wanglab/protein_catalogue
收藏Hugging Face2026-04-01 更新2026-04-05 收录
下载链接:
https://hf-mirror.com/datasets/wanglab/protein_catalogue
下载链接
链接失效反馈官方服务:
资源简介:
---
license: apache-2.0
language:
- en
tags:
- protein
- gene-ontology
- function-prediction
- biology
- bioinformatics
- reasoning
datasets:
- wanglab/bioreason-pro-sft-reasoning-data
---
<h1 align="center">
🧬 BioReason-Pro Protein Catalogue<br>Functional Annotations for 223K+ Proteins
</h1>
<p align="center">
<a href="https://www.biorxiv.org/content/10.64898/2026.03.19.712954v1" target="_blank"><img src="https://img.shields.io/badge/bioRxiv-2026.03.19.712954-FF6B6B?style=for-the-badge&logo=arxiv&logoColor=white" alt="bioRxiv"></a>
<a href="https://github.com/bowang-lab/BioReason-Pro"><img src="https://img.shields.io/badge/GitHub-Code-4A90E2?style=for-the-badge&logo=github&logoColor=white" alt="GitHub"></a>
<a href="https://bioreason.net"><img src="https://img.shields.io/badge/Website-Online-00B89E?style=for-the-badge&logo=internet-explorer&logoColor=white" alt="Website"></a>
<a href="https://huggingface.co/collections/wanglab/bioreason-pro"><img src="https://img.shields.io/badge/HuggingFace-Models & Data-FFBF00?style=for-the-badge&logo=huggingface&logoColor=white" alt="HuggingFace"></a>
</p>
<br>
## Overview
Pre-computed functional annotations for over 223,000 proteins generated by [BioReason-Pro SFT](https://huggingface.co/wanglab/bioreason-pro-sft). Each entry contains a structured reasoning trace, functional summary, UniProt summary, InterPro domain annotations, and Gene Ontology (GO) term predictions across molecular function, biological process, and cellular component.
Browse the catalogue interactively at [bioreason.net](https://bioreason.net).
## Dataset Structure
| Column | Type | Description |
|--------|------|-------------|
| `protein_id` | string | Protein identifier (e.g. UniProt accession) |
| `protein` | string | Amino acid sequence |
| `organism` | string | Source organism |
| `model` | string | Model used to generate the annotation (e.g. `SFT`) |
| `generation` | string | Full model output including `<think>` reasoning trace and structured functional annotations |
### Generation Format
The `generation` column contains the raw model output in the following structure:
```
<think>
[Detailed biological reasoning trace]
