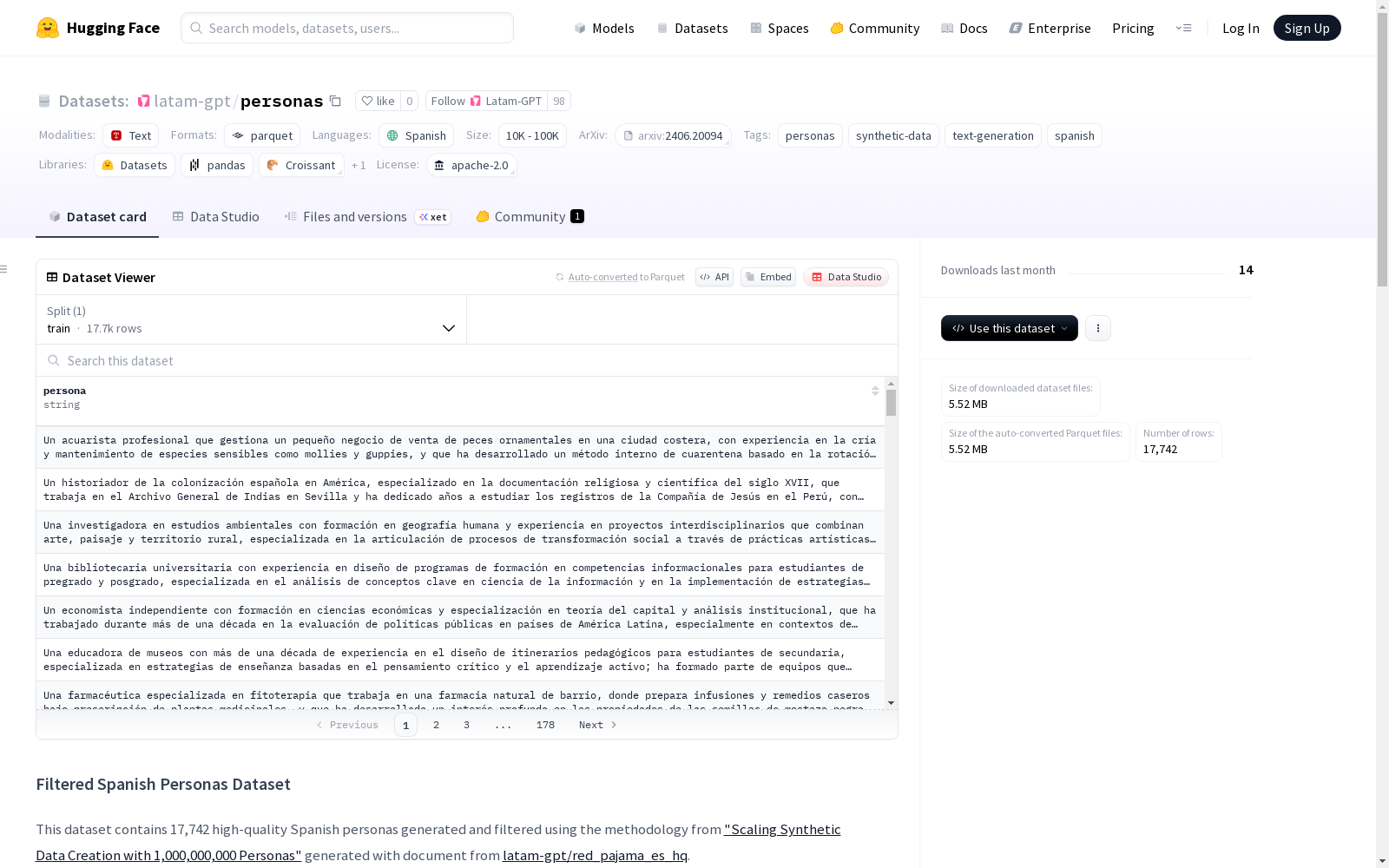
personas
收藏数据集概述
基本信息
- 语言:西班牙语 (es)
- 许可证:Apache 2.0
- 标签:personas、synthetic-data、text-generation、spanish
- 规模:10K<n<100K
数据集描述
该数据集包含17,742个高质量的西班牙语personas,采用"Scaling Synthetic Data Creation with 1,000,000,000 Personas"中的方法生成和过滤,使用latam-gpt/red_pajama_es_hq文档生成。
过滤流程
-
MinHash去重
- 参数:128个哈希函数,0.9相似度阈值
- N-gram大小:1
-
嵌入相似性过滤
- 模型:
sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 - 相似度阈值:0.85
- 使用FAISS进行高效相似性搜索
- 模型:
生成详情
- 模型:Qwen/Qwen3-30B-A3B-Instruct-2507
- 温度:0.3
- 原始数据集大小:100000
- 过滤后数据集大小:17742
使用方式
python from datasets import load_dataset dataset = load_dataset("latam-gpt/personas")
引用
原始方法
bibtex @article{ge2024scaling, title={Scaling Synthetic Data Creation with 1,000,000,000 Personas}, author={Ge, Tao and Chan, Xin and Wang, Xiaoyang and Yu, Dian and Mi, Haitao and Yu, Dong}, journal={arXiv preprint arXiv:2406.20094}, year={2024} }
本实现
bibtex @misc{latam-gpt-personas, title={Spanish Personas}, author={LatamGPT Team}, howpublished={url{https://huggingface.co/datasets/latam-gpt/personas}}, year={2025}, note={Implementation of persona generation and filtering methodology for Spanish language} }
致谢
该数据集是LatamGPT项目的一部分。
特别感谢:
- 原始persona生成方法的作者
- 本流程中使用的开源工具贡献者(vLLM、sentence-transformers、FAISS、HuggingFace)
许可证
Apache 2.0许可证。