Dog100K
收藏Hugging Face2026-05-16 更新2026-05-21 收录
下载链接:
https://huggingface.co/datasets/choucsan/Dog100K
下载链接
链接失效反馈官方服务:
资源简介:
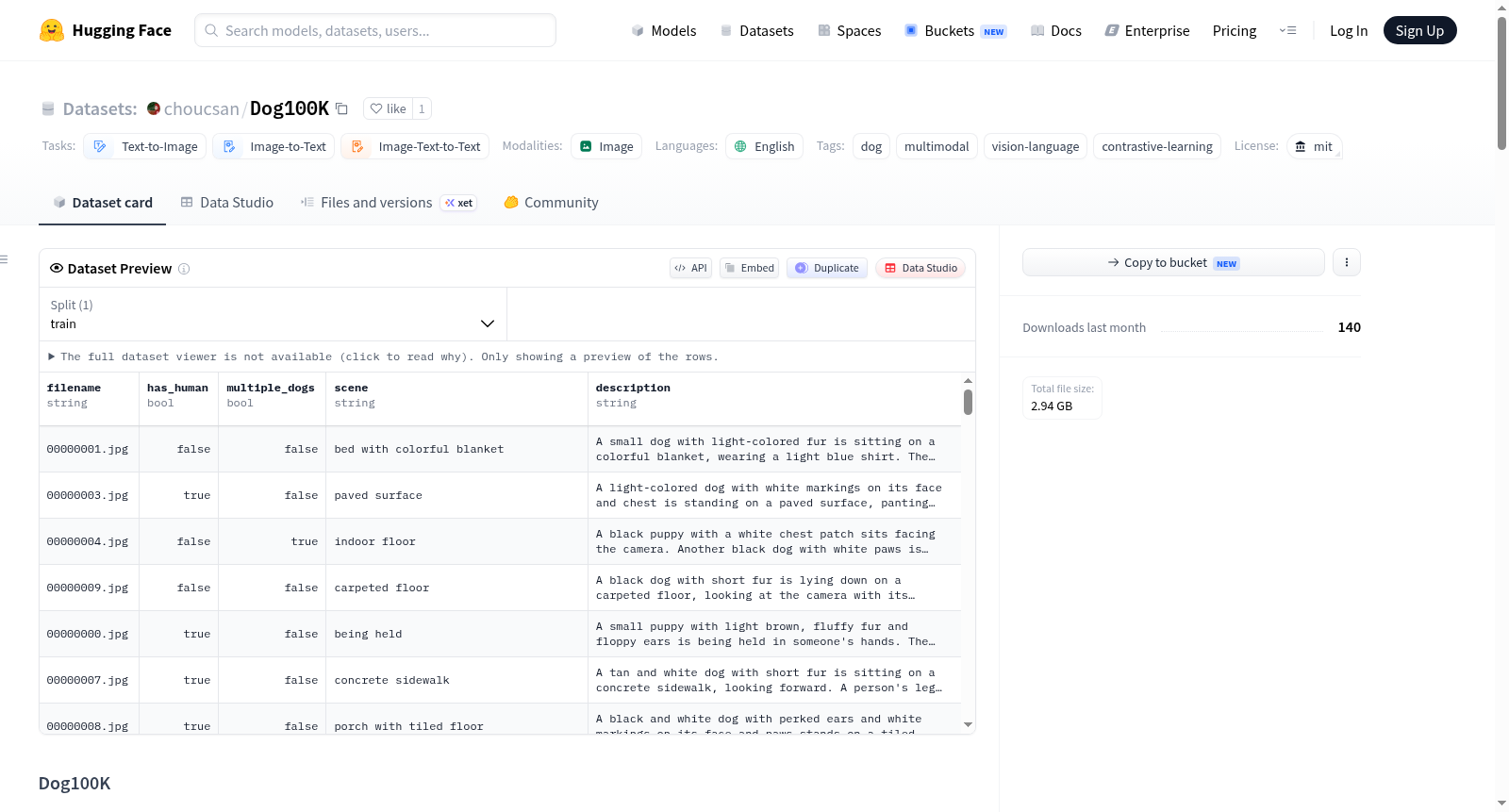
Dog100K 是一个大规模、高质量的狗图像-文本对齐数据集,包含 103,508 个图像-文本对。该数据集专为图像-文本检索、多模态学习和条件图像生成等任务而设计。数据通过多阶段流程构建,包括从多样来源收集狗图像、进行分辨率、相关性和多样性方面的质量过滤、为每张图像标注包含品种、动作、场景以及是否有人类或多只狗存在的细粒度自然语言描述,并进行准确性验证。图像以 JPEG 格式存储,注释以 JSONL 格式存储,每个样本包含文件名(filename)、是否有人类(has_human)、是否有多个狗(multiple_dogs)、简要场景描述(scene)和详细的自然语言描述(description)五个字段。数据集覆盖了多样的犬种、姿态、场景、光照条件和背景,旨在增强模型的泛化能力。该数据集开源,可用于学术研究和工业应用,适用于图像-文本检索、图像描述生成、基于文本的条件图像生成(如 DiT、Stable Diffusion)以及多模态对比学习(如 CLIP、BLIP)等任务。
Dog100K is a large-scale, high-quality dog image-text alignment dataset containing 103,508 image-text pairs. It is specifically designed for tasks such as image-text retrieval, multimodal learning, and conditional image generation. The dataset is constructed through a multi-stage pipeline, which includes collecting dog images from diverse sources, applying quality filtering based on resolution, relevance, and diversity, annotating each image with fine-grained natural language descriptions covering breed, action, scene, and the presence of humans or multiple dogs, and conducting accuracy verification. Images are stored in JPEG format, and annotations are stored in JSONL format, with each sample including five fields: filename, has_human, multiple_dogs, scene, and description. The dataset covers a wide variety of dog breeds, poses, scenes, lighting conditions, and backgrounds, aiming to enhance model generalization. It is open-source and suitable for academic research and industrial applications, applicable to tasks such as image-text retrieval, image caption generation, text-based conditional image generation (e.g., DiT, Stable Diffusion), and multimodal contrastive learning (e.g., CLIP, BLIP).
