cs419-data
收藏Hugging Face2026-05-12 更新2026-05-14 收录
下载链接:
https://huggingface.co/datasets/quynong/cs419-data
下载链接
链接失效反馈官方服务:
资源简介:
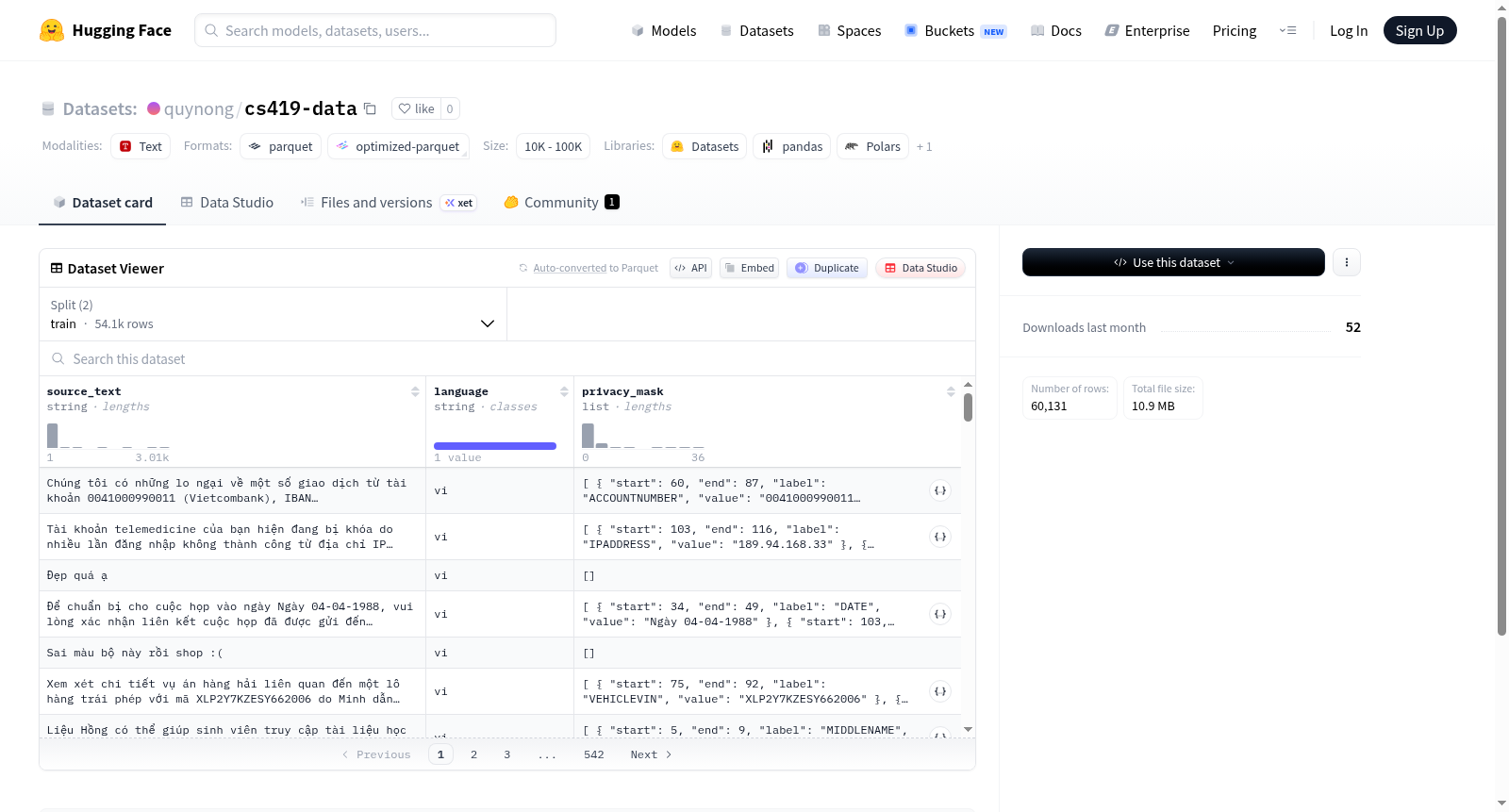
该数据集是一个用于隐私敏感信息标注的文本数据集,包含训练集(54,117个样本)和验证集(6,014个样本),总数据量约15.6MB。每个数据样本由原始文本(source_text)、语言标识(language)和隐私掩码标注(privacy_mask)组成,其中privacy_mask标注了文本中隐私敏感信息的起始位置、结束位置、标签和原始值,适用于自然语言处理任务中的隐私保护或信息抽取研究。
This dataset is a text dataset for privacy-sensitive information annotation, containing a training set (54,117 samples) and a validation set (6,014 samples), with a total data size of approximately 15.6MB. Each data sample consists of original text (source_text), language identification (language), and privacy mask annotations (privacy_mask), where privacy_mask annotates the start position, end position, label, and original value of privacy-sensitive information in the text, suitable for privacy protection or information extraction research in natural language processing tasks.
