Deepseek-v4-pro-max-distill-1000x
收藏Hugging Face2026-04-27 更新2026-04-28 收录
下载链接:
https://huggingface.co/datasets/beyoru/Deepseek-v4-pro-max-distill-1000x
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含由DeepSeek-V4-Pro生成的推理轨迹和最终答案,使用了从Jackrong/GLM-5.1-Reasoning-1M-Cleaned数据集中采样的提示。数据集的目标是检查质量,共有1000个样本,生成于2026年4月27日,成本约为5.46美元。数据集适用于蒸馏任务,因为DeepSeek-V4-Pro能够返回完整的推理链(CoT),这对于训练学生模型以复制教师的推理行为至关重要。数据集主要包含英语内容,也有一些中文/多语言STEM内容。数据格式为JSON Lines(output.jsonl),每个JSON对象包含id、domain、prompt、reasoning、response、model和usage等字段。
创建时间:
2026-04-24
原始信息汇总
数据集概述
本数据集由 DeepSeek-V4-Pro 模型生成,包含推理轨迹和最终答案。数据集的目标是用于质量检查,并探索知识蒸馏(Distillation)方法。其设计理念是:教师模型必须暴露完整的思维链(Chain-of-Thought)以供学生模型学习。
核心信息
- 数据集名称:Deepseek-v4-pro-max-distill-1000x
- 许可证:Apache-2.0
- 语言:主要为英语,包含部分中文及多语言STEM内容
- 任务类别:文本生成(Text Generation)
- 标签:推理(Reasoning)、蒸馏(Distillation)、思维链(Chain-of-Thought)、DeepSeek、合成数据(Synthetic)、DeepSeek-V4-Pro
- 数据集规模:小于 1K 样本
数据来源与生成
- 提示词来源:从
Jackrong/GLM-5.1-Reasoning-1M-Cleaned数据集的训练集(trainsplit)中采样。 - 教师模型:
deepseek-v4-pro,配置要求为reasoning_effort=max且thinking.enabled=true。 - 选择DeepSeek的原因:DeepSeek-V4-Pro 返回完整的思维链(Full CoT)。相比之下,OpenAI 和 Gemini 等模型仅返回摘要(Summary),不适用于需要完整推理轨迹作为监督信号的蒸馏任务。
数据统计(Dataset Statistics)
| 字段 | 值 |
|---|---|
| 样本数量 | 1000 |
| 提示词来源 | Jackrong/GLM-5.1-Reasoning-1M-Cleaned,train 集 |
