Torch-Trade/btc-reasoning-traces-05_2021-05_2022-gemma4-31B
收藏Hugging Face2026-04-10 更新2026-04-12 收录
下载链接:
https://hf-mirror.com/datasets/Torch-Trade/btc-reasoning-traces-05_2021-05_2022-gemma4-31B
下载链接
链接失效反馈官方服务:
资源简介:
---
license: mit
task_categories:
- reinforcement-learning
tags:
- trading
- reasoning-traces
- llm
- bitcoin
- torchtrade
- gemma-4
- nvfp4
size_categories:
- 1K<n<10K
---
# BTC Reasoning Traces: Gemma 4 31B (May 2021 - May 2022)
LLM reasoning traces for BTC/USD hourly trading decisions, generated by
**nvidia/Gemma-4-31B-IT-NVFP4** running locally on a DGX Spark via vLLM.
Each row is one hourly trading decision with full chain-of-thought reasoning.
## Generation
| Field | Value |
|---|---|
| Teacher model | `nvidia/Gemma-4-31B-IT-NVFP4` (30.7B params, NVFP4 quantized) |
| Inference engine | vLLM 0.19.1 on DGX Spark (128GB unified memory, GB10) |
| Temperature | 0.6 |
| Prompt format | Compact (delta-encoded OHLCV, ~400 tokens/prompt) |
| Batch size | 64 parallel episodes |
| Throughput | ~370-390 tok/s |
| Total traces | 8,928 |
| Valid action rate | 100.0% |
## Data coverage
**8,928 hourly trading decisions** covering ~1 year of BTC/USD perpetual futures:
| Period | Date range (UTC) |
|---|---|
| Start | 2021-05-01T00:00:00 |
| End | 2022-05-07T23:00:00 |
Source data: [`Torch-Trade/btcusdt_perp_1m_05_2021_to_02_2026`](https://huggingface.co/datasets/Torch-Trade/btcusdt_perp_1m_05_2021_to_02_2026)
## Environment configuration
| Parameter | Value |
|---|---|
| Symbol | BTC/USD |