创建时间:
2026-05-10
搜集汇总
数据集介绍
构建方式
cs419-data数据集聚焦于自然语言处理中的隐私保护任务,其构建基于对原始文本数据中敏感信息的精确标注。具体而言,数据集以源文本字段为核心,通过定义隐私遮罩层(privacy_mask),对每个文本片段中的敏感内容进行起始位置、终止位置、标签类别与实际取值的人工或半自动化标注,从而形成结构化的隐私标记样本。数据划分上,训练集包含54,117条样本,验证集包含6,014条样本,两者均以二进制格式存储于专用路径下,确保了数据加载的便捷性与处理流程的标准化。
特点
该数据集最显著的特点在于其专门面向隐私信息识别与脱敏需求而设计,尤其强调对文本中各类敏感实体的细粒度定位与分类。每条样本均携带source_text字段与多层嵌套的隐私遮罩结构,其中label字段可涵盖姓名、身份证号、地址等敏感类别,而value字段则保留原始敏感词,为模型训练提供了完整的上下文对比信息。此外,数据集规模适中,验证集占比约10%,兼顾了模型训练的效率与泛化评估的可靠性。
使用方法
使用cs419-data数据集进行模型训练时,研究者可直接利用Hugging Face Datasets库加载default配置,通过指定data/train-*与data/validation-*路径分别获取训练与验证分片。典型应用场景包括训练序列标注模型以实现端到端的隐私实体识别,或构建基于遮罩标签的文本脱敏生成系统。推荐使用tokenizer对source_text进行编码,并利用privacy_mask中的起始与结束位置对齐令牌索引后构造损失函数,从而优化模型在敏感边界预测上的精度。
背景与挑战
背景概述
cs419-data数据集由俄勒冈州立大学的研究团队构建,旨在推动多语言自然语言处理中的隐私保护研究。该数据集创建于近年,聚焦于从非结构化文本中自动识别和脱敏个人身份信息(PII),如姓名、地址等敏感实体。其核心研究问题在于如何在保护隐私的前提下,依然保持下游NLP任务的性能。该数据集通过提供细粒度的隐私掩码标注,为模型训练与评估提供了标准化基准,对提升NLP系统的伦理安全性和用户信任度具有重要影响力。
当前挑战
该数据集主要应对的领域挑战是自动识别文本中的隐私敏感信息并实现有效脱敏,当前主流模型在跨语言泛化、非规范表达(如缩写、错误拼写)的PII识别上仍面临高误报与漏报风险。构建过程中,团队需在人工标注时平衡隐私保护等级与上下文完整性,同时处理大量长尾实体和嵌套隐私标签,导致标注一致性维护与数据规模扩展困难。
常用场景
经典使用场景
在自然语言处理与隐私保护交叉领域中,cs419-data数据集以其独特的结构为隐私信息检测任务提供了标准化基准。该数据集包含原始文本、语言标注以及精细的隐私掩码信息——通过起始位置、结束位置、标签类别和具体值来定位文本中的敏感内容,适用于训练和评估能够自动识别并标注个人身份信息(如姓名、地址、电话号码等)的序列标注模型。经典使用场景聚焦于构建监督学习框架下的隐私实体识别系统,例如基于BiLSTM-CRF或Transformer架构的命名实体识别(NER)模型,在给定源文本中精准预测隐私实体的边界与类别,从而推动隐私保护技术的量化评估与可重复研究。
实际应用
在实际应用中,cs419-data数据集赋能了多种隐私合规自动化工具的开发。基于该数据集训练的模型可直接集成到社交平台内容审核系统,自动检测用户发帖中无意泄露的手机号、身份证号等敏感信息并予以提醒或遮蔽;也可应用于医疗记录脱敏流程,在共享临床数据前自动识别并替换患者标识符,确保符合HIPAA等隐私法规要求。此外,它还支撑了企业数据管理平台中的智能敏感数据发现模块,帮助组织在内部文档流转时实时定位隐私风险点,显著降低人工审核成本并提升数据安全治理效率。
衍生相关工作
基于cs419-data数据集,研究者已衍生出多项具有代表性的学术工作。例如,有工作提出了结合数据增强与对比学习的隐私实体识别框架,利用数据集中的掩码位置重新合成多样化训练样本以提升小样本场景下的鲁棒性;另有研究将其作为核心评估基准,对比不同预训练语言模型(如BERT、RoBERTa、XLM-R)在跨语言隐私检测任务上的迁移能力。此外,部分工作还探索了将隐私掩码标签转化为结构化推理提示,通过大型语言模型进行少样本或零样本的隐私识别,推动了传统序列标注范式向指令微调范式的演进。
以上内容由遇见数据集搜集并总结生成