</think>
- Functional Summary: [Concise functional description]
- UniProt Summary: [Brief UniProt-style summary]
- InterPro:
- IPR000000: Domain name (type) [start-end]
- Molecular Function:
- GO:0000000 function name
- Biological Process:
- GO:0000000 process name
- Cellular Component:
- GO:0000000 component name
```
## Usage
```python
from datasets import load_dataset
ds = load_dataset("wanglab/protein_catalogue", split="train")
print(ds[0])
```
## See Also
- [BioReason-Pro SFT](https://huggingface.co/wanglab/bioreason-pro-sft) — supervised fine-tuned model
- [BioReason-Pro RL](https://huggingface.co/wanglab/bioreason-pro-rl) — reinforcement learning optimized checkpoint
- [GO-GPT](https://huggingface.co/wanglab/gogpt) — autoregressive GO term predictor
- [SFT Reasoning Data](https://huggingface.co/datasets/wanglab/bioreason-pro-sft-reasoning-data) — training data
## Citation
If you find this work useful, please cite our papers:
```bibtex
@article {Fallahpour2026.03.19.712954,
author = {Fallahpour, Adibvafa and Seyed-Ahmadi, Arman and Idehpour, Parsa and Ibrahim, Omar and Gupta, Purav and Naimer, Jack and Zhu, Kevin and Shah, Arnav and Ma, Shihao and Adduri, Abhinav and G{\"u}loglu, Talu and Liu, Nuo and Cui, Haotian and Jain, Arihant and de Castro, Max and Fallahpour, Amirfaham and Cembellin-Prieto, Antonio and Stiles, John S. and Nem{\v c}ko, Filip and Nevue, Alexander A. and Moon, Hyungseok C. and Sosnick, Lucas and Markham, Olivia and Duan, Haonan and Lee, Michelle Y. Y. and Salvador, Andrea F. M. and Maddison, Chris J. and Thaiss, Christoph A. and Ricci-Tam, Chiara and Plosky, Brian S. and Burke, Dave P. and Hsu, Patrick D. and Goodarzi, Hani and Wang, Bo},
title = {BioReason-Pro: Advancing Protein Function Prediction with Multimodal Biological Reasoning},
elocation-id = {2026.03.19.712954},
year = {2026},
doi = {10.64898/2026.03.19.712954},
publisher = {Cold Spring Harbor Laboratory},
URL = {https://www.biorxiv.org/content/early/2026/03/20/2026.03.19.712954},
eprint = {https://www.biorxiv.org/content/early/2026/03/20/2026.03.19.712954.full.pdf},
journal = {bioRxiv}
}
@misc{fallahpour2025bioreasonincentivizingmultimodalbiological,
title={BioReason: Incentivizing Multimodal Biological Reasoning within a DNA-LLM Model},
