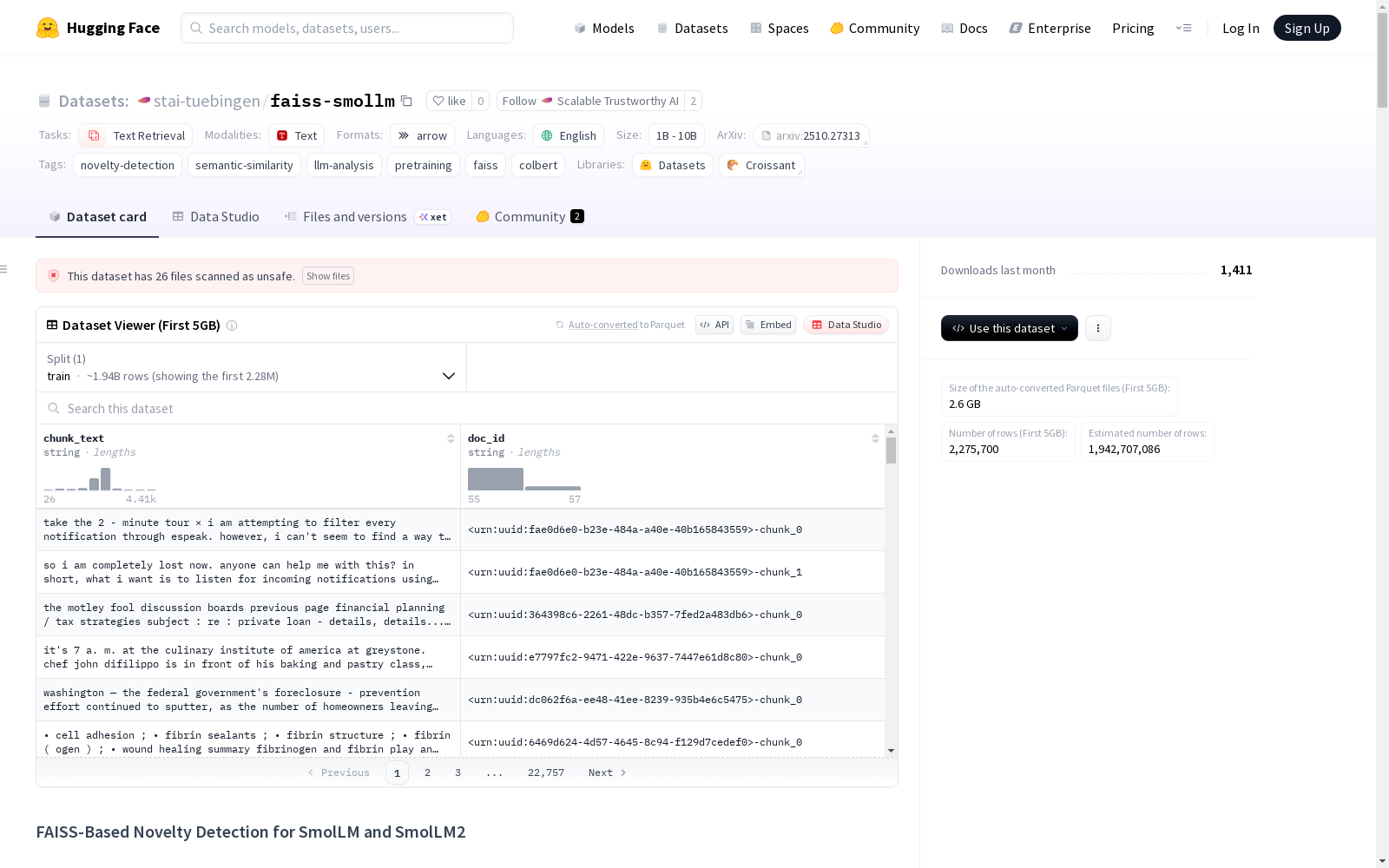
FAISS-Based Novelty Detection for SmolLM and SmolLM2 数据集概述
数据集基本信息
- 任务类别: 文本检索
- 语言: 英语
- 标签: 新颖性检测、语义相似性、LLM分析、预训练、FAISS、ColBERT
核心功能
基于论文《Un-Attributability: Computing Novelty From Retrieval & Semantic Similarity》的方法,测量文本查询相对于SmolLM和SmolLM2预训练语料库的新颖性,支持可选的ColBERTv2重排序以提高精度。
技术流程
- 生成嵌入 - 使用句子转换器编码查询
- FAISS搜索 - 从预训练语料库检索前K个最相似文档
- 合并结果 - 合并多个FAISS索引部分的结果
- ColBERT重排序 - 可选步骤,使用ColBERTv2重排序检索文档
数据分布
由于Hugging Face存储配额限制,完整的FAISS索引和分块数据集分布在两个存储库中:
- https://huggingface.co/datasets/stai-tuebingen/faiss-smollm
- https://huggingface.co/datasets/enguyen/smollm-chunked
系统要求
- Python版本: 3.11(必需)
- 硬件: 支持CUDA的GPU(推荐)
- 依赖: 预构建的FAISS索引和分块数据集
目录结构
FAISS索引结构
FAISS_PATH_1/ ├── dclm/ │ ├── faiss_part_0.index │ ├── faiss_part_1.index ├── stack_edu/ │ ├── faiss_part_0.index
数据结构
DATA_PATH/ ├── fineweb_edu_chunked/ │ ├── part_0/ │ ├── part_1/ ├── cosmopediav2_chunked/ │ ├── part_0/ │ ├── part_1/
主要脚本
minimal_example_embeddings.py- 生成查询嵌入minimal_example_FAISS.py- FAISS索引搜索minimal_example_combine_FAISS.py- 合并FAISS结果minimal_example_ColBERTv2.py- ColBERT重排序
实验配置
支持单实验和多实验配置:
- 单实验:
[("SmolLM-360M", "prompted")] - 多实验:
[("SmolLM-360M", "prompted"), ("SmolLM-360M", "unprompted")]
输出文件
- 嵌入文件:
{model_name}_{prompted_or_not}_embeddings.npy - 相似度分数:
{model_name}_{prompted_or_not}_S.npy - 索引字符串:
{model_name}_{prompted_or_not}_I.npy - ColBERT结果:
{EXPERIMENT_NAME}_{model_name}_chunk_size_{CHUNK_SIZE}_simple_rerank_results_model.json
搜集汇总
数据集介绍
构建方式
