SakanaAI/FishMath-SFT-Data
收藏Hugging Face2026-05-08 更新2026-05-10 收录
下载链接:
https://hf-mirror.com/datasets/SakanaAI/FishMath-SFT-Data
下载链接
链接失效反馈官方服务:
资源简介:
FishMath SFT Data是一个用于数学推理的合成监督微调(SFT)数据集,专为Kaggle AI数学奥林匹克3 - 进展奖3(AIMO 3)项目设计。该数据集包含23,257条由多个前沿开源大型语言模型(LLM)生成的正确解题轨迹,涵盖了来自不同来源的竞赛级数学问题。数据集的特点之一是包含工具集成推理(TIR)轨迹,其中约29%的轨迹涉及Python代码执行步骤。每条记录包含数学问题陈述、正确答案以及一个完整的对话轨迹(多轮消息),该轨迹最终得出正确答案。数据集的问题来源于两个精选数据集:nvidia/Nemotron-Math-v2和ycchen/Crystal-Math-Preview,并经过严格的正确性过滤和处理。
FishMath SFT Data is a synthetic Supervised Fine-Tuning (SFT) dataset for mathematical reasoning, used in the Kaggle AI Mathematical Olympiad 3 - Progress Prize 3 (AIMO 3) project. The dataset contains 23,257 correct solution traces generated by multiple frontier open-source large language models (LLMs), covering competition-level math problems from diverse sources. A key feature of the dataset is the inclusion of Tool-Integrated Reasoning (TIR) traces, where approximately 29% of the traces include Python code execution steps. Each record contains a math problem statement, its correct answer, and a full conversation trace (multi-turn messages) that arrives at the correct answer. The problems are drawn from two curated datasets: nvidia/Nemotron-Math-v2 and ycchen/Crystal-Math-Preview, and have undergone rigorous correctness filtering and processing.
提供机构:
SakanaAI
搜集汇总
数据集介绍
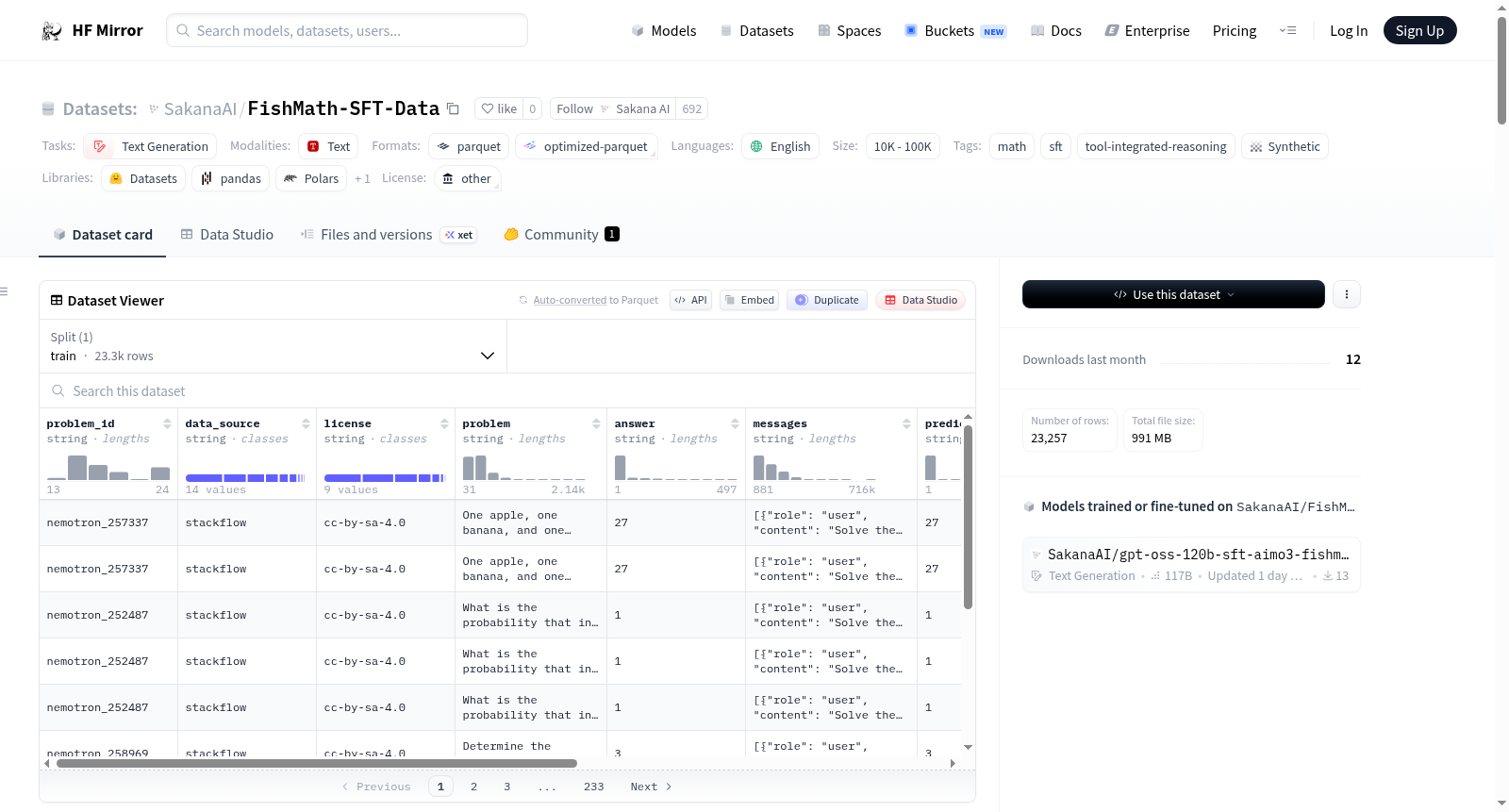
构建方式
