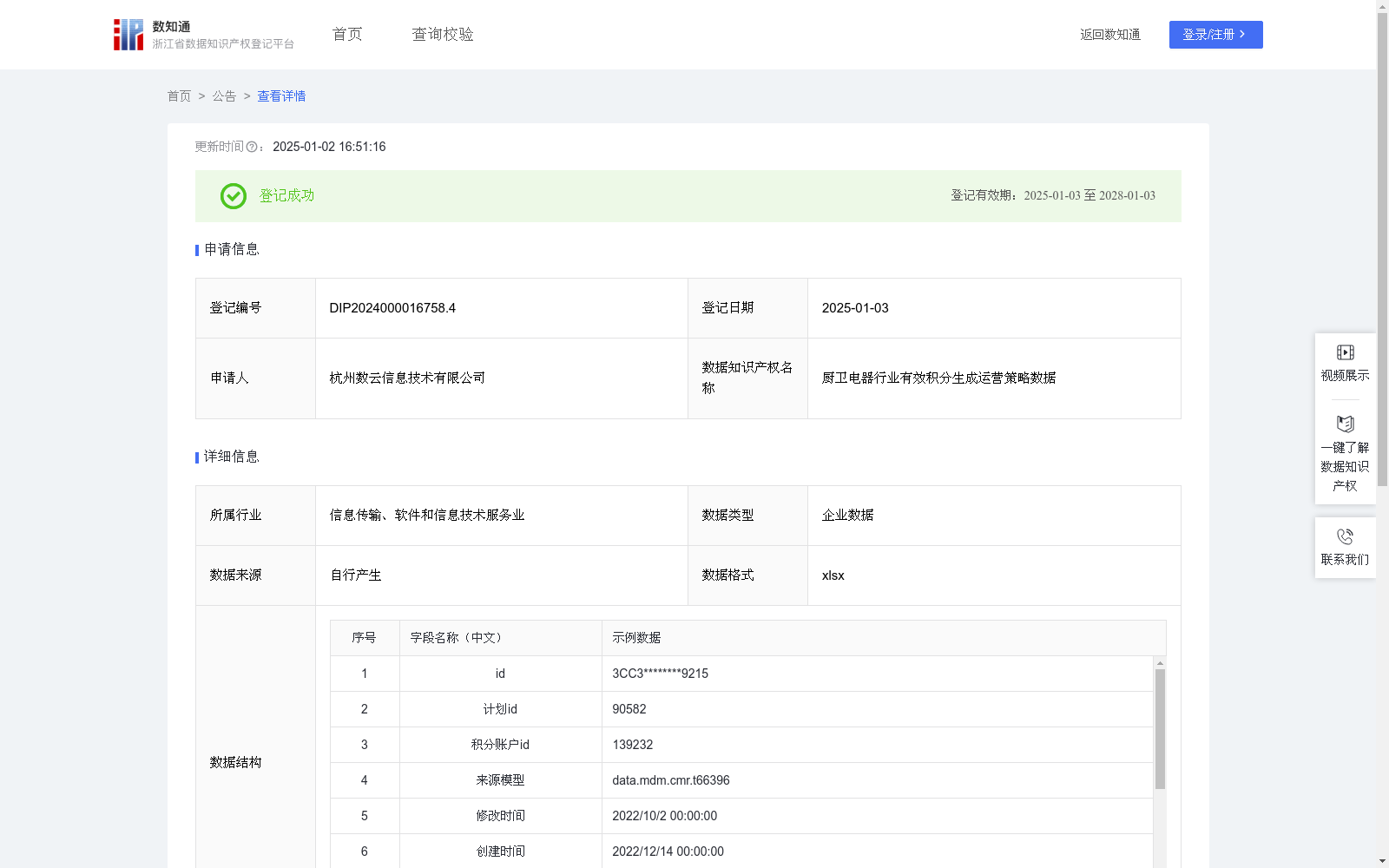
厨卫电器行业有效积分生成运营策略数据
收藏浙江省数据知识产权登记平台2025-01-02 更新2025-01-03 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/109861
下载链接
链接失效反馈官方服务:
资源简介:
此数据的核心是通过厨卫电器行业会员累计获取积分、使用和有效性,结合数据模型为不同用户的个性化运营提供策略支持。通过分析各项累计积分数据,精准定位用户当前是可用有效积分情况,结合积分兑现率确定有效积分所处分位,指导企业制定更具针对性的个性化积分运营策略,推动围绕积分的会员活跃度并优化成本效益。该数据方法可广泛应用于厨卫电器行业、零售企业、电信运营公司、医疗健康、民生服务等单位,有助于企业通过此类分析数据来制定个性化运营策略,节省成本、提升营销效果。数据处理:取特定积分账户ID为唯一标识,根据数据来源模型,对原始数据经过清洗和去重处理。
数据加工:该数据集中“当前可用有效积分值”:会员账户中当前可使用的有效积分数量=累计获取积分 - 累计使用积分 - 累计过期积分。“积分兑现率”:积分使用的效率,计算公式为(累计使用积分 / 累计获取积分)*100%。“PER_有效积分所处分位”:依据当前可用有效积分值在整体会员中的百分位分布,精确到小数点后两位。“积分运营策略分组”:根据PER_有效积分所处分位将会员分配至不同的策略分组。(≥95)—高额兑换引导组;(90-95)—核心激励组;(75-90)—优先消耗组;(55-75)—日常兑换推广对象;(45-55)—平衡管理对象;(25-45)—积累提升对象;(10-25)—激励增长用户;(5-10)—低频激活重点用户;(0-5)—零积分复苏用户。
数据应用:通过此数据的全面分析和分组管理,企业能够对会员的积分状态进行精细化运营,并实现差异化营销策略,从而推动会员忠诚度与积分活跃度的提升。
提供机构:
杭州数云信息技术有限公司
创建时间:
2024-11-26
搜集汇总
数据集介绍
特点
该数据集包含厨卫电器行业会员的积分数据,用于个性化运营策略支持,数据规模为1501条,每日更新,适用于多个行业的积分运营分析。
以上内容由遇见数据集搜集并总结生成


