astro-llms-benchmark-dataset
收藏Hugging Face2025-07-16 更新2025-07-17 收录
下载链接:
https://huggingface.co/datasets/jhu-clsp/astro-llms-benchmark-dataset
下载链接
链接失效反馈官方服务:
资源简介:
这是一个由天文学家在一个研究Slack聊天机器人上提出的问题组成的集合,包含了开放编码标签、专家天文学家的回答以及与答案相关的五篇研究论文。这个数据集被命名为“Gold Benchmark Dataset”。
This is a dataset composed of questions posed by astronomers on a research-focused Slack chatbot. It includes open-coded labels, responses from expert astronomers, and five research papers associated with these responses. This dataset is named the "Gold Benchmark Dataset".
创建时间:
2025-07-16
原始信息汇总
AstroLLMs Gold Benchmark Dataset 概述
数据集简介
- 目的:收集天文学家向天文学研究Slack聊天机器人提出的查询,包含开放编码标签和专家天文学家的回答。
- 特点:专家回答需引用文献且不使用大型语言模型(LLMs),被称为“黄金基准数据集”。
数据集结构
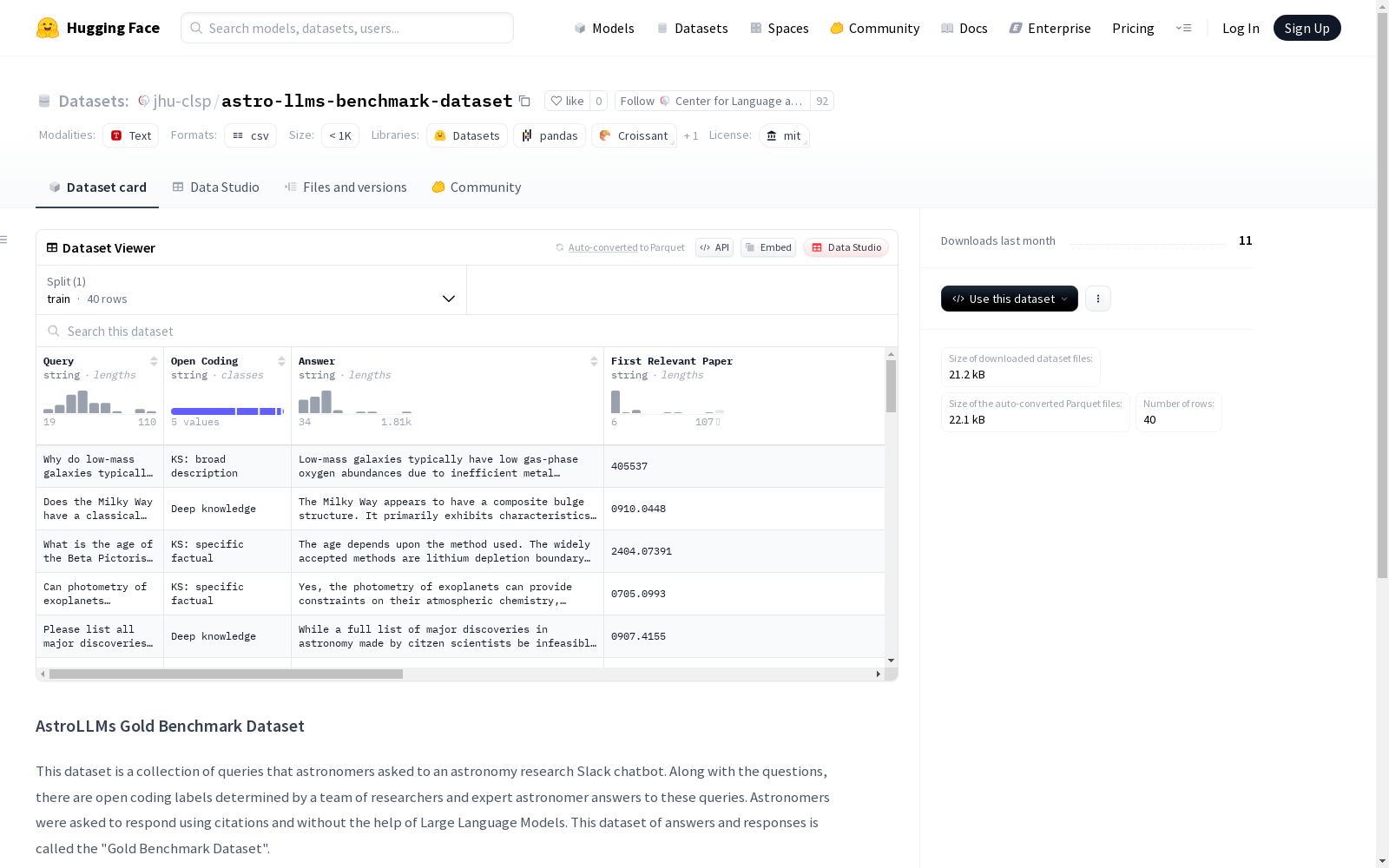
- 包含列:
- Query(查询问题)
- Open Coding(查询类型的开放编码标签)
- Answer(专家天文学家的回答)
- First through Fifth Relevant Paper(与专家回答相关的研究论文)
引用信息
- 引用文献:Hyk, A., McCormick, K., Zhong, M., Ciucă, I., Sharma, S., Wu, J. F., Peek, J. E. G., Iyer, K. G., Xiao, Z., & Field, A. "From Queries to Criteria: Understanding How Astronomers Evaluate LLMs," Conference on Language Modeling, 2025.