| 教师模型 | deepseek-v4-pro |
| 推理努力度 | max |
| 语言 | 主要为英语,包含部分中文 / 多语言STEM内容 |
| 数据格式 | JSON Lines(output.jsonl) |
数据模式(Schema)
每行数据是一个 JSON 对象,包含以下字段:
| 字段 | 类型 | 描述 |
|---|---|---|
id |
string | 原始数据集的 MD5 哈希值 |
domain |
string | 来源子集:main / PHD-Science / Multilingual-STEM / Math |
prompt |
string | 用户提示词(来自源数据集的 input 字段) |
reasoning |
string | DeepSeek 生成的思维链(message.reasoning_content) |
response |
string | 最终答案(message.content) |
model |
string | deepseek-v4-pro |
usage |
object | Token 用量(包含 prompt_tokens, completion_tokens, reasoning_tokens 等) |
其他信息
- 更新日期:2026年4月27日,数据集已完整包含1000个样本,成本约为5.46美元。
- 规划内容:计划尝试其他蒸馏风格,例如角色扮演(Roleplay)。
搜集汇总
数据集介绍
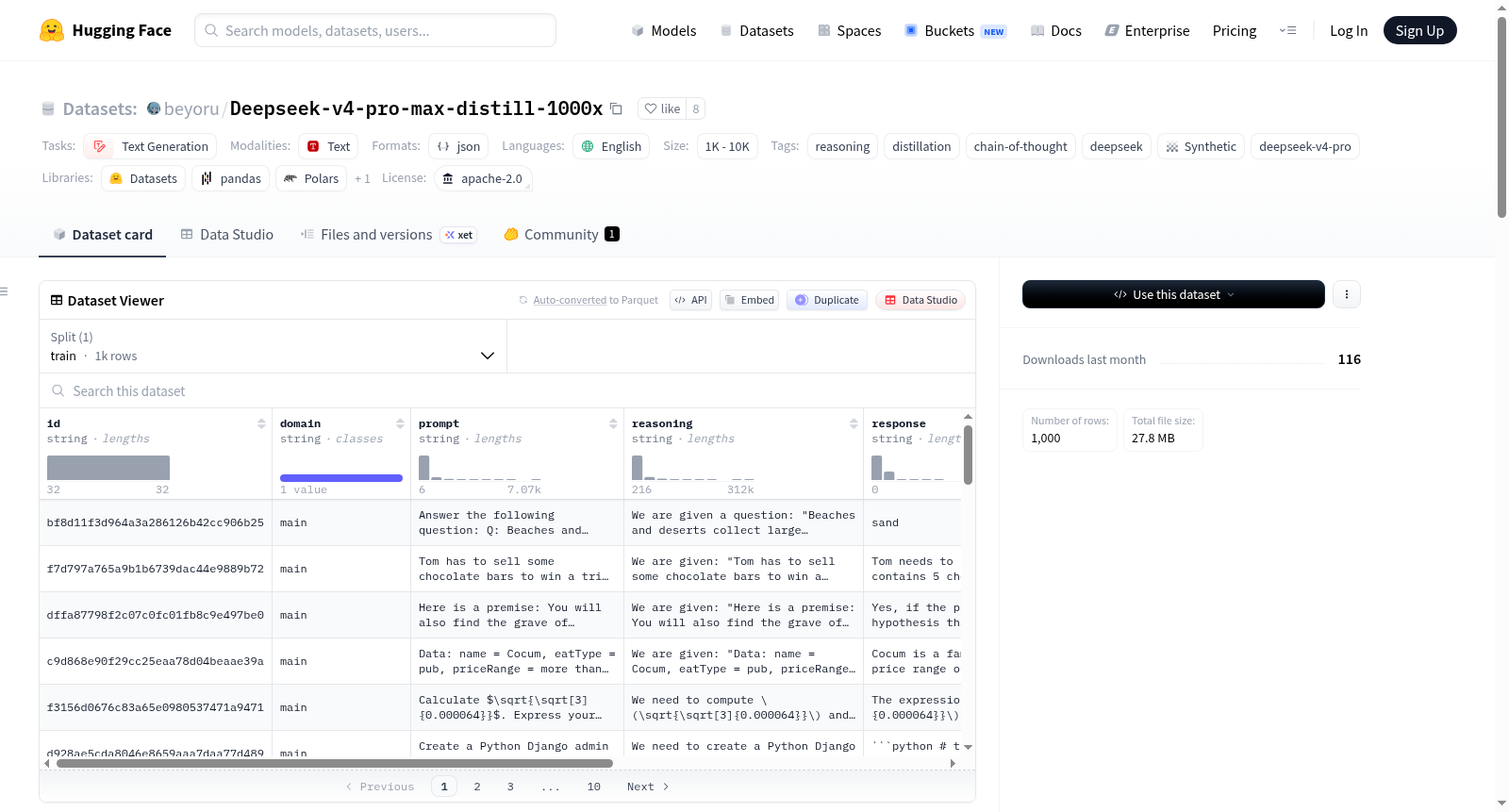
构建方式
本数据集基于DeepSeek-V4-Pro模型构建,采用知识蒸馏范式,以Jackrong/GLM-5.1-Reasoning-1M-Cleaned数据集中的提示词为输入,通过设置最大推理强度(reasoning_effort=max)并启用思考机制(thinking.enabled=true),完整捕获模型的链式推理过程与最终答案。每条样本记录原始提示词、模型生成的完整推理链路、最终回复以及令牌消耗等元信息,最终以JSON Lines格式存储,共计1000条样本。
特点
该数据集的核心特色在于保留了教师模型完整的思维链(Chain-of-Thought),而非摘要性总结,这使其尤其适用于推理蒸馏任务。相较于OpenAI和Gemini等隐藏原始推理过程的模型,DeepSeek-V4-Pro公开了全部推理内容,为学生模型模仿教师的推理行为提供了直接监督信号。数据覆盖英语及部分多语言STEM领域内容,涵盖主数据集、博士级科学、多语言STEM和数学等多个子领域。
使用方法
数据集以JSON Lines格式提供,每行包含唯一标识符、领域标签、提示词、推理过程、最终答案及令牌使用统计。使用时可直接加载为JSON对象列表,以prompt字段作为学生模型的输入,以reasoning和response字段分别作为推理过程与最终答案的监督目标。建议用于训练需要显式推理能力的语言模型,支持基于链式推理的微调与蒸馏实验。
背景与挑战
背景概述
