translations
收藏Hugging Face2026-05-20 更新2026-05-21 收录
下载链接:
https://huggingface.co/datasets/natgillin/translations
下载链接
链接失效反馈官方服务:
资源简介:
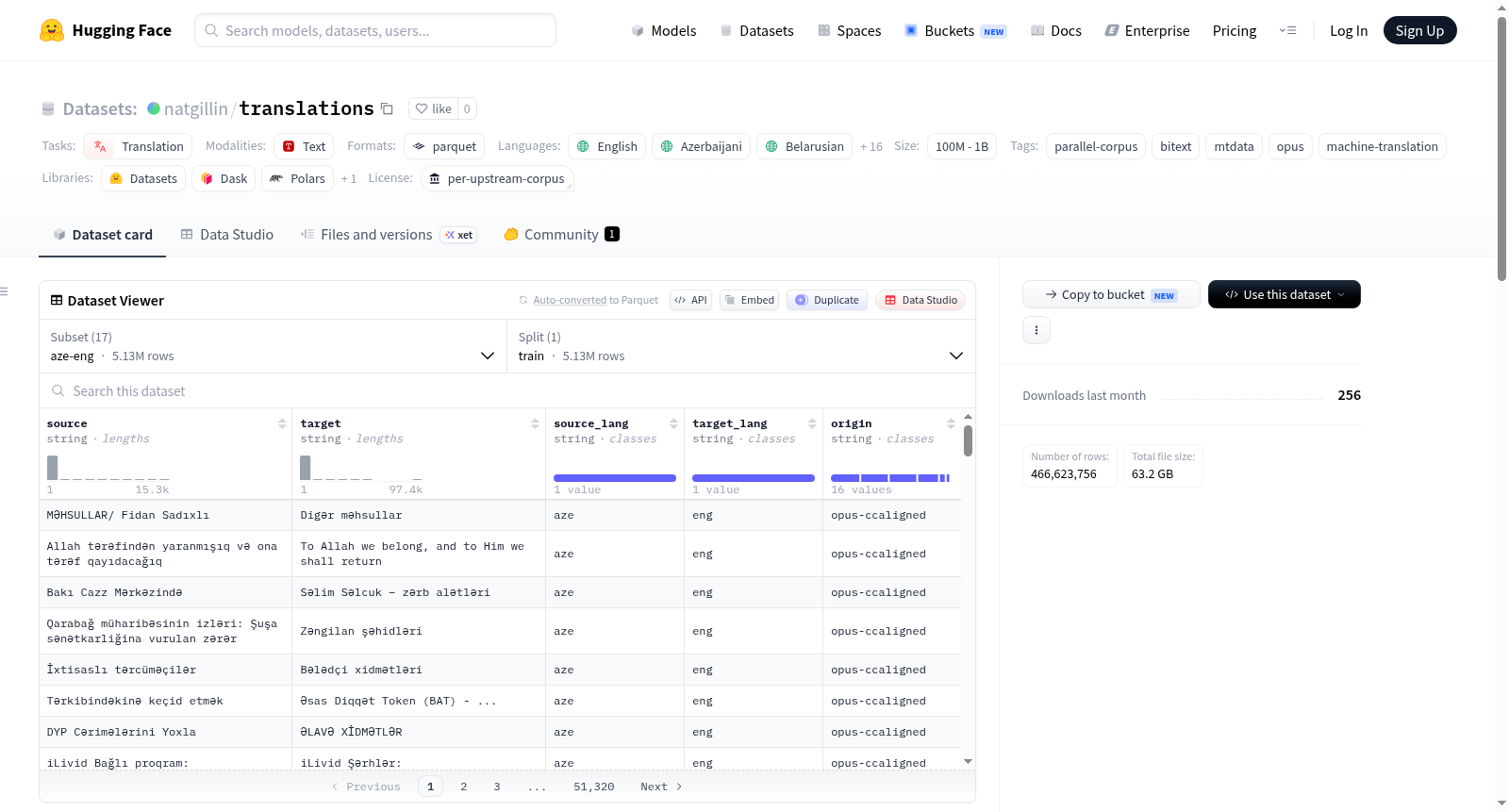
Translations 是一个平行双语语料库,专为机器翻译任务设计,采用Parquet格式,从上游mtdata和OPUS版本汇编而成。该数据集覆盖英语与多种语言(如阿塞拜疆语、白俄罗斯语、保加利亚语、加泰罗尼亚语、丹麦语、爱沙尼亚语、芬兰语、古吉拉特语、匈牙利语、卡纳达语、马拉雅拉姆语、挪威语、奥里亚语、旁遮普语、罗马尼亚语、斯洛伐克语、泰米尔语、乌尔都语)之间的翻译对,数据规模在1亿至10亿个token之间。数据以语言对为单位组织,每个语言对(例如aze-eng, bel-eng)对应一个配置,包含训练集文件。每个数据样本包含五个字段:源语言句子(source)、目标语言句子(target)、源语言代码(source_lang,ISO 639-3)、目标语言代码(target_lang,ISO 639-3)以及标识上游具体子语料来源的origin字段(例如opus-ccmatrix, opus-nllb, mtdata-merged等)。源语言和目标语言的顺序根据其ISO 639-3代码按字母顺序固定,以确保数据对的一致性和明确性。数据集遵循其上游OPUS来源的各自许可证。
Translations is a parallel bilingual corpus designed for machine translation tasks, compiled from upstream mtdata and OPUS versions in Parquet format. The dataset covers translation pairs between English and various languages (such as Azerbaijani, Belarusian, Bulgarian, Catalan, Danish, Estonian, Finnish, Gujarati, Hungarian, Kannada, Malayalam, Norwegian, Odia, Punjabi, Romanian, Slovak, Tamil, Urdu), with data size ranging from 100 million to 1 billion tokens. The data is organized by language pair, with each pair (e.g., aze-eng, bel-eng) corresponding to a configuration that includes training set files. Each data sample contains five fields: source language sentence (source), target language sentence (target), source language code (source_lang, ISO 639-3), target language code (target_lang, ISO 639-3), and an origin field identifying the upstream specific sub-corpus source (e.g., opus-ccmatrix, opus-nllb, mtdata-merged). The order of source and target languages is fixed alphabetically based on their ISO 639-3 codes to ensure consistency and clarity of data pairs. The dataset follows the respective licenses of its upstream OPUS sources.
