ideogram-25k
收藏Hugging Face2024-07-11 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/terminusresearch/ideogram-25k
下载链接
链接失效反馈官方服务:
资源简介:
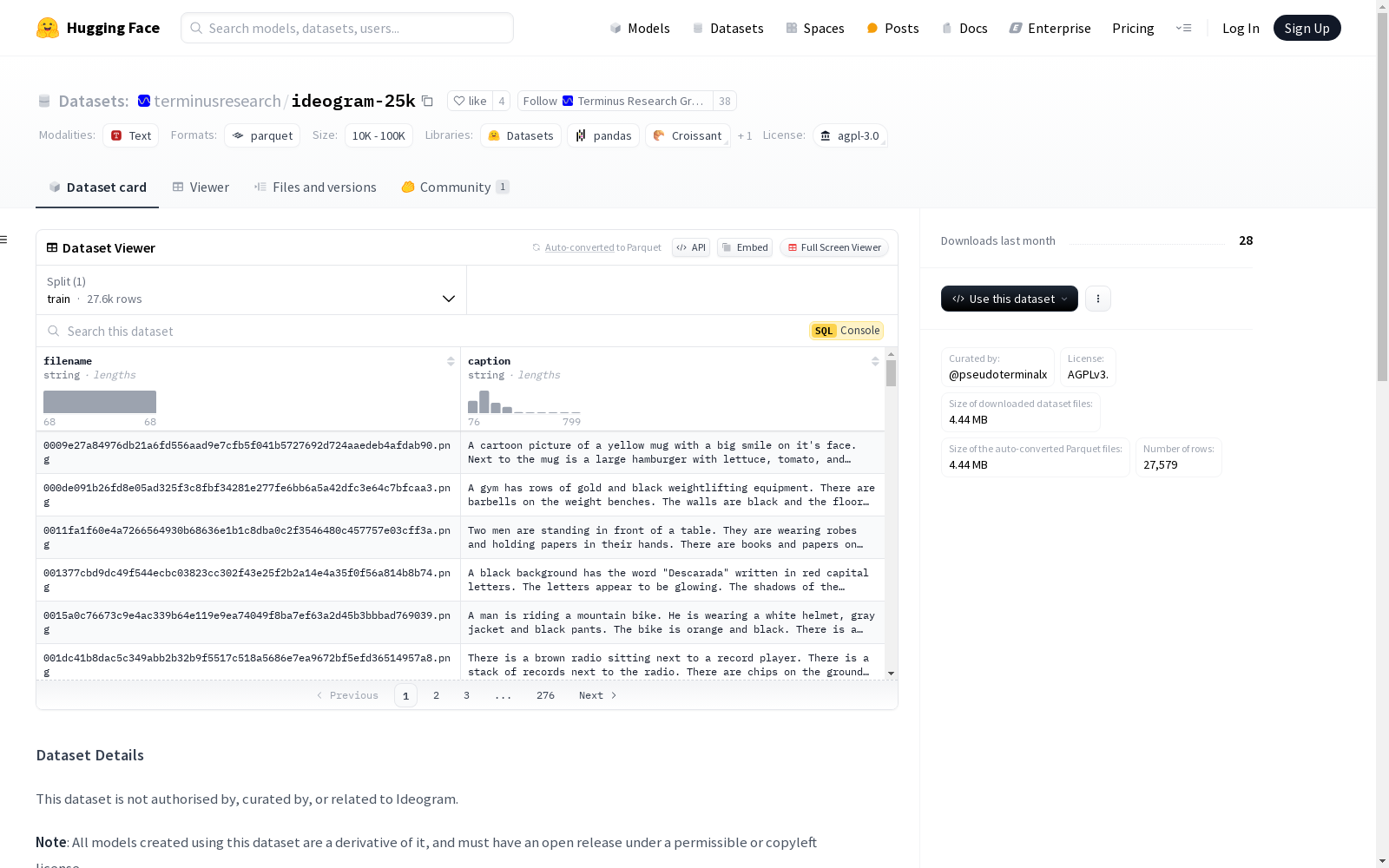
该数据集包含约27,000张从Ideogram获取的图像,这是一个专注于排版生成的专有图像生成服务。数据集主要用于微调或训练文本到图像的模型和分类器,以及分析Ideogram用户的偏见。数据集的文件名是图像数据的SHA256哈希值,用于验证完整性。图像的描述是通过Microsoft Florence2模型生成的。数据集的创建使用了自定义的Selenium应用程序,该程序监控Ideogram服务并即时保存帖子到磁盘。数据集的偏见主要来自单一的合成源,即Llava 34B描述器。
This dataset contains approximately 27,000 images sourced from Ideogram, a proprietary image generation service specializing in typography generation. The dataset is primarily intended for fine-tuning or training text-to-image models and classifiers, as well as analyzing biases among Ideogram users. The filenames of the dataset are the SHA256 hash values of the image data, which are used for integrity verification. Image descriptions were generated using the Microsoft Florence2 model. The dataset was constructed using a custom Selenium application that monitors the Ideogram service and saves posts to disk in real time. Biases within the dataset primarily originate from a single synthetic source: the Llava 34B descriptor.
