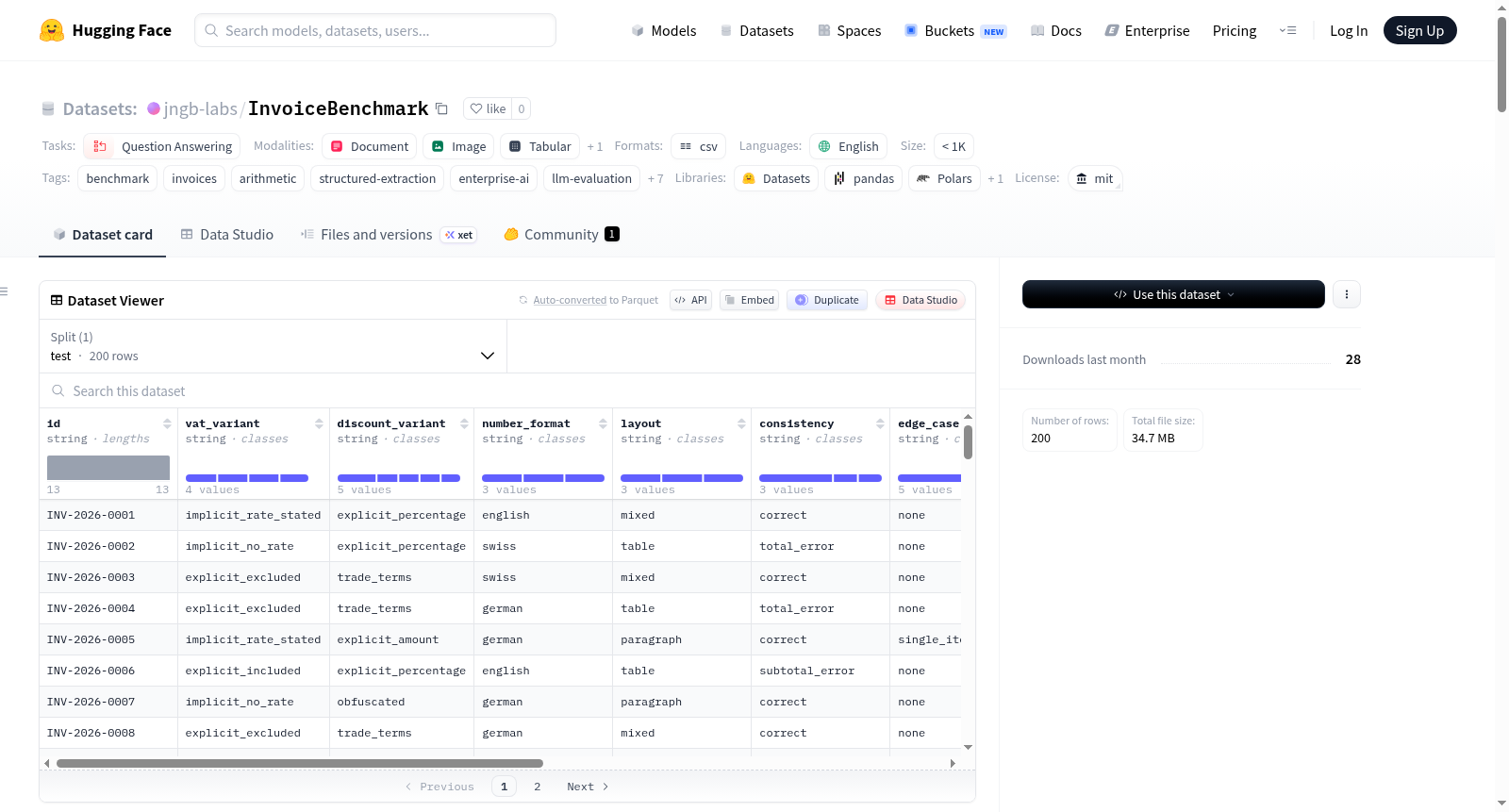
InvoiceBenchmark
收藏InvoiceBenchmark 数据集概述
基本信息
- 数据集名称: InvoiceBenchmark
- 许可证: MIT
- 任务类型: 问答(question-answering)
- 语言: 英语
- 数据集大小: 少于 1000 条样本
- 标签: benchmark、invoices、arithmetic、structured-extraction、enterprise-ai、llm-evaluation、number-formatting、vat、financial-documents、document-understanding、vision、multimodal、ocr
数据集描述
该数据集包含 200 张合成发票,具有精确到分的真实标注(ground truth),专门用于评估语言模型从发票中读取数字的能力。每种发票提供两种格式:
- Markdown 版本:纯文本格式,适合直接输入到提示词中。
- PDF 版本:渲染后的样式化文档,同时提供 200 DPI 的 PNG 版本,适合多模态或视觉模型作为图像输入。
- 地面真相(Ground Truth):每个发票对应一个 JSON 文件,记录规范的正确值、构建参数以及(对于注入错误的发票)正确值和故意错误值。
所有货币值使用 Python 的 Decimal 类型,采用 ROUND_HALF_UP 舍入方式,确保精确到分。
五个控制维度
每个发票沿以下五个受控轴变化,目的是在控制其他变量不变的情况下,单独变化一个因素,从而归因模型的失败原因:
1. VAT 表述(4 种变体)
explicit_included:价格已含 VAT,模型不得重复计算explicit_excluded:VAT 额外加收implicit_rate_stated:税率可见,是否含税不明确implicit_no_rate:显示 VAT 金额,但省略税率
2. 折扣表述(5 种变体)
none:无折扣(作为模型不会虚构折扣的校验)explicit_percentage:明确百分比折扣explicit_amount:固定金额减免trade_terms:条件性折扣(如“2/10 net 30”),不应应用obfuscated:百分比隐藏在参考字符串中
3. 数字格式(3 种变体)
english:1,234.56german:1.234,56(德语逗号是数据集中最具陷阱性的格式)swiss:1234.56
4. 布局(3 种变体)
table:Markdown 管道表格paragraph:散文段落mixed:行项目用表格,摘要用散文
5. 一致性(3 种变体)
correct(60%):发票加总正确subtotal_error(20%):小计金额错误 ±5 到 ±50 欧元total_error(20%):总计金额错误 ±1–3%
第六维度:边缘情况(占数据集的 10%)
reverse_charge:0% VAT(第 196 条)mixed_vat:两种 VAT 税率credit_note:负金额(贷项通知单)single_item:单一行项目
基准测试结果
2026 年 5 月测试了五种开放权重模型,采用两种评估条件:
- 自动驾驶模式:模型直接读取发票并报告总计。
- 混合模式:模型提取结构化字段,Python 重新计算总计。
| 模型 | 解析率 | 精确匹配(自动驾驶) | 精确匹配(混合) | 错误但通过审核 | 错误检测率 | 最严重单个错误 | 每张发票耗时 | 硬件 | 运行成本 |
|---|---|---|---|---|---|---|---|---|---|
| Llama 3.1 8B | 99% | 69% | 43% | 23% | 18% | 99.9% | 25s | MacBook Air | 免费 |