创建时间:
2026-05-18
原始信息汇总
数据集概述
数据集名称:natgillin/translations
地址:https://huggingface.co/datasets/natgillin/translations
许可证:其他(遵循上游语料库的许可条款,关联 OPUS 来源许可)
任务与语言
- 任务类型:翻译(Translation)
- 支持语言:
- 源语言(19种):英语(en)、阿塞拜疆语(az)、白俄罗斯语(be)、保加利亚语(bg)、加泰罗尼亚语(ca)、丹麦语(da)、爱沙尼亚语(et)、芬兰语(fi)、古吉拉特语(gu)、匈牙利语(hu)、卡纳达语(kn)、马拉雅拉姆语(ml)、挪威语(no)、奥里亚语(or)、旁遮普语(pa)、罗马尼亚语(ro)、斯洛伐克语(sk)、泰米尔语(ta)、乌尔都语(ur)
- 数据配对方向:所有配对均按 ISO 639-3 代码的字母顺序固定方向(例如
bel在eng之前,cat在eng之前),确保配对名称确定性且双向连接无歧义。
数据集规模
- 大小类别:100M < n < 1B 条记录
数据构成与模式
- 列结构:
| 列名 | 类型 | 描述 |
|---|---|---|
source |
字符串 | 源语言句子 |
target |
字符串 | 目标语言句子 |
source_lang |
字符串 | 源语言,ISO 639-3 三位字母代码(如 bel, cat, eng) |
target_lang |
字符串 | 目标语言,ISO 639-3 三位字母代码 |
origin |
字符串 | 上游子语料库标识(如 opus-ccmatrix, opus-nllb, mtdata-merged 等) |
- 文件格式:Parquet
- 数据分割:所有语言配对均固定为
train拆分,避免自动检测测试拆分。
配置与布局
-
配置方式:每个语言对对应一个配置(config),配置名称如
aze-eng、bel-eng等。共包含 17 个配置:aze-eng(阿塞拜疆语-英语)bel-eng(白俄罗斯语-英语)bul-eng(保加利亚语-英语)cat-eng(加泰罗尼亚语-英语)dan-eng(丹麦语-英语)eng-est(英语-爱沙尼亚语)eng-fin(英语-芬兰语)eng-guj(英语-古吉拉特语)eng-hun(英语-匈牙利语)eng-kan(英语-卡纳达语)eng-mal(英语-马拉雅拉姆语)eng-ori(英语-奥里亚语)eng-pan(英语-旁遮普语)eng-ron(英语-罗马尼亚语)eng-slk(英语-斯洛伐克语)eng-tam(英语-泰米尔语)eng-urd(英语-乌尔都语)
-
文件目录结构示例:
data/ cat-eng/ opus-ccmatrix-00000-of-00200.parquet opus-nllb-00000-of-00200.parquet ... bel-eng/ ...