搜集汇总
数据集介绍
构建方式
在当代天文学研究快速发展的背景下,AstroLLMs Gold Benchmark Dataset通过系统收集天文学家向Slack聊天机器人提出的专业查询构建而成。研究团队采用开放式编码技术对查询类型进行标注,并邀请天文学专家基于文献引用(禁止使用大语言模型辅助)提供权威解答,同时关联1-5篇相关研究论文,形成具有学术严谨性的基准数据集。
特点
该数据集以天文学领域特有的专业对话为核心,其突出价值体现在三个方面:真实场景下的自然语言查询反映了实际研究需求;专家标注的开放式编码体系提供了可解释的问题分类框架;每项答案均附带权威文献引用链,既确保回答的可验证性,也为后续研究建立了知识溯源路径。这种多维度标注结构为评估天文学大语言模型提供了黄金标准。
使用方法
研究者可将该数据集作为基准工具,通过对比大语言模型输出与专家答案的吻合度来评估模型性能。具体应用中,建议重点关注三个维度:查询意图识别的准确性(通过Open Coding标签验证)、回答内容的学术严谨性(对照专家答案及文献引用)、以及知识推荐的合理性(比对标注的相关论文)。使用时应严格遵守数据集的引用规范,以维护学术伦理。
背景与挑战
背景概述
AstroLLMs Gold Benchmark Dataset诞生于2025年,由Hyk、McCormick等跨学科团队在语言建模会议上首次提出,旨在构建天文学领域专业对话的评估基准。该数据集源自天文学家在Slack研究聊天机器人上的真实提问记录,通过专家团队标注的开放编码标签和人工撰写的权威答案,形成了包含查询类型、专家解答及相关文献引用的多维结构。作为天文学与自然语言处理交叉研究的里程碑,它不仅填补了领域特定知识评估工具的空白,更为大型语言模型在天文专业场景的性能验证提供了黄金标准。
当前挑战
该数据集面临的核心挑战体现在双重维度:在领域问题层面,需解决天文学专业术语的语义理解难题,以及复杂天体物理概念与自然语言表述间的鸿沟,这对模型领域适应力提出极高要求;在构建过程中,确保专家答案的权威性与时效性需平衡最新研究成果与传统知识体系,而开放编码标签的制定则涉及多维度查询意图的精细分类,要求标注者兼具天文学素养与语言学洞察力。数据采集环节严格排除大语言模型介入的设定,进一步增加了高质量样本获取的复杂度。
常用场景
经典使用场景
在自然语言处理与天文学交叉领域,AstroLLMs Gold Benchmark Dataset为研究人员提供了评估大型语言模型在天文学问答任务中表现的标准基准。该数据集通过收集天文学家在Slack聊天机器人上提出的真实查询及专家回答,构建了一个包含开放编码标签和相关论文引用的高质量语料库。经典使用场景包括测试模型对专业天文概念的理解能力、验证模型生成答案的科学准确性,以及评估模型检索相关文献的效能。
实际应用
在实际应用层面,该数据集支撑了天文教育智能助手的开发,通过比对模型输出与专家答案的差异,持续优化问答系统的专业性。科研机构可基于该基准测试不同模型在天文文献检索任务中的表现,筛选最适合科研辅助的工具。出版单位则利用其评估自动摘要系统对天文论文关键信息的抓取准确度。
衍生相关工作
该数据集催生了多项重要研究,包括《天文领域语言模型评估指标体系构建》《基于语义编码的天文问答系统优化》等论文。相关团队进一步扩展了跨模态天文问答数据集AstroVQA,将文本查询与天体图像理解相结合。后续工作还发展了基于该基准的对抗测试方法,专门检测模型在天文专业术语推理中的脆弱性。
以上内容由遇见数据集搜集并总结生成