创建时间:
2026-05-10
搜集汇总
数据集介绍
构建方式
Dog100K数据集的建设遵循一套精密的多阶段流水线。首先,从多元渠道广泛采集犬类图像,以确保涵盖丰富的犬种、场景及姿态。接着,通过严格的质量筛选机制,依据分辨率、相关性及多样性等标准剔除低质量样本。随后,为每一张图片赋予细粒度的自然语言标注,详细描述犬种、动作、场景以及是否包含人类或多只犬。最后,经过严谨的审核与验证,确保注释的准确性与一致性,从而构建出包含超过十万对高质量图文配对的数据集。
特点
该数据集拥有103,508对图像与文本,具备大规模、细粒度与高多样性等显著特征。其注释不仅涵盖基本的场景描述,还包含丰富的语义信息,如犬只的行为、服饰及环境细节。图像数据在光照条件、背景和视角上展现出丰富的变异性,能够有效提升模型的泛化能力。作为开源资源,Dog100K免费提供给学术界与工业界,助力多模态学习的深入研究。
使用方法
使用Dog100K数据集十分便捷。用户可通过Hugging Face平台直接下载压缩包,并利用Python的`huggingface_hub`库进行获取与解压。加载数据时,可读取JSONL格式的注释文件,配合PIL库处理JPEG图像,快速访问每一条图文配对。该数据集支持图像-文本检索、图像描述生成、条件图像生成及对比学习等多种应用场景,适配如CLIP、BLIP及Stable Diffusion等先进模型,为多模态研究提供坚实基础。
背景与挑战
背景概述
犬类作为人类生活中最为亲密的伴侣动物之一,其视觉与语言的多模态理解在人工智能领域具有重要的研究价值与应用前景。Dog100K数据集由研究团队choucisan于近年创建,旨在填补大规模、高质量的犬类图像-文本对齐数据集的空白。该数据集包含超过10万对图像与精细的自然语言描述,覆盖多样化的犬种、姿态、场景及光照条件,为图像-文本检索、多模态对比学习、条件图像生成等任务提供了坚实的基准资源。其开源特性已吸引学术界与工业界的广泛关注,推动了犬类相关视觉语言模型的发展。
当前挑战
当前Dog100K数据集面临的核心挑战包括多方面的领域难题。在解决领域问题层面,现有多模态模型在细粒度犬类特征(如品种、动作、情绪)的跨模态对齐上仍存在显著不足,尤其在包含人类或多犬的复杂场景中,模型常出现语义理解偏差与检索精度下降的问题。在构建过程层面,如何从海量互联网图像中高效筛选并确保标注的准确性与一致性是主要难点,人工标注成本高且易受主观因素影响,同时需平衡犬种分布的均衡性与场景的多样性,以避免数据偏差导致的模型泛化能力下降。
常用场景
经典使用场景
Dog100K作为目前规模最大的高质量犬类图像-文本对齐数据集之一,其核心应用场景聚焦于跨模态检索与多模态表示学习。数据集包含超过10万对精心配对的图像与自然语言描述,覆盖犬种、动作、场景及人类共现等丰富语义信息,为训练和评估图文双向检索模型提供了理想基准。研究者可借助该数据集构建细粒度的跨模态语义对齐模型,推动视觉与语言在高阶概念层面上的统一表征。
衍生相关工作
围绕Dog100K数据集,学术界已涌现一系列具有代表性的衍生研究工作。在图像描述生成领域,研究者基于该数据集训练出能够精细描述犬类品种、衣着与表情的序列生成模型。在文本到图像合成方向,利用Dog100K微调扩散模型(如Stable Diffusion)以提升对特定物种的语义可控性已成为常见范式。此外,该数据集还被广泛用于评估对比学习框架(如CLIP、BLIP)在细粒度多模态理解任务上的泛化能力,推动了相关算法的迭代优化。
数据集最近研究
最新研究方向
在视觉语言模型蓬勃发展的大背景下,Dog100K作为迄今规模最大、质量最优的犬类图像-文本对齐数据集之一,正引领着细粒度多模态学习的前沿探索。该数据集囊括十万余幅涵盖丰富犬种、姿态与场景的高清图像,并为每幅图像配备了包含品种、动作、环境及人物共现关系等精细语义的自然语言描述,为跨模态检索与图文理解研究提供了坚实的数据基石。当前,研究者正借助这一资源推动条件式图像生成模型(如DiT、Stable Diffusion)在特定物种细粒度控制生成上的突破,并基于其对比学习范式优化CLIP、BLIP等视觉语言融合架构的表征能力。同时,该数据集的开放性与高多样性正在加速犬类行为分析与智能宠物识别等热点应用的落地,在通用视觉语言模型向专业化、精细化演进的过程中扮演着不可或缺的验证与驱动角色。
以上内容由遇见数据集搜集并总结生成


