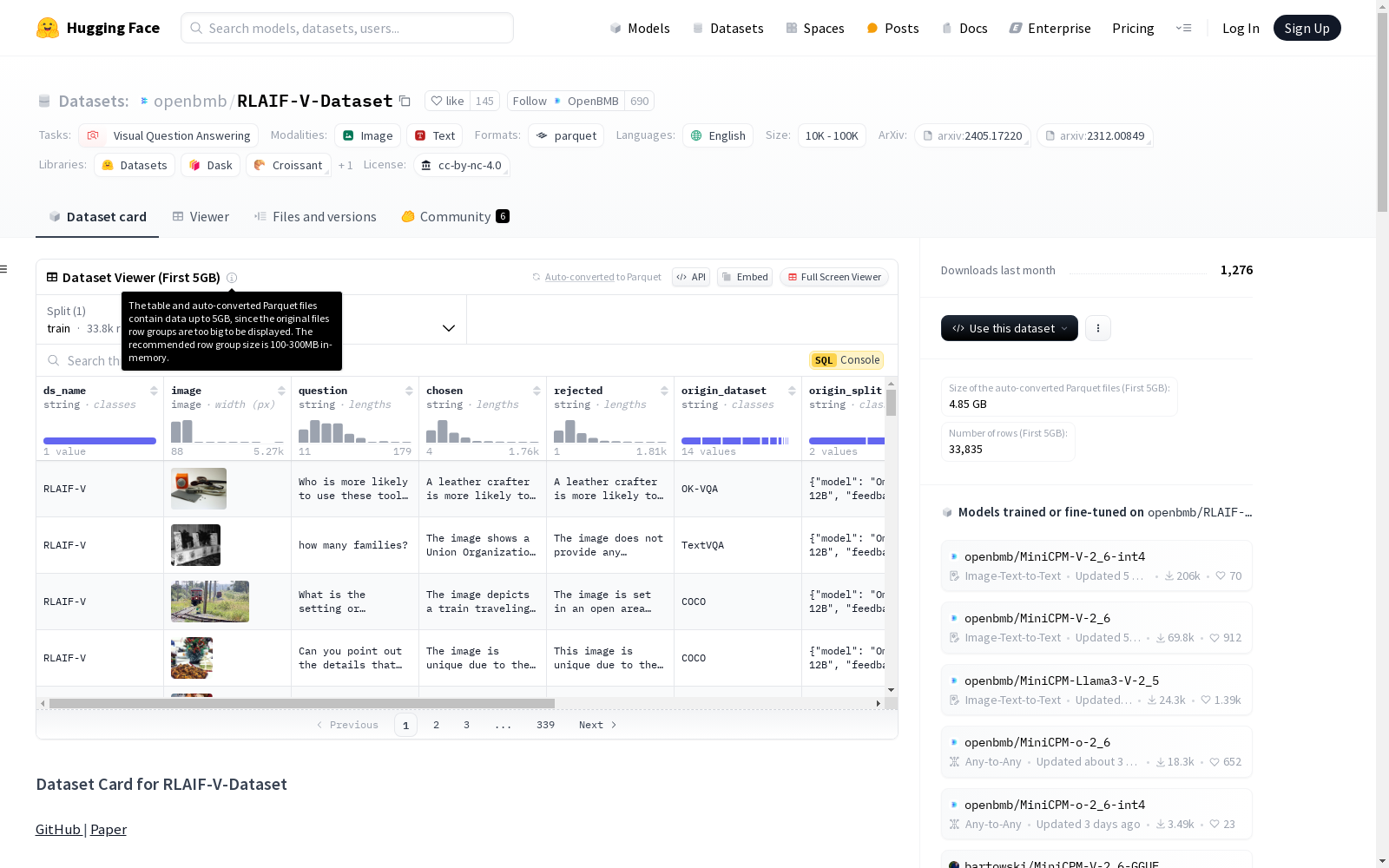
RLAIF-V-Dataset - 大规模多模态偏好数据集
收藏数据集概述:RLAIF-V-Dataset
基本信息
- 许可证:CC-BY-NC-4.0
- 任务类别:视觉问答(Visual Question Answering)
- 语言:英语(en)
- 数据集名称:RLAIF-V-Dataset
- 数据规模:10K < n < 100K
数据集特点
- 数据字段:
ds_name:数据集名称image:包含路径和字节的字典,可自动转换为PIL图像question:输入查询(针对多模态大语言模型)chosen:针对问题的优选回答rejected:针对问题的拒绝回答origin_dataset:图像或问题的原始数据集origin_split:元信息(包括生成回答对的模型、标注模型、问题类型等)idx:数据索引image_path:图像路径
数据集摘要
- 规模:包含83,132个偏好对
- 数据来源:多样化的数据集(MSCOCO、ShareGPT-4V、MovieNet、Google Landmark v2、VQA v2、OKVQA、TextVQA等)
- 用途:通过训练,模型可达到优于开源和专有模型的信任度
相关资源
- 训练模型:
- MiniCPM-V系列:具有与GPT-4V相当性能的端侧多模态大语言模型
- RLAIF-V:具有远超GPT-4V信任度的多模态大语言模型
使用方式
python from datasets import load_dataset data = load_dataset("openbmb/RLAIF-V-Dataset")
引用
bibtex @article{yu2023rlhf, title={Rlhf-v: Towards trustworthy mllms via behavior alignment from fine-grained correctional human feedback}, author={Yu, Tianyu and Yao, Yuan and Zhang, Haoye and He, Taiwen and Han, Yifeng and Cui, Ganqu and Hu, Jinyi and Liu, Zhiyuan and Zheng, Hai-Tao and Sun, Maosong and others}, journal={arXiv preprint arXiv:2312.00849}, year={2023} }
@article{yu2024rlaifv, title={RLAIF-V: Open-Source AI Feedback Leads to Super GPT-4V Trustworthiness}, author={Tianyu Yu and Haoye Zhang and Qiming Li and Qixin Xu and Yuan Yao and Da Chen and Xiaoman Lu and Ganqu Cui and Yunkai Dang and Taiwen He and Xiaocheng Feng and Jun Song and Bo Zheng and Zhiyuan Liu and Tat-Seng Chua and Maosong Sun}, journal={arXiv preprint arXiv:2405.17220}, year={2024}, }