| Qwen3 8B | 57% | ~85%* | ~77%* | ~13%* | 45% | 100%* | 32s | 1× H100 | €2.73/小时 |
| Gemma 4 31B | 100% | 83% | 83% | 18% | 83% | 3% | 19s | 1× H100 | €2.73/小时 |
| QwQ 32B | 81% | ~73%* | ~77%* | ~11%* | 38% | 100%* | 112s | 1× H100 | €2.73/小时 |
| Llama 3.3 70B | 100% | 77% | 81% | 16% | 75% | 99.9% | 3s | 8× H100 | €23/小时 |
*其中模型产生可解析输出的发票。
关键发现
- 推理模型表现更差:8B 推理模型 43% 的输出无法解析;32B 推理模型在 22 张发票上推理出 €0.00。
- 更大的模型不一定更好:Llama 70B(8 GPU)不如 Gemma 31B(1 GPU)。
- 德语逗号是最昂贵的标点符号:
364.065,64被读作 364.065 而非 364,065,导致结果偏差。
数据格式说明
发票(Markdown)
纯文本渲染的欧洲 B2B 发票。公司名称为虚构(如 Pierce & Pierce、Vandelay Industries 等),地址为编造,IBAN 具有正确的国家前缀和长度但数字随机。
发票(PDF)
样式化的单页 PDF 发票(同时提供 200 DPI PNG 版本)。包含行项目表格、头部信息和摘要部分。德语、瑞士和英语数字格式在视觉上保留。
地面真相(JSON)
每条记录包含:
invoice_id:发票编号vendor:供应商名称subtotal/vat_rate/vat_amount:小计、VAT 税率、VAT 金额discount:折扣类型、值、应用对象、是否条件性discount_amount/total:折扣金额、总计variants:所有五个维度的变体及边缘情况rendered_subtotal/rendered_total:模型实际看到的金额(与total的区别在于错误注入的发票中,rendered_total是错误值,total是正确答案)error_note:错误注释
已知限制
- 所有发票使用英语渲染,无论供应商隐含国籍。
- 主语料库仅使用 20% 的单一 VAT 税率,未模拟国家特定税率(19% DE、21% NL、25% NO)。
- 语料库设计为 200 张发票,可通过
--count参数扩展。 - 公司名称来源于电影、电视和小说,可能影响已知模型的解析。
如何使用
生成语料库
bash python invoice_generator.py --output ./output --count 200 --seed 42
确定性生成,需 Python 3.10+,无外部依赖。
验证地面真相
bash python invoice_generator.py --output ./output --verify
运行基准测试
bash
本地模型(Ollama)
python run_benchmark.py --models llama3.1:8b
远程模型(vLLM)
python run_benchmark.py --models vllm:google/gemma-4-31b-it --vllm-url http://gpu-server:8000/v1
多个模型
python run_benchmark.py --models llama3.1:8b,qwen3:8b --conditions B
支持两种条件:B(自动驾驶)和 C(混合模式)。
评分标准
- 精确匹配:模型的报告总计与地面真相总计精确到分一致。
- 错误但足够接近:答案在 5% 范围内(可通过人工审核的错误类型)。