PSEUDOEVAL
收藏arXiv2025-02-26 更新2025-02-28 收录
下载链接:
https://anonymous.4open.science/r/PseudocodeACL25-7B74/
下载链接
链接失效反馈官方服务:
资源简介:
PSEUDOEVAL是由香港科技大学构建的多语言代码生成基准数据集,包含1060个问题,不仅包括自然语言描述的问题和相应的测试,还包括伪代码形式的中间解决方案。该数据集旨在分离和识别不同编程语言中代码生成的瓶颈,提供了清晰的伪代码构建标准和自动化构建流程的管道。
PSEUDOEVAL is a multilingual code generation benchmark dataset constructed by The Hong Kong University of Science and Technology. It contains 1060 questions, which include not only problems described in natural language and their corresponding test cases, but also intermediate solutions in the form of pseudocode. This dataset aims to isolate and identify the bottlenecks of code generation across different programming languages, and provides clear pseudocode construction standards as well as a pipeline for automated construction workflows.
提供机构:
香港科技大学
创建时间:
2025-02-26
搜集汇总
数据集介绍
构建方式
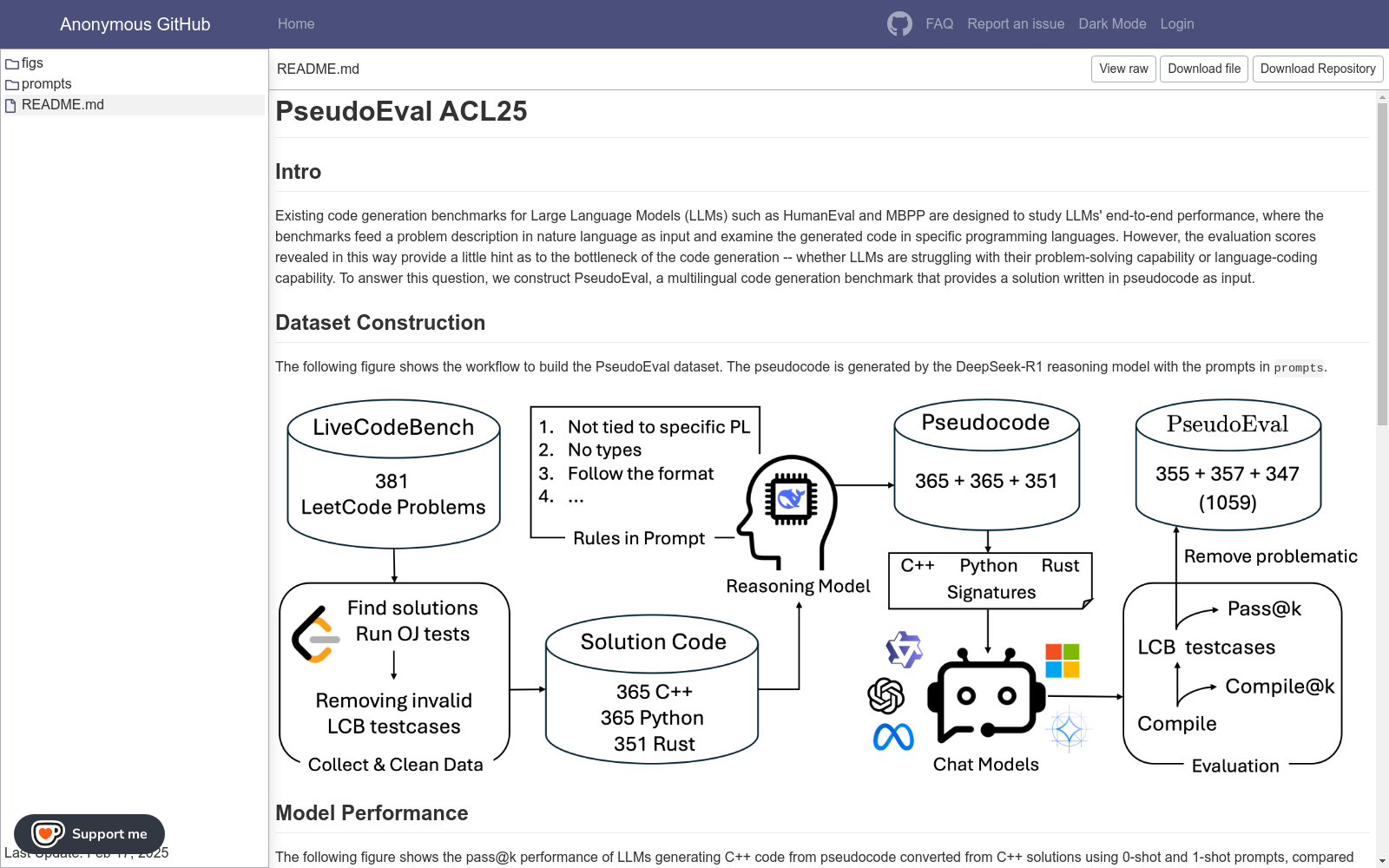
PSEUDOEVAL数据集的构建采用了从LeetCode上收集用户提交的解决方案,并利用DeepSeek-R1推理模型将这些解决方案转换为伪代码。首先,选择了LiveCodeBench中最新的编程问题及其在LeetCode上的用户提交解决方案,并确保这些解决方案通过了LeetCode在线评测。然后,使用DeepSeek-R1模型和一系列规则将这些解决方案转换为符合特定标准的伪代码,这些规则确保伪代码的完整性、语言无关性和简洁性。最后,通过评估LLMs从这些伪代码生成代码的能力来构建数据集。
特点
PSEUDOEVAL数据集的主要特点是它包含多语言代码生成基准,其中每个问题都有对应的自然语言描述、伪代码解决方案和测试用例。此外,数据集还提供了自动化的工作流程,可以轻松地将伪代码解决方案添加到现有的代码生成基准中。PSEUDOEVAL数据集的独特之处在于它将代码生成的瓶颈分解为问题解决和语言编码两个独立的能力,从而可以更准确地评估LLMs在不同编程语言中的表现。
使用方法