数据来源
- 上游来源:由 mtdata / OPUS 发布的双语平行语料库汇编而成。
origin列常见值:mtdata-merged— mtdata 为配对去重合并的双语文本opus-<source>— 上游 OPUS 子语料库(如opus-ccmatrix、opus-nllb、opus-ccaligned、opus-multiccaligned、opus-wikimatrix、opus-eubookshop、opus-kde4、opus-gnome、opus-neulab-tedtalks、opus-elrc-*、opus-tatoeba、opus-ted2020等)elr— ELRA / ELR 特定片段unknown— 无法匹配已知 OPUS 模式的 URL 行
许可证与引用
- 许可证:继承自上游 OPUS 来源的语料库许可条款。
- 引用要求:引用 OPUS 原始来源(https://opus.nlpl.eu)。
搜集汇总
数据集介绍
构建方式
Translations数据集是机器翻译与自然语言处理领域的重要资源,专注于多语言平行语料的整合。该数据集从mtdata和OPUS项目中收集了经过校验的平行句对,以Parquet格式存储,确保高效的数据读取与处理。每一配置对应一个语言对,源语言和目标语言按ISO 639-3字母顺序固定排序,消除方向歧义。数据集的构建采用了子语料库层面去重和合并策略,并通过一个名为origin的列标识每行数据的上游来源,如opus-ccmatrix或mtdata-merged,所有语料对均统一标注为训练集,避免测试集子串干扰。
特点
该数据集涵盖18个语言对,包括阿塞拜疆语、白俄罗斯语、加泰罗尼亚语等较小语种,与英语组成双向翻译语料。其显著特点在于规模庞大,样本数量介于1亿至10亿之间,且来源丰富,整合了包括OPUS内部多个子语料库及ELRA资源的语料。通过Parquet格式和行级origin列的设计,数据集在保持结构简洁的同时保留了语料的溯源信息,便于科研人员追溯数据来源和进行跨语料库分析,为低资源语言机器翻译研究提供了坚实基础。
使用方法
研究者可通过HuggingFace Datasets库便捷加载Translations数据集,指定对应语言对的配置名称如aze-eng来获取特定语料。加载后数据以标准的训练集形式呈现,每个样本包含source、target、source_lang、target_lang及origin五个字段,可直接用于训练序列到序列模型。建议在训练前根据origin字段筛选所需子语料库,或进行语言方向验证。由于数据已预处理为统一格式,适合快速集成到机器翻译或跨语言自然语言处理任务的数据流中,支持大规模分布式训练场景。
背景与挑战
背景概述
机器翻译作为自然语言处理领域的核心任务,其性能高度依赖于大规模、高质量的双语平行语料资源。Translations数据集由研究机构基于上游mtdata与OPUS项目发布构建,囊括了涵盖阿塞拜疆语、白俄罗斯语、加泰罗尼亚语、古吉拉特语、泰米尔语等多种语言对的平行语料,规模介于1亿至10亿句对之间。该数据集通过整合OPUS多子语料库(如CCMatrix、NLLB、WikiMatrix等)及ELRC资源,为低资源语言翻译、跨语言迁移学习及鲁棒性模型训练提供了关键数据支撑,有效缓解了平行语料稀缺对研究进展的制约。其系统性聚合与标准化格式促进了机器翻译领域的可复现研究,对推动多语言NLP系统的实用化部署具有深远影响。
当前挑战
Translations数据集致力于解决机器翻译中平行语料覆盖不均与质量参差的领域难题。低资源语言(如奥里亚语、旁遮普语)的语料极度匮乏,依赖OPUS子语料库合并后仍面临噪声与重复问题,需通过mtdata的融合去重算法进行初步清理。在构建过程中,数据集面临子语料来源杂糅(如多OPUS子集、ELRC及未知源头)导致的数据一致性挑战,需以行级‘origin’列标注溯源以支持质量筛选。源语言与目标语言的固定排序(按ISO 639-3代码)虽确保了确定性,但部分语对因未分割训练/测试集而需研究者自行划分,且子语料中混杂的测试样本(如ELRC中的`-test-`文件名)可能干扰模型评估。此外,继承自上游的分散性许可条款亦为商用或二次分发带来合规复杂性与伦理约束。
常用场景
经典使用场景
在神经机器翻译领域,Translations数据集汇聚了来自OPUS与mtdata等上游语料库的海量平行语料,涵盖了从阿塞拜疆语到乌尔都语等数十种低资源语言与英语之间的双向翻译对。其经典使用场景在于为跨语言神经翻译模型的训练提供大规模、去重且来源可追溯的平行语料库。研究者可依据ISO 639-3语言代码确定性地构建双语数据,并利用行级标注的'origin'字段区分不同子语料来源,从而灵活地组合或筛选训练数据,以提升模型在特定领域或低资源语言对上的翻译性能。
实际应用
在实际应用中,Translations数据集可直接支撑多语种翻译引擎的研发与迭代,尤其适用于需要覆盖东欧、南亚及中亚等地区语言的企业级产品。例如,电商平台的商品信息自动翻译、多语言客服系统中的实时转译,以及跨国通讯软件的消息本地化等功能,均可依托于此数据集训练的模型得以高效实现。同时,数据集的来源可追溯性也便于开发者根据下游任务需求进行定制化的数据修剪与增强,从而在法律文件、医疗文本等专业领域生成更精准的译文。
衍生相关工作
该数据集的构建方式启发了多项后续工作。在语料获取方面,研究者基于其'origin'字段的溯源机制,开发出针对OPUS多来源语料的自动质量评估与噪声过滤工具,如CometQE驱动的数据筛选流水线。在模型训练方面,Translatrons数据集被用作基线与验证集,催生了面向低资源语言对的稀疏专家混合模型以及基于对比学习的跨语言表示对齐方法。此外,数据集提供的标准配置格式也促使了统一的多语言翻译基准评估框架(如FLORES-200评估集的配套训练数据规范)的建立。
以上内容由遇见数据集搜集并总结生成