| Execution timeframe | 1Hour (decisions every hour) |
| Action space | `[-1, 0, 1]` (short / flat / long) |
| Leverage | 3x |
| Initial cash | $10,000 |
| Observation | 12-bar 5min + 24-bar 1hour OHLCV (compact delta-encoded) |
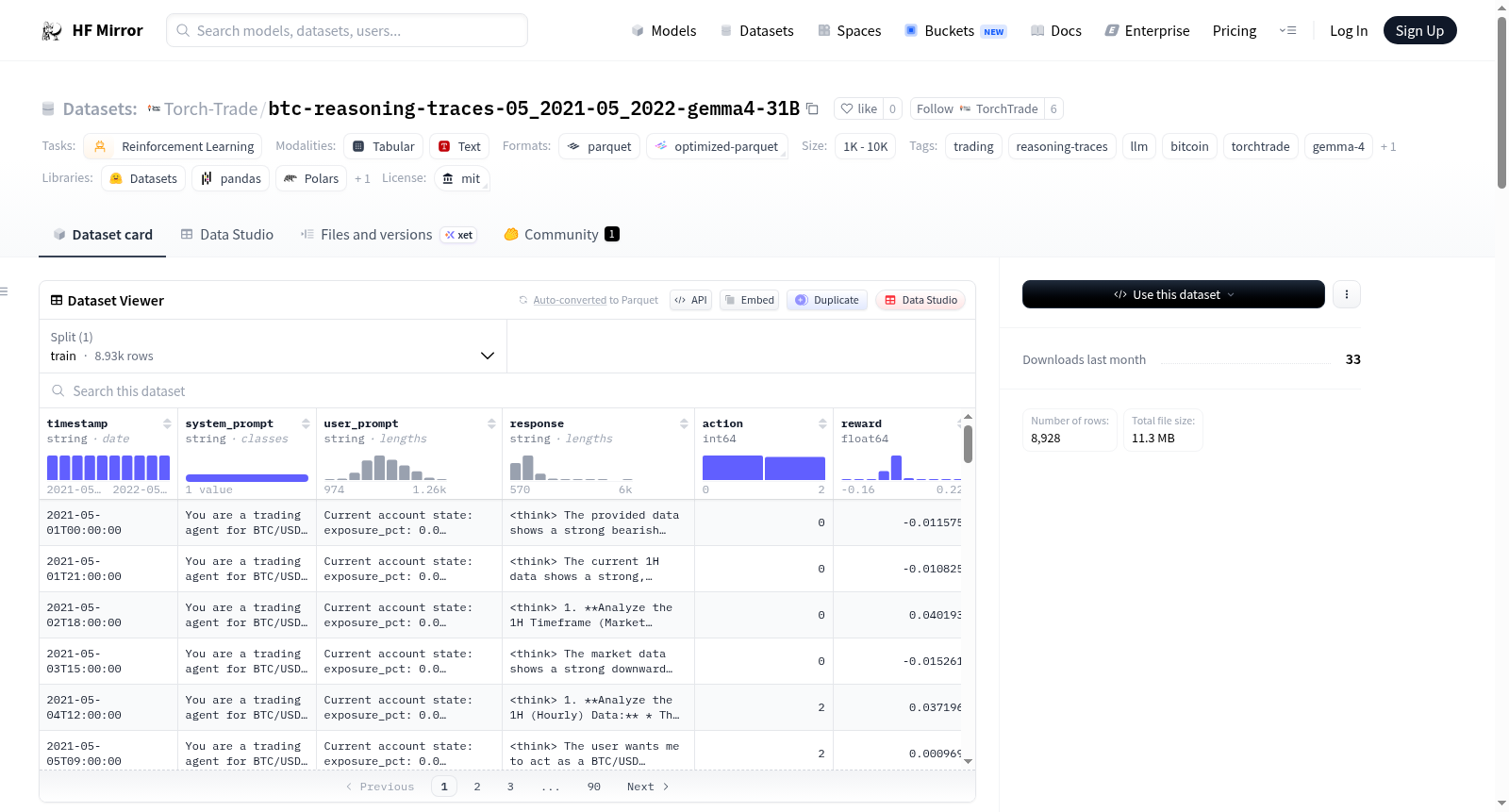
## Action distribution
| Action | Count | Pct |
|---|---|---|
| 0 (short) | 4,592 | 51.4% |
| 1 (flat) | 1,080 | 12.1% |
| 2 (long) | 3,256 | 36.5% |
## Columns
| Column | Type | Description |
|---|---|---|
| `timestamp` | string | ISO timestamp of the trading decision |
| `system_prompt` | string | System instructions for the trading agent |
| `user_prompt` | string | Compact delta-encoded OHLCV data + account state |
| `response` | string | Full `<think>reasoning</think><answer>N</answer>` output |
| `action` | int | Extracted action (0=short, 1=flat, 2=long) |
| `reward` | float | Reward received after taking the action |
## Usage
```python
from datasets import load_dataset
ds = load_dataset("Torch-Trade/btc-reasoning-traces-05_2021-05_2022-gemma4-31B")
# Browse a reasoning trace
row = ds["train"][42]
print(row["response"])
# For SFT training: build messages
def to_messages(row):
return {"messages": [
{"role": "system", "content": row["system_prompt"]},
{"role": "user", "content": row["user_prompt"]},
{"role": "assistant", "content": row["response"]},
]}
sft_ds = ds["train"].map(to_messages)
```
## Generated by
[TorchTrade](https://github.com/TorchTrade/torchtrade) using `generate_traces_local.py` with batched vLLM inference on DGX Spark.
