【我遇到的问题】 • 现象:该数据集的下载链接已失效 【相关信息】 • 可考虑访问这个链接获取类似文件~https://www.selectdataset.com/dataset/3688356173feccbcf1f1e490ddc6bc72
SFT-Dataset
收藏Hugging Face2026-03-30 更新2026-03-31 收录
下载链接:
https://huggingface.co/datasets/SeaFill2025/SFT-Dataset
下载链接
链接失效反馈官方服务:
资源简介:
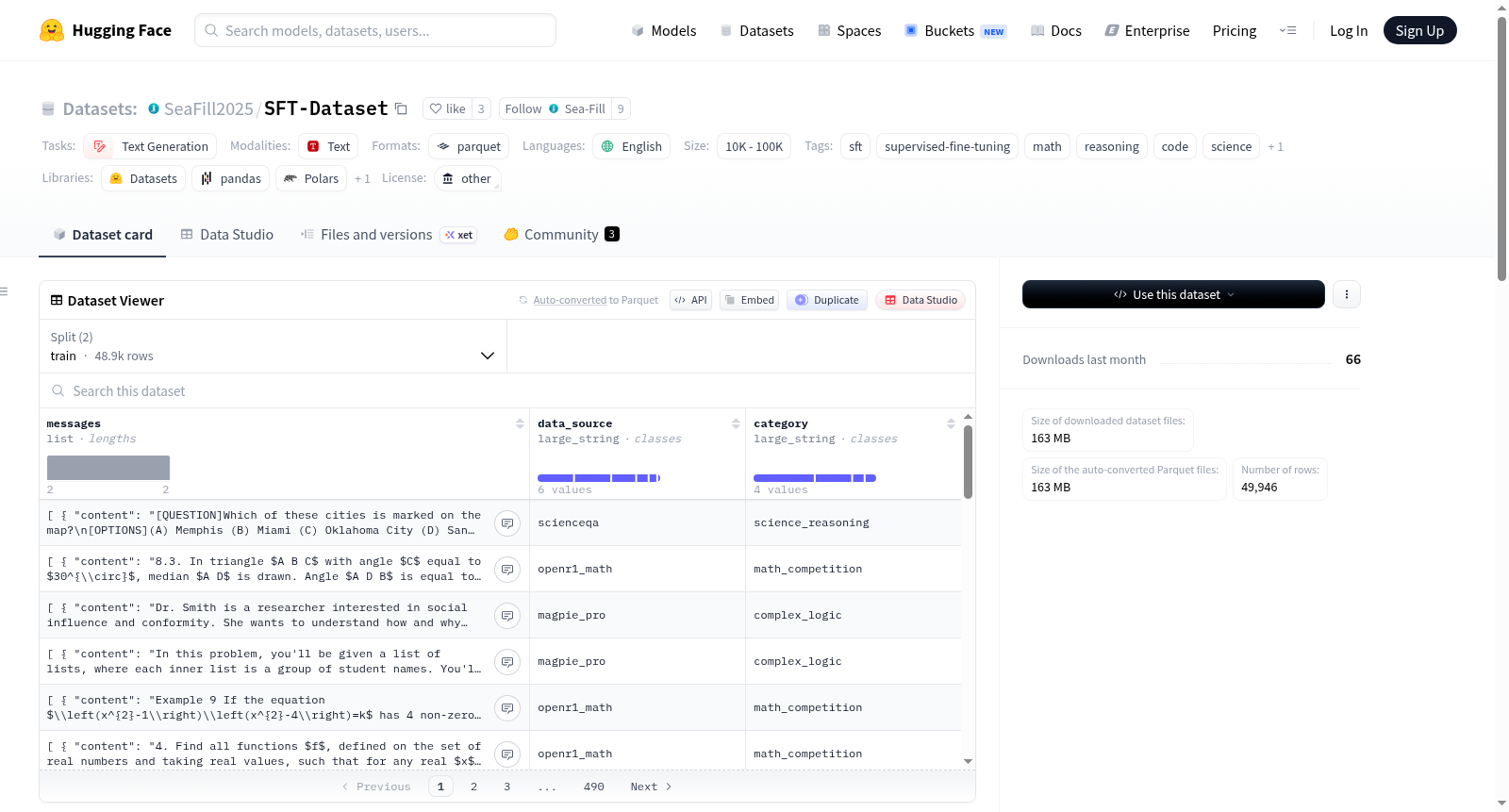
SFT-Dataset 是一个用于监督微调基础模型(如 Qwen/Qwen3-4B-Base 或 Qwen/Qwen3-8B-Base)的高质量数据集,旨在为后续的强化学习奠定良好基础。数据集包含约 50k 训练样本和 1k 测试样本,数据格式为 parquet 文件,主要字段包括 messages、data_source 和 category。数据集由多个上游数据源混合而成,包括 OpenR1-Math-220k、NuminaMath-CoT、Magpie-Llama-3.1-Pro-300K-Filtered、CodeFeedback-Filtered-Instruction、ScienceQA 以及内部科学数据切片。数据风格多样,部分数学和科学数据使用 Qwen 风格的标记,而逻辑和代码数据则通常为普通答案。适用于文本生成任务,特别是在数学、推理、代码和科学领域。
创建时间:
2026-03-22
原始信息汇总
SFT-Dataset 概述
基本信息
- 数据集名称:SFT-Dataset
- 发布者/社区:Sea-Fill Community (Hongyang Li, Xiao Li)
- 发布日期/年份:2026
- 语言:英语 (en)
- 许可证:复合许可证 (Other),需遵守每个上游数据源的许可协议
- 标签:sft, supervised-fine-tuning, math, reasoning, code, science, parquet
- 任务类别:文本生成 (text-generation)
- 数据规模:10K < n < 100K
数据集目的与特点
- 核心目的:为基座模型(例如
Qwen/Qwen3-4B-Base或Qwen/Qwen3-8B-Base)的监督微调提供数据。旨在构建一个为后续强化学习奠定良好基础的策略模型。 - 数据特点:强调适量、高质量和均衡的配方。
- 应用实例:
Qwen3-4B-SFT模型(https://huggingface.co/96kevinli29/Qwen3-4B-SFT)使用此混合数据集训练,其模型卡上的基准测试结果展示了训练效果。
数据构成与来源
数据集由多个上游高质量数据集混合而成,具体来源及目标数量如下:
| 数据源标识 | 上游数据集 | 目标数量 |
|---|---|---|
openr1_math |
OpenR1-Math-220k (https://huggingface.co/datasets/open-r1/OpenR1-Math-220k) | 15k |
numina_cot |
NuminaMath-CoT (https://huggingface.co/datasets/AI-MO/NuminaMath-CoT) | 10k |
magpie_pro |