使用PSEUDOEVAL数据集的方法包括将自然语言问题描述和伪代码解决方案作为输入,并评估LLMs生成正确代码的能力。数据集的测试用例可以用来验证LLMs生成的代码的正确性。此外,数据集还可以用来研究不同编程语言中LLMs的问题解决和语言编码能力的差异,以及跨编程语言的问题解决能力是否可以迁移。
背景与挑战
背景概述
在大型语言模型(LLMs)在代码生成方面的应用日益普及的背景下,研究者们对LLMs在代码生成过程中的瓶颈问题产生了浓厚的兴趣。现有的代码生成基准测试,如HumanEval和MBPP,主要关注LLMs的端到端性能,即以自然语言描述的问题作为输入,并检查生成的特定编程语言代码的正确性。然而,这种评估方式并没有揭示代码生成的瓶颈所在——LLMs是在问题解决能力上遇到困难,还是在语言编码能力上存在不足。为了回答这个问题,香港科技大学的研究人员构建了PSEUDOEVAL,这是一个多语言代码生成基准测试,它以伪代码形式提供解决方案作为输入。通过这种方式,可以隔离和识别不同编程语言中代码生成的瓶颈。PSEUDOEVAL的研究揭示了几个有趣的发现,例如,LLMs在Python编程中的瓶颈是问题解决能力,而Rust相对更多地受困于语言编码。此外,研究还表明,问题解决能力可能在不同编程语言之间转移,而语言编码则需要更多语言特定的努力,尤其是对于训练不足的编程语言。最后,研究人员发布了构建PSEUDOEVAL的流程,以便于将其扩展到现有的基准测试中。PSEUDOEVAL可在https://anonymous.4open.science/r/PseudocodeACL25-7B74/获取。
当前挑战
PSEUDOEVAL数据集面临的挑战主要涉及以下几个方面:1) 所解决的领域问题是LLMs在代码生成过程中的瓶颈问题,即区分问题解决能力和语言编码能力。2) 构建过程中遇到的挑战包括:如何有效地从解决方案代码中提取高质量、简洁且语义清晰的伪代码,以及如何确保LLMs能够理解和使用这些伪代码来生成正确的代码。此外,还需要进一步研究不同编程语言之间的问题解决能力是否可以转移,以及如何提高LLMs在不同编程语言中的语言编码能力。
常用场景
经典使用场景
PSEUDOEVAL数据集被广泛应用于评估大型语言模型(LLMs)的代码生成能力。通过提供伪代码作为输入,该数据集能够将问题解决能力和语言编码能力分离,从而更准确地评估LLMs在不同编程语言中的瓶颈。例如,研究表明,LLMs在Python编程中的瓶颈在于问题解决能力,而在Rust中则相对更困难的是语言编码能力。
解决学术问题
PSEUDOEVAL数据集解决了LLMs代码生成能力评估中的关键问题。通过将问题解决和语言编码能力分离,该数据集提供了更清晰、更准确的评估标准,有助于研究人员更深入地理解LLMs在不同编程语言中的表现。此外,该数据集还探讨了问题解决能力在不同编程语言之间的可迁移性,以及自动生成的伪代码与人工编写伪代码之间的差异,为LLMs代码生成能力的提升提供了重要参考。
衍生相关工作
PSEUDOEVAL数据集的提出引发了相关领域的一系列研究。例如,有研究探索了伪代码在代码生成中的作用,以及不同编程语言之间的问题解决能力迁移性。此外,还有研究比较了自动生成的伪代码与人工编写伪代码之间的差异,为LLMs代码生成能力的提升提供了重要参考。这些研究进一步推动了LLMs在代码生成领域的应用,并为LLMs的能力提升提供了重要参考。
以上内容由遇见数据集搜集并总结生成


