QTSplus-Dataset
收藏QTSplus-Dataset 数据集概述
数据集简介
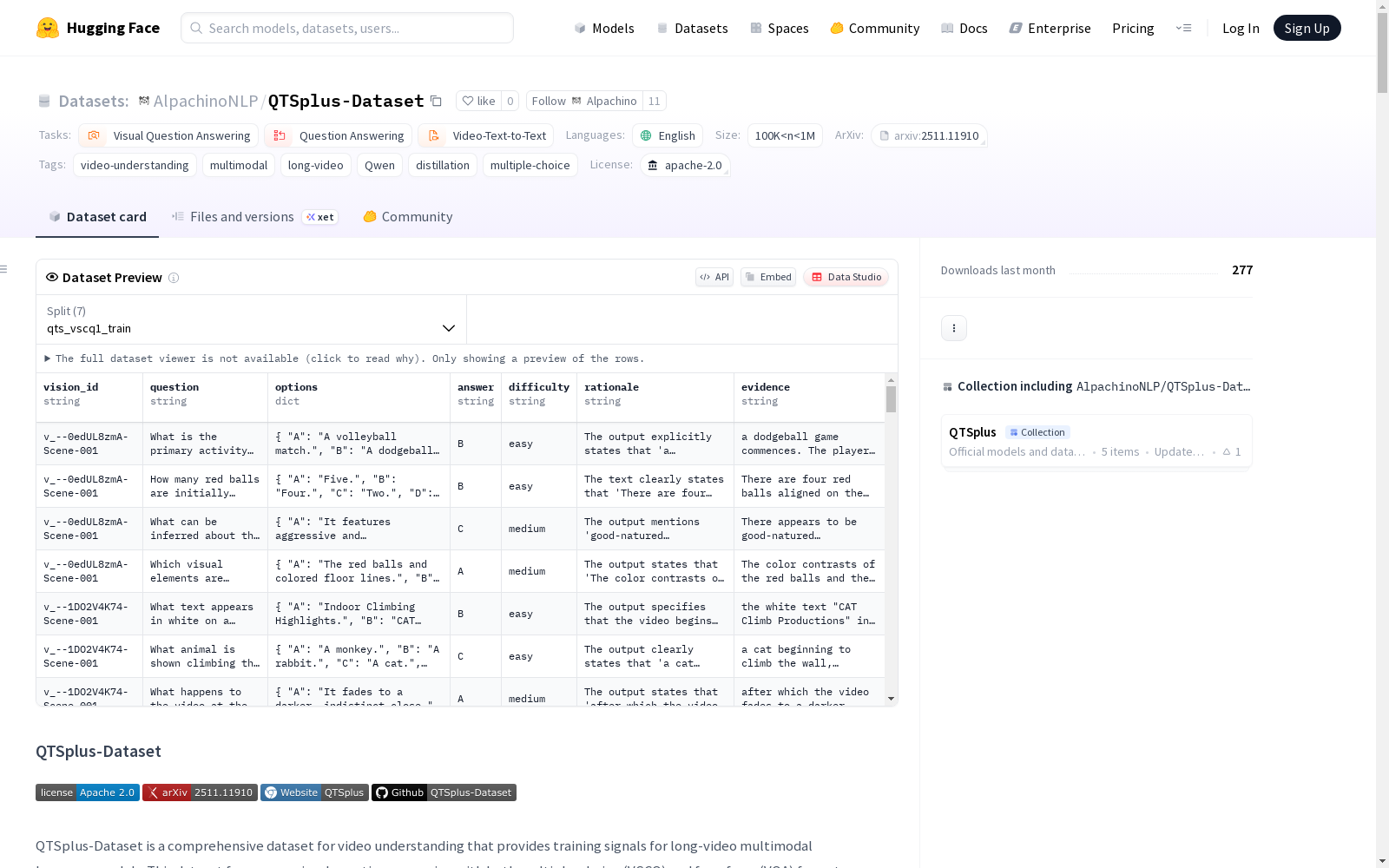
QTSplus-Dataset 是一个用于视频理解任务的综合数据集,专门为长视频多模态语言模型提供训练信号。该数据集主要关注视觉问答任务,包含多项选择题(VSCQ)和自由形式问答(VQA)两种格式。
数据集组成
三级分层数据集结构
QTS-VSCQ1
- 描述:通过纯文本模型(Qwen3-235B)合成的大规模视觉单项选择题数据集
- 规模:超过855,000个多项选择题
- 来源:基于视频字幕生成
QTS-VSCQ2
- 描述:QTS-VSCQ1的精选子集,仅包含视觉语言模型(Qwen2.5-VL)回答正确的问题
- 模型版本:
- Qwen2.5-VL-3B-Instruct:759,650个正确示例(训练集),4,486个正确示例(评估集),89,851个错误示例(训练集)
- Qwen2.5-VL-7B-Instruct:771,218个正确示例(训练集)
- 准确率:3B模型22.24%,7B模型76.56%
QTS-VQA
- 描述:针对QTS-VSCQ2中的问题,由视觉语言模型生成的自由形式答案
- 模型版本:
- Qwen2.5-VL-3B-Instruct:544,138个正确示例(训练集),342个错误示例(训练集)
- Qwen2.5-VL-7B-Instruct:399,548个正确示例(训练集)
数据特征
问题类型
数据集涵盖9种不同的问题类型:
- 物体识别(object_identity)
- 属性识别(attribute_color_material_shape)
- 场景文本识别(text_in_scene)
- 数量统计(count_quantity)
- 活动识别(action_activity)
- 场景定位(setting_location)
- 时序顺序(temporal_order)
- 人物属性(person_attribute)
- 因果关系(cause_effect_or_purpose)
难度分布
- 简单级别:约59%
- 中等难度:约40%
- 困难级别:约0.5%
答案分布
- 多项选择题答案选项(A、B、C、D)分布均衡,各占约25%
- 自由形式答案平均长度:3B模型145字符,7B模型220字符
数据格式
QTS-VSCQ1数据格式
json { "source_id": "original-video-id", "qa_id": "original-video-id-Q01", "question": "What activity is being performed?", "options": {"A": "Rock climbing", "B": "Swimming", "C": "Running", "D": "Dancing"}, "correct_option": "A", "correct_answer": "Rock climbing", "question_type": "action_activity", "difficulty": "easy", "rationale": "The text states climber is seen using various holds and ledges", "evidence_span": "climber is seen using various holds and ledges" }