Magpie-Llama-3.1-Pro-300K-Filtered (https://huggingface.co/datasets/Magpie-Align/Magpie-Llama-3.1-Pro-300K-Filtered) | 15k |
codefeedback |
CodeFeedback-Filtered-Instruction (https://huggingface.co/datasets/m-a-p/CodeFeedback-Filtered-Instruction) | 5k |
scienceqa |
ScienceQA (https://huggingface.co/datasets/TheMrguiller/ScienceQA) | ~3.4k |
science_sft |
内部 GPQA 对齐的科学数据切片(非独立的 Hub 数据集) | ~1.5k |
数据格式与结构
- 数据文件格式:Parquet
- 数据划分:
- 训练集:约 49k 条 (
train.parquet) - 测试集:约 1k 条 (
test.parquet)
- 训练集:约 49k 条 (
- 数据列:
messages:对话消息。data_source:数据来源标识。category:数据类别。
- 风格说明:混合了多种助手风格。许多数学/科学数据行使用 Qwen 风格的
</think> … </think>思考链格式;逻辑/代码类数据则常为普通答案格式。使用时需匹配基座模型的聊天模板和思考策略。
相关资源链接
- SFT 模型示例:https://huggingface.co/96kevinli29/Qwen3-4B-SFT
- 训练代码仓库:https://github.com/96kevinli29/base-model-sft-verl
- 建议基座模型:https://huggingface.co/Qwen/Qwen3-4B-Base
引用信息
如需使用此数据集,请引用本数据集及所依赖的每个上游数据源。 bibtex @misc{dataset-sft-math-2025, title = {{SFT-Dataset}: Mixed High-Difficulty Corpus for Reasoning SFT}, author = {Hongyang Li and Xiao Li and {Sea-Fill Community}}, year = {2026}, publisher = {Hugging Face}, howpublished = {url{https://huggingface.co/datasets/SeaFill2025/SFT-Dataset}}, note = {Recipe ~50/30/10/10 with strict QC. Part of the Sea-Fill initiative to ensure LLMs are both powerful and safe.} }
搜集汇总
数据集介绍
构建方式
在构建高质量监督微调数据集的过程中,SFT-Dataset采用了一种精心设计的混合策略,从多个权威上游数据源中筛选并整合了特定数量的样本。该数据集主要融合了OpenR1-Math-220k、NuminaMath-CoT、Magpie-Llama-3.1-Pro-300K-Filtered、CodeFeedback-Filtered-Instruction以及ScienceQA等核心资源,并辅以内部构建的GPQA对齐科学片段,最终形成了约五万个训练样本与一千个测试样本的平衡结构。每个样本均标注了来源与类别,确保了数据构成的透明性与可追溯性。
特点