创建时间:
2024-07-10
搜集汇总
数据集介绍
构建方式
ideogram-25k数据集的构建过程主要依赖于自动化工具和算法。通过使用Python编写的自定义Selenium应用程序,该工具能够实时监控Ideogram服务中的图像发布,并将这些图像迅速保存至本地磁盘。为了确保数据的唯一性,所有图像均通过SHA256哈希算法进行去重处理。此外,图像描述部分则通过Microsoft Florence2模型生成,该模型能够准确描述图像内容,从而为每张图像提供详细的文本描述。
特点
ideogram-25k数据集以其专注于高质量排版图像的特点而著称。数据集中的图像均来源于Ideogram,这是一个以排版生成为核心的专有图像生成服务。由于Ideogram用户主要关注排版设计,因此该数据集包含了大量与排版相关的高质量图像。此外,数据集中的图像描述由Microsoft Florence2模型生成,确保了描述的准确性和一致性。然而,由于描述来源单一,数据集可能受到Llava 34B模型偏见的潜在影响。
使用方法
ideogram-25k数据集适用于多种机器学习任务,尤其是文本到图像模型的微调和训练。研究人员可以利用该数据集对Ideogram用户偏好进行分析,或用于开发与排版相关的图像分类器。在使用该数据集时,用户需注意其图像文件名采用SHA256哈希值命名,可用于验证数据的完整性。此外,基于该数据集开发的模型或衍生作品需遵循AGPLv3许可协议,并注明数据来源及Terminus Research的引用。
背景与挑战
背景概述
ideogram-25k数据集由@pseudoterminalx于近期创建,旨在为文本到图像生成模型和分类器的微调提供高质量的数据支持。该数据集从Ideogram这一专注于字体设计的专有图像生成服务中提取了约27,000张图像,并通过Microsoft Florence2模型生成图像描述。由于Ideogram用户主要关注字体生成,该数据集在字体设计领域具有较高的应用价值。其数据来源为合成数据,避免了版权问题,适合用于开放许可的模型训练。该数据集的创建为字体生成和图像描述研究提供了新的资源,推动了相关领域的技术发展。
当前挑战
ideogram-25k数据集在构建和应用过程中面临多重挑战。首先,数据集的图像描述完全依赖于单一合成来源(Llava 34B模型),这可能导致描述中的偏见问题,限制了数据集的多样性和泛化能力。其次,尽管数据集通过SHA256哈希值进行去重处理,但数据采集过程中仍可能存在重复或低质量样本,影响模型的训练效果。此外,由于数据集来源于专有服务,其数据分布可能受到用户偏好的影响,进一步加剧了数据偏差问题。未来需要通过引入更多来源的描述数据和多模态验证方法来提升数据集的可靠性和实用性。
常用场景
经典使用场景
在文本到图像生成领域,ideogram-25k数据集因其专注于高质量的字体设计图像而备受关注。该数据集常用于微调或训练文本到图像生成模型,特别是在需要生成具有艺术字体效果的图像时。通过该数据集,研究人员能够探索字体与图像结合的创新方式,推动视觉艺术与技术的融合。
衍生相关工作
基于ideogram-25k数据集,许多经典工作得以衍生。例如,研究人员利用该数据集开发了新型的文本到图像生成模型,这些模型在字体生成方面表现出色。此外,该数据集还启发了对生成模型偏见的研究,推动了更公平、更透明的AI生成技术的发展。
数据集最近研究
最新研究方向
在文本到图像生成领域,ideogram-25k数据集因其专注于高质量的排版图像而备受关注。该数据集通过从Ideogram服务中提取的27,000张图像,为研究人员提供了丰富的排版数据资源。近年来,随着生成模型技术的快速发展,ideogram-25k数据集被广泛应用于微调和训练文本到图像生成模型,尤其是在排版生成方面表现出色。此外,该数据集还被用于分析Ideogram用户的行为偏差,为理解用户偏好和生成模型的潜在偏差提供了重要依据。尽管数据集中的描述信息目前依赖于单一的合成来源,存在一定的偏差,但其无版权问题的特性使其成为研究中的宝贵资源。未来,随着更多描述信息的加入,该数据集在生成模型训练和用户行为分析中的应用前景将更加广阔。
以上内容由遇见数据集搜集并总结生成