FishMath-SFT-Data数据集专为数学推理任务设计,用于Kaggle AI Mathematical Olympiad 3竞赛。该数据集包含23,257条正确的解题轨迹,由多个前沿开源大语言模型生成,覆盖来自多样化来源的竞赛级数学问题。构建过程中,首先从nvidia/Nemotron-Math-v2和ycchen/Crystal-Math-Preview两个精选数据集中抽取问题,其中Nemotron-Math-v2中仅保留正确轨迹数不超过4条的最困难问题,以聚焦于高难度挑战。随后,利用Kimi-K2.5、DeepSeek-V3.2-Speciale等前沿模型对这些问题生成新的解题轨迹,并经过正确性过滤、停止原因过滤以及框式答案清理等多步骤处理,最终形成高质量的有监督微调数据集。
特点
该数据集的核心特点在于其高质量的合成数据与工具集成推理能力。约29%的轨迹包含多轮Python代码执行,通过工具集成推理增强数学问题的解决过程。数据来源广泛,涵盖stackflow、aops、Olympiads等数学社区,以及DAPO-17K、Omni-MATH等专业基准集,确保了问题的多样性与挑战性。每个记录包含问题、答案、完整对话轨迹及元数据,且所有轨迹均确保答案正确,为模型微调提供了可靠的监督信号。此外,Crystal-Math-Preview部分的问题答案被统一重写为整数形式,与竞赛格式完全对齐,提升了数据的实用性与一致性。
使用方法
使用该数据集时,可通过HuggingFace的datasets库轻松加载,示例如下:`from datasets import load_dataset; ds = load_dataset("SakanaAI/FishMath-SFT-Data", split="train"); record = ds[0]; messages = json.loads(record["messages"])`。对于包含工具集成推理的轨迹,需在训练或推理前预先定义工具参数,工具定义遵循OpenAI函数调用格式,允许模型在推理过程中调用Python代码进行复杂计算与验证。需要注意的是,数据集本身不包含工具定义,用户需根据提供的格式自行补充。此外,数据记录的license字段标记了原始问题的许可协议,使用时需遵循相应条款。
背景与挑战
背景概述
FishMath-SFT-Data是一个专为数学推理任务构建的合成监督微调(SFT)数据集,诞生于2024年Kaggle AI Mathematical Olympiad 3 - Progress Prize 3竞赛项目。该数据集由多个前沿开源大语言模型(包括Kimi-K2.5、DeepSeek-V3.2-Speciale、GLM-5等)生成,共计23,257条正确解题轨迹,覆盖5,621道来自StackFlow、AoPS、奥林匹克竞赛等多样信源的竞赛级数学问题。数据集旨在通过高质量、多轨迹的解题示范,提升语言模型在复杂数学推理中的泛化能力,其构建策略聚焦于原始数据集中最难的问题(即正确轨迹数极少的题目),并引入工具集成推理(TIR)机制,约29%的轨迹包含Python代码执行步骤。该数据集在推动数学推理专用大模型(如gpt-oss-120b)性能提升方面发挥了关键作用,为后训练阶段高能力模型的构建提供了重要方法论支撑。