SFT-Dataset的显著特征在于其均衡的领域覆盖与高质量的样本内容,专为提升基础模型在数学推理、代码生成及科学问答等复杂任务上的性能而设计。数据集不仅包含了大量需要多步推理的数学与科学问题,还融入了经过严格筛选的代码反馈与逻辑分析实例,整体难度较高。在格式上,数据集支持多样化的助手风格,部分数学与科学样本采用了带有思维链标记的结构化表达,而代码与逻辑类样本则常以简洁答案呈现,这种混合风格为模型适应不同的输出模式提供了丰富的训练素材。
使用方法
使用SFT-Dataset进行模型微调时,建议首先根据所选基础模型的对话模板与思维策略对数据格式进行适配,例如确保带有`</think>`标记的思维链样本能够被正确处理。数据集以Parquet格式提供,可直接加载至主流深度学习框架中进行训练。典型的应用流程包括利用训练集对如Qwen3-4B-Base等基础模型进行监督微调,以构建一个性能稳健的策略模型,为后续可能的强化学习阶段奠定基础。用户需注意遵守各上游数据源的许可协议,并在相关研究中引用本数据集及所依赖的原始数据。
背景与挑战
背景概述
在大型语言模型(LLM)的演进历程中,监督微调(SFT)是提升模型在特定任务上表现的关键环节。SFT-Dataset由Sea-Fill社区的研究人员于2026年构建,旨在为开源基础模型如Qwen3-4B-Base提供一套高质量、平衡的微调数据配方。该数据集聚焦于数学推理、代码生成及科学问答等高难度认知领域,其核心研究问题在于如何通过精心配比的多源数据,有效激发模型在复杂逻辑任务上的泛化能力,为后续的强化学习阶段奠定坚实基础,从而推动开源模型在专业领域应用的深度与安全性。
当前挑战
该数据集致力于解决高难度推理任务的监督微调挑战,其核心在于如何让模型在数学、代码和科学等需要严谨逻辑的领域,生成准确且可靠的响应。构建过程中的挑战尤为显著,首先需要从多个异构上游数据源(如OpenR1-Math、NuminaMath-CoT等)进行严格筛选与整合,确保数据在数量、质量与领域分布上达到平衡。其次,不同数据源在格式与风格上存在差异,例如部分数学问题采用特定的思维链标记,而代码问题则多为直接回答,这要求构建过程需进行细致的规范化处理,以适配目标基础模型的对话模板与推理策略。
常用场景
经典使用场景
在大型语言模型的监督微调领域,SFT-Dataset以其精心设计的混合配方脱颖而出,专为提升模型在数学推理、代码生成和科学问答等高难度任务上的性能而构建。该数据集通过整合OpenR1-Math-220k、NuminaMath-CoT等高质量来源,为基座模型如Qwen/Qwen3-4B-Base提供了均衡且富有挑战性的训练样本,旨在优化模型在复杂逻辑和分步思考方面的能力,为后续强化学习奠定坚实基础。
实际应用
在实际部署中,基于SFT-Dataset微调的模型可广泛应用于教育辅助、科研工具和软件开发等场景。例如,在智能辅导系统中,模型能够解析复杂的数学问题并提供清晰的解题步骤;在科研领域,它可协助研究人员快速理解科学文献并生成逻辑严谨的问答;在编程环境中,模型能有效识别代码错误并提供优化建议,显著提升开发效率与代码质量。
衍生相关工作
围绕SFT-Dataset已衍生出多项经典研究工作,其中最直接的应用体现在Qwen3-4B-SFT模型的训练上,该模型展示了在数学和代码基准测试中的优异表现。此外,基于该数据集构建的微调框架如base-model-sft-verl,为社区提供了可扩展的训练范例,进一步激发了在混合数据配方、多任务学习以及安全对齐等领域的研究探索,推动了开源模型在专业能力上的持续进化。
以上内容由遇见数据集搜集并总结生成