提供机构:
Torch-Trade
搜集汇总
数据集介绍
构建方式
在量化金融与强化学习交叉领域,数据集的构建往往依赖于高质量的市场数据与先进的大语言模型推理能力。本数据集通过部署nvidia/Gemma-4-31B-IT-NVFP4模型,在DGX Spark硬件上利用vLLM推理引擎批量生成。采用温度参数0.6与紧凑型增量编码的OHLCV数据,以每小时为频率模拟交易决策,最终汇集了8,928条完整的思维链推理轨迹,确保了决策过程的透明性与可复现性。
使用方法
研究者可通过Hugging Face datasets库直接加载数据集,便捷访问每条记录的时间戳、提示信息与模型响应。数据集支持转换为标准对话格式,适用于监督微调任务,助力于训练具备链式思维能力的交易智能体。用户可依据行动分布与奖励信号进行策略分析,或利用紧凑编码的市场数据复现与扩展交易决策实验。
背景与挑战
背景概述
在量化金融与强化学习交叉领域,基于大语言模型的决策推理轨迹数据集正成为研究热点。btc-reasoning-traces-05_2021-05_2022-gemma4-31B数据集由TorchTrade团队于2024年构建,旨在探索大语言模型在加密货币高频交易中的链式思维决策能力。该数据集覆盖了2021年5月至2022年5月间BTC/USD永续合约的小时级交易决策,通过Gemma-4-31B模型生成包含完整推理过程的轨迹,为研究金融时序决策的透明化与可解释性提供了重要实验基础。其核心研究问题聚焦于大语言模型能否在复杂市场环境中实现稳健的量化策略生成,对推动人工智能在金融工程领域的应用具有显著影响力。
当前挑战
该数据集致力于解决金融时序决策中策略生成与可解释性协同优化的挑战,其核心难点在于如何让大语言模型在高度非线性的市场波动中保持决策逻辑的一致性。构建过程中面临多重技术障碍:一是需要设计紧凑的增量编码方法将高维OHLCV数据压缩至约400个令牌以内,以适配模型上下文长度限制;二是需通过并行化推理技术处理近九千条轨迹生成任务,在保证100%有效动作率的同时维持每小时370-390令牌的生成吞吐量;三是必须精确构建包含账户状态、市场观测与风险杠杆的多维度交互环境,以模拟真实交易场景的复杂性。
常用场景
经典使用场景
在量化金融与强化学习交叉领域,该数据集为研究基于大语言模型的交易决策机制提供了宝贵资源。其核心应用场景在于模拟比特币每小时交易环境,通过Gemma 4 31B模型生成的思维链轨迹,完整记录了从市场数据输入到最终交易动作的推理过程。研究者可借此深入分析模型在复杂金融时序数据下的决策逻辑,探索如何将自然语言推理能力迁移至结构化交易任务中,为构建可解释的自动化交易系统奠定基础。
解决学术问题
该数据集有效应对了金融人工智能领域若干关键挑战。它通过大规模、高质量的思维链标注,解决了交易决策中黑箱模型缺乏可解释性的学术难题。数据集涵盖一年期高频市场数据,为研究模型在波动市场中的稳健性提供了实证基础。其结构化轨迹支持对多步推理、风险感知与时序依赖建模的深入分析,推动了将大语言模型应用于序列决策任务的理论框架发展,并促进了强化学习与自然语言处理在金融领域的跨学科融合。
实际应用
在实际金融科技应用中,该数据集可直接服务于算法交易系统的开发与优化。交易机构可利用这些轨迹数据对专用模型进行监督微调,构建具备理性推理能力的交易代理。其紧凑的增量编码格式与完整的状态-动作-奖励记录,为回测系统提供了标准化输入,支持对3倍杠杆下多空策略的绩效评估。此外,轨迹中蕴含的市场认知模式可用于风险控制模块的训练,提升自动化交易系统在真实市场环境中的适应性与稳定性。
数据集最近研究
最新研究方向
在金融交易智能化领域,大型语言模型(LLM)的推理轨迹数据集正成为研究焦点。该数据集通过Gemma 4 31B模型生成的BTC/USD小时级交易决策链式思考记录,为探索LLM在量化交易中的可解释性提供了珍贵资源。当前前沿研究集中于利用此类轨迹进行监督微调(SFT),以提升模型在动态市场环境中的决策一致性,并分析其与强化学习框架的融合潜力。相关热点事件包括NVFP4量化技术在高频推理中的应用,以及vLLM引擎在分布式计算环境下对多周期金融时序数据的处理突破。这些进展不仅推动了算法交易策略的透明化,也为构建具备因果推理能力的自主交易智能体奠定了数据基础,对金融科技领域的模型可信度与风险控制研究具有深远意义。
以上内容由遇见数据集搜集并总结生成


