sentimento-gl
收藏Hugging Face2025-12-12 更新2025-12-13 收录
下载链接:
https://huggingface.co/datasets/proxectonos/sentimento-gl
下载链接
链接失效反馈官方服务:
资源简介:
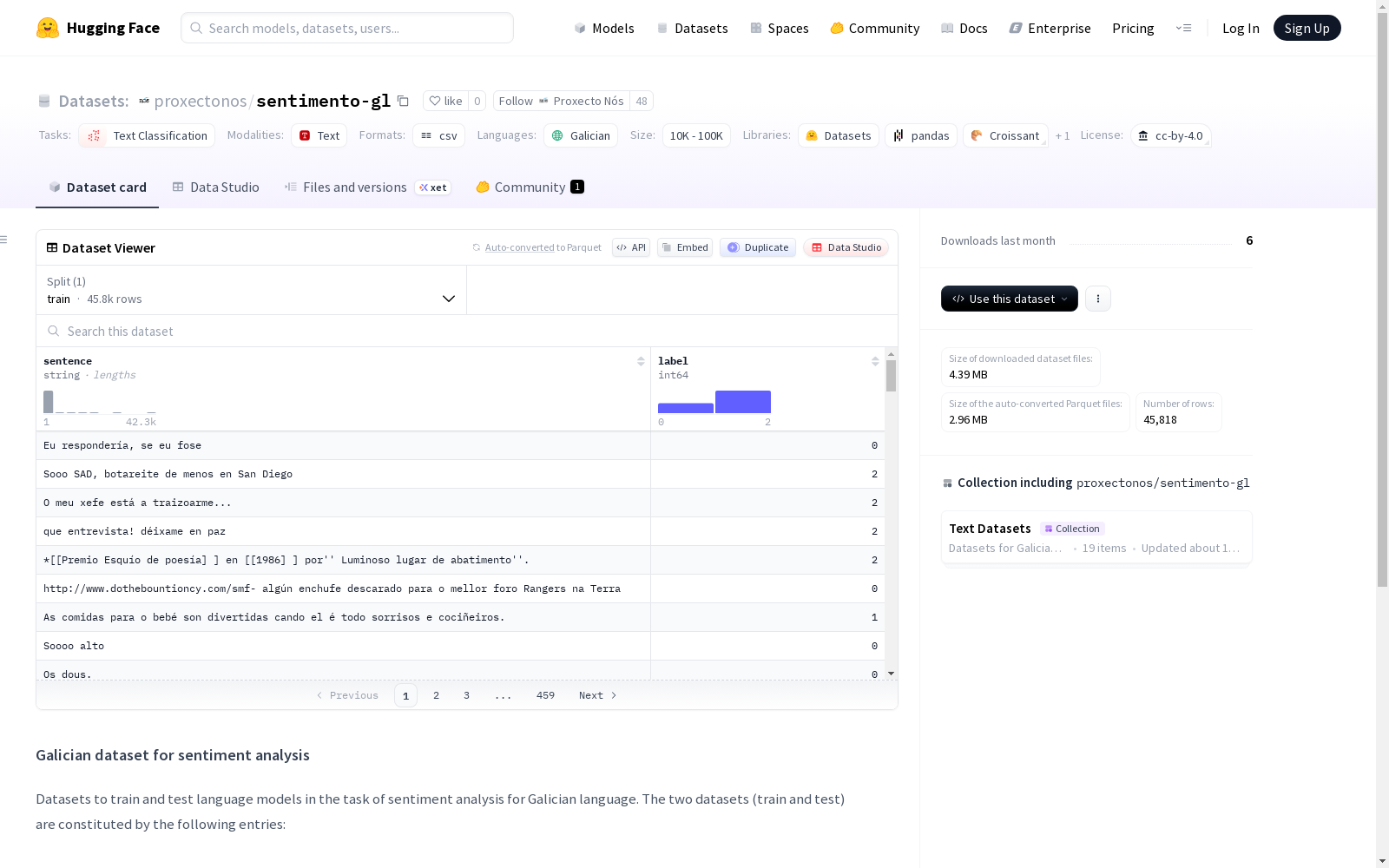
用于加利西亚语情感分析的数据集,旨在训练和测试语言模型。数据集包含训练集和测试集,具体构成如下:训练集包含45,818条数据(正例15,610条,中性14,034条,负例16,174条),测试集包含998条数据(正例424条,中性224条,负例350条)。
This dataset is designed for Galician sentiment analysis, aiming to train and test language models. It consists of a training set and a test set, with their specific compositions as follows: The training set contains 45,818 samples, including 15,610 positive samples, 14,034 neutral samples and 16,174 negative samples. The test set has 998 samples, with 424 positive samples, 224 neutral samples and 350 negative samples.