QTS-VSCQ2/QTS-VQA数据格式
json { "vision_id": "video-12345-Scene1", "question": "What activity is being performed in this video?", "options": {"A": "Swimming", "B": "Rock climbing", "C": "Dancing", "D": "Running"}, "answer": "B", "prediction": "B" 或 "The person in the video is rock climbing...", "rationale": "The video shows a person scaling a rock wall...", "evidence": "The climber is seen using various holds and ledges...", "difficulty": "easy" }
目录结构
QTS-VSCQ2目录结构
QTS-VSCQ2/ ├── Qwen2.5-VL-3B-Instruct/ │ ├── prediction_correct_train.jsonl │ ├── prediction_correct_eval.jsonl │ └── prediction_wrong_train.jsonl └── Qwen2.5-VL-7B-Instruct/ ├── prediction_correct_train.jsonl ├── prediction_correct_eval.jsonl └── prediction_wrong_train.jsonl
QTS-VQA目录结构
QTS-VQA/ ├── Qwen2.5-VL-3B-Instruct/ │ ├── prediction_correct_train.jsonl │ └── prediction_wrong_train.jsonl └── Qwen2.5-VL-7B-Instruct/ └── prediction_correct_train.jsonl
设计原则
- 文本基础问题:所有问题和答案仅基于视频内容
- 单一正确答案:每个问题有且仅有一个明确正确答案
- 合理干扰项:错误选项设计语义相似、长度风格一致
- 证据基础答案:每个答案包含解释理由和具体证据
- 难度平衡:问题按复杂度分为三个难度级别
相关资源
- 源数据集:https://huggingface.co/ShareGPTVideo
- GitHub仓库:https://github.com/QTSplus/QTSplus-Dataset
- 许可证:MIT