当前挑战
FishMath-SFT-Data所解决的领域挑战在于,现有数学推理数据集往往覆盖基础题目,对高难度竞赛级问题的训练数据稀疏,且模型在复杂推理中易产生逻辑断层或计算错误,尤其缺乏对工具调用(如代码执行)与自然语言推理协同的建模。数据集构建过程中面临多重挑战:其一,从来源数据集(如Nemotron-Math-v2)中筛选真正困难的问题时,需对每题48次求解尝试的轨迹进行正确性过滤,但发现部分问题本身存在定义不清、前置条件缺失或标准答案错误等质量问题,导致噪声引入;其二,在生成新轨迹时,需确保模型输出完整且未被截断(仅保留自然停止的轨迹),并清洗中间步骤中与最终答案不一致的盒装表达式;其三,针对工具集成推理轨迹,需维护多轮对话中函数调用的格式一致性,且不包含工具定义本身,增加了训练阶段的预处理复杂性。
常用场景
经典使用场景
FishMath-SFT-Data数据集最经典的使用场景在于为大语言模型数学推理能力的监督微调提供高质量的合成训练轨迹。该数据集精心收录了超过两万三千条由多个前沿开源模型(如Kimi-K2.5、DeepSeek-V3.2)生成的正确解题记录,覆盖来自StackFlow、AoPS等丰富来源的竞赛级数学难题。每条记录包含完整的多轮对话,其中近三成轨迹集成了Python代码执行的工具集成推理,使模型在解题过程中能够调用外部计算工具,模拟人类数学推理的严谨验证过程。这一设计使得该数据集特别适合用于训练需要在严苛推理约束下呈现高精度解答的数学推理模型,成为提升模型解决复杂数学问题能力的核心数据基础。
衍生相关工作
该数据集的构建与运用已经催生出若干具有影响力的后续工作。最直接的例子是Pushing the Limits: Post-Training High-Capability Models under Strict Inference项目,该工作利用FishMath-SFT-Data对大型模型进行微调,展示了如何在严格推理约束下进一步提升模型的数学处理能力。同时,数据集通过聚焦原始Nemotron-Math-v2语料中最难的题目(即正确轨迹不超过四条的问题)并重新生成高质量解答,为探索困难问题下的模型行为与数据增强策略提供了新视角。此外,对低质量问题和错误参考答案的发现也激励了后续关于训练数据噪声过滤与问题重写的研究,推动了更精细化的数学推理数据集构建方法论的出现。
数据集最近研究
最新研究方向
FishMath-SFT-Data数据集聚焦于数学推理领域的前沿探索,其核心研究方向在于通过合成监督微调数据提升大语言模型在奥赛级数学问题上的求解能力。该数据集依托Kaggle AIMO 3竞赛背景,整合了来自Nemotron-Math-v2与Crystal-Math-Preview等精选来源的硬核难题,并利用Kimi-K2.5、DeepSeek-V3.2等前沿开源模型生成高质量解题轨迹,其中约29%的轨迹融合了工具集成推理(TIR),通过Python代码执行增强逻辑验证与计算精度。这一工作呼应了当前大模型后训练阶段追求极致推理能力的趋势,尤其针对传统模型在复杂数学竞赛场景中的薄弱环节进行突破,为构建高能力、强泛化的数学推理系统提供了关键数据基石,对推动AI在奥林匹克数学等结构化挑战中的表现具有深远意义。
以上内容由遇见数据集搜集并总结生成


