apertus-posttrain-rumansh
收藏Hugging Face2025-08-31 更新2025-09-01 收录
下载链接:
https://huggingface.co/datasets/swiss-ai/apertus-posttrain-rumansh
下载链接
链接失效反馈官方服务:
资源简介:
罗马什语监督微调分割数据集,包含词典列表翻译、句子级翻译、习语识别以及人工翻译的罗马什指令。
创建时间:
2025-08-27
原始信息汇总
Romansh SFT 数据集概述
基本信息
- 许可证:CC BY 4.0
- 类型:监督微调(SFT)数据集
- 来源:基于 swiss-ai/apertus-pretrain-rumansh 语料库构建
数据构成
1. 词典列表翻译
- 来源:Pledarigrond 词典(由 Lia Rumantscha 提供)
- 涵盖方言:Sursilvan、Sutsilvan、Surmiran、Rumantsch Grischun
- 格式:提示-答案对
- 数据量:
- Rumantsch Grischun:14,264 条
- Surmiran:7,486 条
- Sursilvan:1,352 条
- Sutsilvan:5,854 条
2. 方言识别
- 来源:La Quotidiana 公开文本
- 任务:单标签分类
- 数据量:16,322 条
- 方言分布:
- RG:3,000 条
- Sursilvan:3,000 条
- Surmiran:3,000 条
- Vallader:3,000 条
- Puter:3,000 条
- Sutsilvan:1,322 条
3. 句子级翻译
- 类型:
- 人工翻译:139 条(来自 Tülü 数据集)
- 合成翻译:经过质量过滤
- 语言对:
- 德语 ↔ 各罗曼什方言
- 多语言(英、法、意)↔ Rumantsch Grischun
- 数据量:1,506 条
质量保证
- 对齐方法:使用 SentenceTransformers 进行双向对齐
- 相似度阈值:余弦相似度 ≥ 0.65
- 质量评估:使用 Qwen2-32B-Instruct 进行评分(仅保留评分 ≥ 7 的翻译)
数据统计
总数据量:约 47,000 条训练样本
致谢
- 志愿者翻译:特别感谢 Donat D.、Lea B. 和 Madlaina F.
- 奖金支持:Antoine Bosselut 教授(350 瑞士法郎)
- 组织:Swiss AI Initiative
搜集汇总
数据集介绍
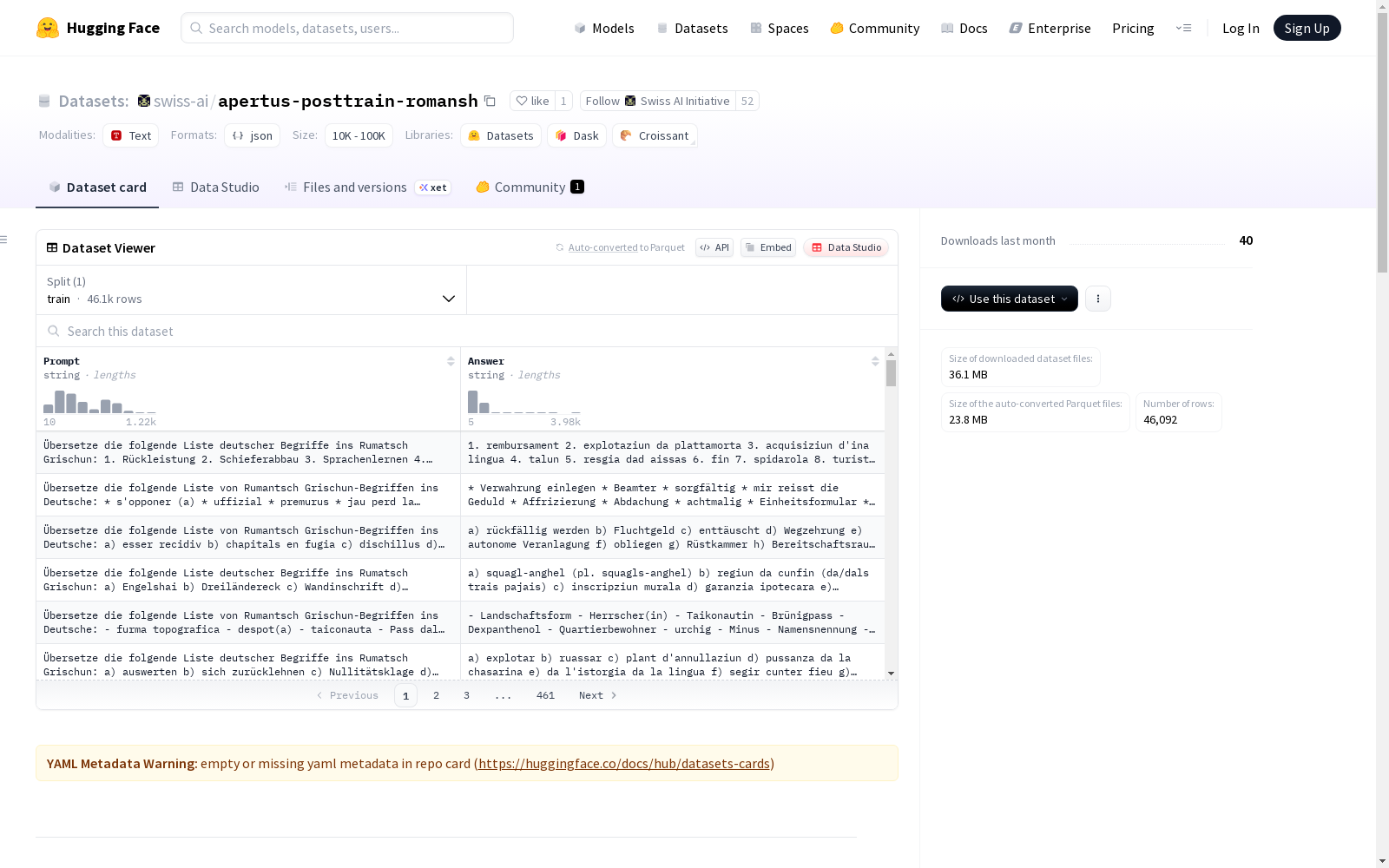
构建方式
在罗曼什语自然语言处理领域,apertus-posttrain-rumansh数据集通过多源数据融合构建而成。其核心组成部分包括从Pledarigrond词典提取的术语翻译对、基于La Quotidiana公开文本的方言分类数据,以及由志愿者人工翻译的指令数据。词典部分采用双向提示-答案配对架构,方言识别通过模板化提示实现,而机器翻译数据则经过严格的跨语言对齐和质量筛选流程,确保数据的准确性与一致性。