在大型语言模型(LLM)的快速发展进程中,知识蒸馏作为一种高效模型压缩与能力迁移技术,正日益成为研究焦点。Deepseek-v4-pro-max-distill-1000x数据集应运而生,由研究人员于2026年4月27日构建完成,旨在检验基于DeepSeek-V4-Pro模型的高质量推理轨迹蒸馏效果。该数据集的核心研究问题在于探索如何利用具备完整思维链(CoT)输出的教师模型,为训练学生模型提供监督信号,从而复现复杂的推理行为。这一数据集填补了当前许多主流模型(如OpenAI、Gemini)因隐藏原始CoT而无法用于高效蒸馏的空白,对推动开源可复现的推理能力蒸馏研究具有重要影响力。
当前挑战
该数据集所解决的领域挑战主要源于当前主流闭源推理模型(如OpenAI o1/o3、GPT-5)仅返回推理过程的摘要,而非完整的思维链(CoT),导致无法直接用于监督式的推理蒸馏训练。学生模型需要学习完整的“推理→回答”映射,隐藏的CoT实质阻碍了推理能力的透明迁移。在构建过程中,数据集面临的主要挑战包括:确保采样提示来源(源自GLM-5.1-Reasoning-1M-Cleaned)的多样性与平衡性,覆盖多个领域(主领域、PHD-Science、Multilingual-STEM、Math);控制高推理成本(max推理努力)下的预算限制,最终以仅约5.46美元完成1000条高质量样本的生成;以及后续还需探索不同蒸馏风格(如角色扮演)以提升学生模型的泛化表现。
常用场景
经典使用场景
该数据集被精心构建以服务于大语言模型推理能力的蒸馏训练任务。其核心用途在于提供由顶尖推理模型DeepSeek-V4-Pro生成的完整思维链与最终答案,作为教师信号,用以训练参数量较小的学生模型。研究者可基于此数据集,通过监督学习范式,使学生模型习得长链推理的中间步骤与逻辑结构,从而在保持较低计算成本的前提下,有效提升模型的复杂问题求解能力。
衍生相关工作
该数据集的出现有望催生一系列关于推理蒸馏策略的经典工作。后续研究可基于此探索不同的蒸馏范式,如角色扮演蒸馏或对抗性蒸馏,验证完整思维链作为信号的有效性。该数据集也可用于比较不同教师模型(如DeepSeek-V4-Pro与其它开放模型)对蒸馏效果的影响,推动蒸馏算法的理论发展。此外,研究者可进一步分析推理步骤的长短与最终答案质量之间的关联,为构建更高效、更可控的推理模型奠定数据基础。
数据集最近研究
最新研究方向
基于思维链蒸馏的高效推理模型构建。当前前沿研究聚焦于利用下一代推理模型如DeepSeek-V4-Pro显式输出的完整思维链作为监督信号,替代OpenAI与Gemini等仅提供推理摘要的封闭范式,从而蒸馏出可复现教师推演逻辑的轻量学生模型。该数据集以极低成本(约5.46美元)合成1000条高质推理轨迹,覆盖多语言STEM及数学领域,为知识蒸馏提供了透明、完整的推理-响应对齐样本,标志着模型小型化与推理能力迁移的研究重心正从黑盒提炼转向可解释的链式思维复刻,对降低大模型部署门槛、推动透明化自学推理具有里程碑意义。
以上内容由遇见数据集搜集并总结生成