author={Adibvafa Fallahpour and Andrew Magnuson and Purav Gupta and Shihao Ma and Jack Naimer and Arnav Shah and Haonan Duan and Omar Ibrahim and Hani Goodarzi and Chris J. Maddison and Bo Wang},
year={2025},
eprint={2505.23579},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2505.23579},
}
```
提供机构:
wanglab
搜集汇总
数据集介绍
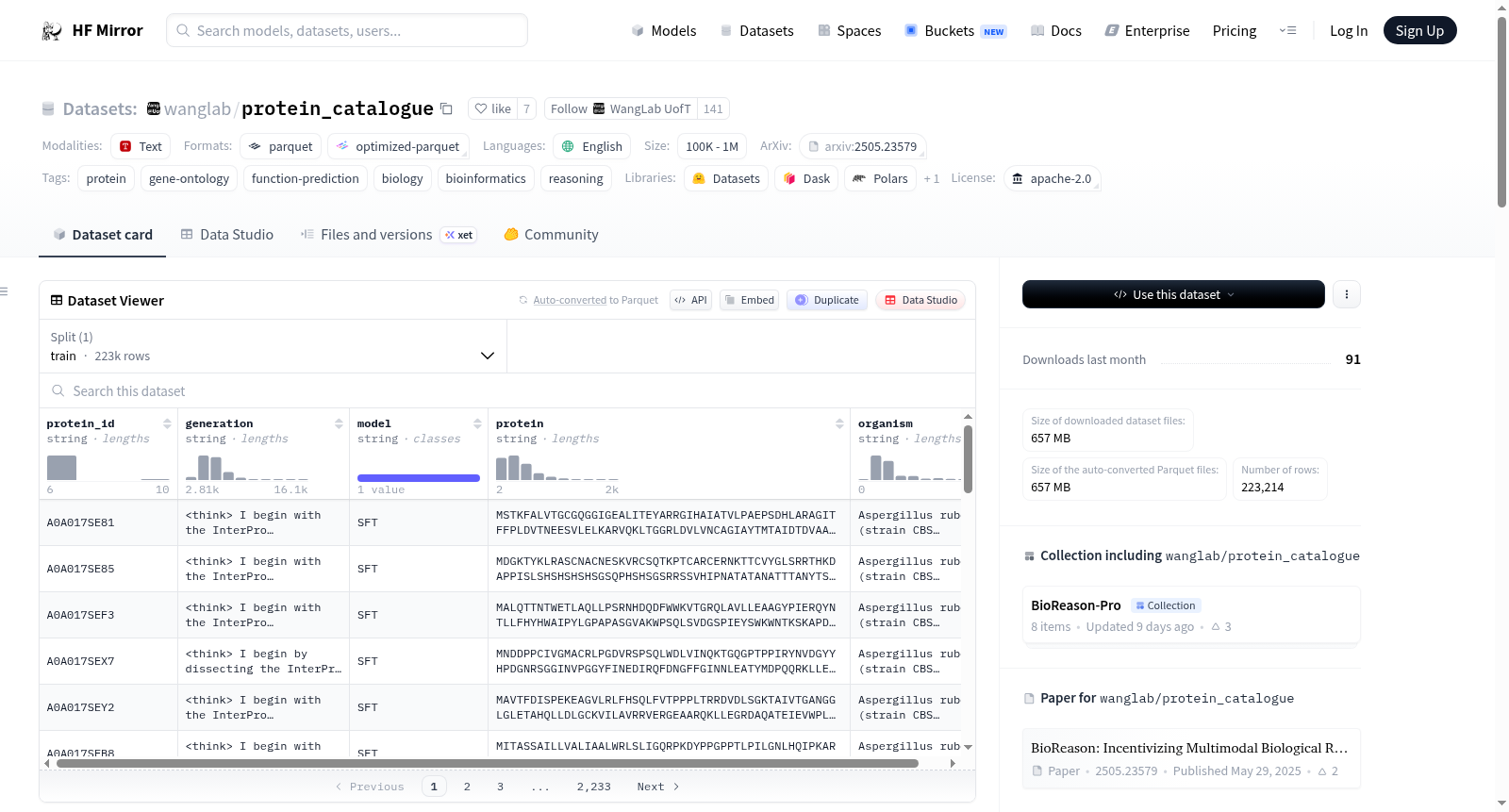
构建方式
在蛋白质功能预测领域,BioReason-Pro Protein Catalogue的构建体现了前沿人工智能技术与生物信息学的深度融合。该数据集通过BioReason-Pro SFT模型对超过22.3万个蛋白质进行了功能注释的预计算生成。其核心构建逻辑在于利用经过监督微调的大型语言模型,为每个蛋白质条目生成包含结构化推理轨迹的综合性描述。模型在处理蛋白质氨基酸序列后,输出一个整合了详细生物学推理、功能摘要、UniProt风格总结、InterPro结构域注释以及跨分子功能、生物过程和细胞组分的基因本体术语预测的完整记录,从而形成了一套系统化的蛋白质功能知识库。
使用方法
研究人员可通过Hugging Face的`datasets`库便捷地加载和探索这一资源。使用`load_dataset`函数并指定数据集名称与分割,即可将整个蛋白质目录载入为结构化的数据对象,便于进行批量分析或单个案例的深入审视。该数据集可直接用于评估蛋白质功能预测模型的性能,作为高质量的先验知识库辅助下游生物学研究,或作为训练数据进一步微调专注于生物推理的模型。其标准化的输出格式确保了与现有生物信息学工作流的兼容性,支持从大规模统计分析到特定蛋白质功能机制探究的多种应用场景。
背景与挑战
背景概述
蛋白质功能预测是生物信息学领域的核心挑战之一,旨在从氨基酸序列推断蛋白质的生物学角色。BioReason-Pro Protein Catalogue数据集由Wang实验室于2026年发布,基于BioReason-Pro SFT模型生成,为超过22.3万种蛋白质提供了预计算的功能注释。该数据集整合了结构化推理轨迹、功能摘要、UniProt摘要、InterPro结构域注释以及基因本体(GO)术语预测,覆盖分子功能、生物过程和细胞组分等多个维度。其构建依托于多模态生物推理框架,旨在通过大规模语言模型提升蛋白质功能注释的准确性与可解释性,为系统生物学和计算蛋白质组学研究提供了重要资源。
当前挑战
在蛋白质功能预测领域,主要挑战在于如何从序列信息中准确推断复杂且多层次的功能注释,尤其是对于功能未知或结构保守性低的蛋白质。BioReason-Pro Protein Catalogue的构建过程面临多重困难:一是需要处理海量且异构的蛋白质序列数据,确保注释的全面性与一致性;二是模型需融合跨模态生物知识,如结构域特征与本体论术语,以生成可靠的结构化推理轨迹;三是验证生成的注释与实验证据的吻合度,避免因模型幻觉引入错误信息。这些挑战凸显了将人工智能系统应用于高精度生物数据注释时所涉及的严谨性与复杂性。
常用场景
经典使用场景
在蛋白质功能预测领域,BioReason-Pro Protein Catalogue数据集为研究人员提供了超过22.3万种蛋白质的预计算功能注释。该数据集通过整合结构化的推理轨迹、功能摘要以及基因本体(GO)术语预测,为蛋白质功能的大规模自动化注释奠定了坚实基础。其经典使用场景在于支持生物信息学中的蛋白质功能推断任务,研究人员可基于此数据集训练或评估机器学习模型,从而系统性地探索蛋白质序列与功能之间的复杂关联。
解决学术问题
该数据集有效应对了蛋白质功能注释中面临的高通量数据解析难题。传统实验方法耗时且成本高昂,而计算预测方法往往缺乏可解释的推理过程。BioReason-Pro通过提供包含详细推理轨迹的注释,不仅提升了预测的准确性,还增强了结果的可解释性,为理解蛋白质在分子功能、生物过程和细胞组件层面的作用机制提供了关键见解,推动了计算生物学中可解释人工智能的发展。
实际应用
在实际应用中,该数据集为药物发现和精准医疗提供了重要支持。生物医学研究人员可以利用其全面的蛋白质功能注释,快速识别与疾病相关的潜在靶点蛋白,加速新药研发的早期筛选过程。此外,在合成生物学和酶工程领域,该数据集有助于工程师根据功能预测结果设计或改造具有特定催化活性的蛋白质,优化工业生物催化过程。
数据集最近研究
最新研究方向
在蛋白质功能预测领域,BioReason-Pro Protein Catalogue数据集正推动着基于多模态生物推理的前沿探索。该数据集整合了超过22.3万种蛋白质的结构化推理轨迹与功能注释,其核心价值在于将大语言模型的推理能力与基因本体论等传统生物知识深度融合。当前研究热点聚焦于利用此类富含推理过程的数据,训练能够模拟生物学家逻辑思维的蛋白质功能注释模型,从而突破传统黑箱预测方法的局限。这一方向不仅加速了未知蛋白质的功能解析,也为理解蛋白质在复杂生物网络中的角色提供了可解释的认知框架,标志着计算生物学正从单纯的数据驱动迈向推理增强的新范式。
以上内容由遇见数据集搜集并总结生成