特点
该数据集最显著的特征在于其多维度语言覆盖与高质量标注体系。它不仅涵盖罗曼什语的五种主要方言变体(Sursilvan、Sutsilvan、Surmiran、Vallader、Puter)及标准语Rumantsch Grischun,还包含德罗双语词典列表、句子级翻译和方言分类任务。特别值得注意的是,数据集采用了混合数据来源策略,既包含人工精译的指令数据,也融合了经过神经网络严格筛选的合成翻译数据,其中所有翻译结果均经过Qwen2-32B-Instruct模型的质量评估,仅保留评分≥7的高质量样本。
使用方法
对于研究者而言,该数据集可直接应用于罗曼什语监督微调任务。各子文件按任务类型和语言方向进行组织,使用者可根据需要加载特定JSONL文件进行模型训练。词典翻译数据适用于构建双向翻译模型,方言识别数据可用于训练分类器,而人工翻译指令数据则适合用于指令微调场景。在预处理过程中,建议遵循原始提示模板格式,并注意不同方言变体的数据分布差异,以确保模型训练的均衡性和有效性。
背景与挑战
背景概述
罗曼什语作为瑞士四种官方语言中最弱势的一种,其数字资源长期匮乏。2023年由瑞士人工智能倡议组织联合洛桑联邦理工学院发起的Apertus项目,旨在构建首个大规模罗曼什语监督微调数据集。该项目依托《Pledarigrond》权威词典和《La Quotidiana》报刊语料,涵盖五种方言变体(罗曼什格劳宾登语、苏尔塞尔瓦语、苏齐尔瓦语、苏米尔瓦语、瓦拉德尔语),通过词典翻译、句式对齐和方言分类等多任务架构,为低资源语言的自然语言处理提供了重要基准。
当前挑战
该数据集面临双重挑战:在领域问题层面,需解决低资源语言机器翻译中方言变体歧义消除、语码混合现象处理以及跨语言语义对齐精度提升等核心难题;在构建过程中,遭遇方言注音符号标准化缺失、双语平行语料稀缺导致神经网络对齐困难,以及人工翻译质量控制等系统性障碍,需通过多层级相似度过滤和混合专家评估机制予以克服。
常用场景
经典使用场景
在罗曼什语自然语言处理研究中,该数据集通过监督微调任务支持多方言机器翻译系统的开发。其词典列表翻译模块为德语与四种罗曼什方言(Sursilvan、Sutsilvan、Surmiran、Rumantsch Grischun)提供双向对齐语料,而习语识别模块则能训练方言分类器,有效解决低资源语言处理中的标注数据稀缺问题。
实际应用
在实际应用层面,该数据集支撑了瑞士多语种公共服务系统的语言技术开发,例如政府文件的自动方言转换、教育机构的双语教学辅助工具,以及文化旅游领域的实时翻译服务。其高质量的人工翻译指令数据还可用于构建罗曼什语对话助手,提升少数民族语言在数字化时代的应用活力。
衍生相关工作
基于该数据集衍生的经典工作包括罗曼什语多方言神经机器翻译系统、方言特征提取器以及低资源语言质量评估框架。其中采用SentenceTransformers的跨语言对齐方法和Qwen2-32B-Instruct的质量评分机制已被多个濒危语言项目借鉴,形成了低资源语言处理的技术标准范式。
以上内容由遇见数据集搜集并总结生成