创建时间:
2025-12-11
原始信息汇总
数据集概述
基本信息
- 数据集名称: Galician dataset for sentiment analysis
- 托管平台: Hugging Face
- 页面地址: https://huggingface.co/datasets/proxectonos/sentimento-gl
- 许可证: CC BY 4.0
- 主要任务类别: 文本分类
- 语言: 加利西亚语 (gl)
数据集内容与结构
该数据集用于训练和测试加利西亚语情感分析任务的语言模型。数据集包含两个部分:训练集和测试集。
数据规模与分布
| 数据集 | 正面 (Positive) | 中性 (Neutral) | 负面 (Negative) | 总计 |
|---|---|---|---|---|
| 训练集 | 15,610 | 14,034 | 16,174 | 45,818 |
| 测试集 | 424 | 224 | 350 | 998 |
引用信息
- 文献标题: Evaluating Galician language models for sentiment analysis on challenging linguistic phenomena
- 作者: Alonso, Anxo, Pablo Gamallo
- 出版年份: 2025
- 期刊: Procesamiento del Lenguaje Natural
- 卷期: 74
- 页码: 191-205
- ISSN: 1135-5948
搜集汇总
数据集介绍
构建方式
在情感分析领域,针对加利西亚语这类资源相对稀缺的语言,构建高质量数据集显得尤为重要。sentimento-gl数据集的构建过程体现了严谨的学术方法,其训练集与测试集均来源于精心筛选的文本语料,并进行了人工或半自动的情感极性标注。数据划分遵循机器学习标准实践,确保了模型训练与评估的有效性。整个构建流程旨在为加利西亚语的情感分析任务提供一个可靠且平衡的基准资源。
特点
该数据集的核心特点在于其专门服务于加利西亚语的情感分析研究,有效填补了该语言在此领域的资源空白。从数据构成来看,训练集与测试集在积极、中性和消极三种情感类别上分布较为均衡,例如训练集总计45,818条样本,三类数据量相近,这有助于训练出对不同情感倾向均具有判别能力的模型。测试集包含998条样本,为模型性能提供了独立的评估基准。数据集整体规模适中,兼具实用性与可管理性。
使用方法
使用sentimento-gl数据集时,研究者可遵循标准的文本分类工作流程。通常,将提供的训练集用于模型训练,并通过测试集评估其情感分类的准确率、F1值等性能指标。该数据集可直接用于微调预训练的加利西亚语语言模型,或作为基准测试集,用于比较不同模型架构或训练策略在该语言情感分析任务上的效果。引用相关文献时,请遵循提供的标准引文格式,以确保学术规范性。
背景与挑战
背景概述
在自然语言处理领域,情感分析作为一项基础任务,旨在通过计算模型自动识别文本中蕴含的情感倾向。然而,针对低资源语言如加利西亚语的研究长期面临数据稀缺的困境。Sentimento-GL数据集由Anxo Alonso和Pablo Gamallo于2025年创建,旨在为加利西亚语提供高质量的情感分析标注数据。该数据集包含训练集与测试集,总计超过四万六千条样本,涵盖积极、中立与消极三类情感标签,为加利西亚语语言模型的训练与评估奠定了重要基础,推动了该语言在情感计算方向的发展。
当前挑战
Sentimento-GL数据集所解决的核心领域问题是加利西亚语的情感分析任务,其挑战在于低资源语言中标注数据的匮乏,以及语言特有的语法结构和文化语境对情感表达的微妙影响。在构建过程中,研究人员需克服加利西亚语数字文本资源有限、标注一致性难以保证,以及平衡不同情感类别样本分布等难题。这些挑战不仅考验数据收集与标注的严谨性,也对后续模型在复杂语言现象上的泛化能力提出了更高要求。
常用场景
经典使用场景
在自然语言处理领域,针对低资源语言的情感分析研究常面临数据稀缺的挑战。Sentimento-GL作为加利西亚语的情感分析数据集,其经典使用场景在于为这一语言构建和评估情感分类模型。研究者利用该数据集训练机器学习或深度学习模型,以自动识别文本中的积极、中性或消极情感倾向,从而推动加利西亚语在情感计算方向的发展。
解决学术问题
该数据集有效解决了加利西亚语在情感分析任务中缺乏标准化基准的问题。通过提供大规模、标注平衡的训练和测试数据,它支持了跨语言模型性能比较、低资源语言处理技术验证以及语言特定现象(如方言变体或文化语境)对情感表达影响的研究。这为探索语言多样性在自然语言处理中的角色提供了实证基础。
衍生相关工作
基于Sentimento-GL,研究者已开展多项经典工作,包括开发针对加利西亚语的预训练语言模型(如基于BERT的变体)、探索跨语言迁移学习策略以提升低资源语言情感分析性能,以及评估模型在复杂语言现象(如讽刺或模糊表达)上的鲁棒性。这些工作进一步丰富了多语言自然语言处理的研究生态。
以上内容由遇见数据集搜集并总结生成