在语言模型训练数据溯源研究领域,该数据集通过创新的两阶段检索流程构建。首先利用轻量级GIST嵌入对预训练语料库建立索引,检索前n个候选文本;随后采用ColBERTv2进行精细重排序,通过计算生成文本与语料库最佳匹配项的语义相似度,构建出基于不可归因性的语义新颖性评估体系。这种构建方式突破了传统词汇匹配的局限,实现了对大规模预训练语料的高效语义分析。
特点
该数据集展现出三个显著特征:模型依赖预训练数据的跨度远超以往报告范围,揭示了长序列语义关联的新模式;不同任务领域呈现系统性的新颖性差异,数学推理与开放改写任务保持接近人类基准水平,而事实推理任务则表现出更高的语义创新性;指令微调不仅改变输出风格,更实质性地提升了模型组合生成能力,使输出在语义空间中的分布更加多样化。这些特征为理解语言模型的泛化行为提供了新的观测维度。
使用方法
研究使用时将模型输出与人类撰写的基准文本进行对比分析,通过计算ColBERTv2相似度比值来量化新颖性。具体操作中,对生成文本和预训练语料进行多尺度分块处理,比较不同长度序列的语义相似性模式。该方法支持开放域和特定领域的双重评估场景,既能分析通用生成行为,又能深入探究不同任务领域的新颖性特征,为大规模语言模型的泛化能力研究提供了可扩展的分析框架。
背景与挑战
背景概述
SmolLM与SmolLM2系列数据集由Tübingen AI Center团队于2024至2025年间构建,聚焦于语言模型训练数据归因与语义新颖性评估的前沿研究。该数据集通过公开预训练语料库,系统探索模型输出与训练数据间的语义关联性,核心研究问题在于量化语言模型生成内容的不可归因性,即判定模型是否产生超越训练数据语义范围的新颖输出。其创新性在于将传统归因问题转化为不可归因性度量,为理解语言模型的组合泛化能力提供了可扩展的分析框架,对自然语言处理领域的模型可解释性研究具有重要推动作用。
当前挑战
该数据集需解决语言模型输出语义新颖性判定的核心挑战:传统词汇匹配方法难以识别语义相似但表述迥异的文本,而基于嵌入的相似性度量需平衡计算效率与语义精度。构建过程中面临大规模预训练语料索引的工程挑战,需设计轻量级GIST嵌入与ColBERTv2重排序的两阶段流水线以处理万亿级令牌数据。同时,数据归因的评估需建立可靠的人类写作基线,并解决指令调优引发的风格偏移对新颖性度量的干扰,这些因素共同构成了该数据集在方法论与实施层面的复合型挑战。
常用场景
经典使用场景
在语言模型行为研究领域,SmolLM和SmolLM2数据集为训练数据归因分析提供了重要实验平台。研究者通过构建基于GIST嵌入和ColBERTv2重排序的两阶段检索流程,系统评估模型输出与预训练语料库的语义关联性。这种分析范式能够有效识别模型生成文本中不可归因的语义新颖性,为理解语言模型的组合泛化能力提供量化依据。
实际应用
在实际应用层面,基于SmolLM系列数据集的不可归因性测试可服务于多个重要场景。在模型审计领域,该技术能有效识别模型输出是否涉及训练数据的语义复制,为知识产权保护提供技术支撑。在安全评估方面,该方法可检测模型在特定领域(如医疗、法律)的生成内容是否超越训练数据范围,评估其实际应用风险。此外,该框架还可用于优化指令微调策略,通过量化分析不同微调方法对输出新颖性的影响,指导模型开发过程。
衍生相关工作
该数据集催生了多个重要的衍生研究方向。在方法学层面,研究者基于其两阶段检索框架开发了更高效的语义相似性计算方案,如改进的嵌入索引技术和动态分块策略。在理论探索方面,相关工作深入分析了模型规模与输出新颖性的关联规律,揭示了指令微调对语义组合能力的促进作用。此外,该数据集还推动了领域特异性新颖性评估标准的发展,促使研究者建立针对数学推理、事实问答等不同任务场景的专门化评估体系。
以上内容由遇见数据集搜集并总结生成


